



I. Introduction▲
I-A. Avertissements▲
J'ai essayûˋ de rendre les explications les plus simples possible. Nûˋanmoins, si vous vous faites des migraines en raison de mes explications filandreuses, n'hûˋsitez pas û me contacter, je pourrai alors essayer de clarifier les choses.
Si le code source vous nargue en refusant de fonctionner, essayez de relire les explications. Bien sû£r, vous pouvez toujours me contacter si quelque chose vous semble erronûˋ, mais dans tous les cas, essayez d'expliquer votre dûˋmarche et de joindre le fichier de logs de votre ûˋmulateur.
I-B. Pourquoi ce tutorielô ?▲
Programmer le noyau d'un systû´me d'exploitation est un trû´s bon moyen pour en comprendre le fonctionnement, et c'est dans cette optique que j'ai moi-mûˆme commencûˋ le dûˋveloppement de Pûˋpin.
Ce tutoriel tente de guider le programmeur dans ses premiers pas en dûˋcortiquant la base de la rûˋalisation d'un noyau et en en prûˋsentant les composantes ûˋlûˋmentaires. û chaque fois que les sources d'un nouveau noyau sont proposûˋes en exemple dans un chapitre, j'ai essayûˋ de minimiser le nombre de lignes de code supplûˋmentaire par rapport û celles du chapitre prûˋcûˋdent. Vous pourrez donc utiliser la commande diff pour bien voir les parties modifiûˋes ou ajoutûˋes d'un chapitre û l'autre.
I-C. Prûˋrequis▲
I-C-1. Compûˋtences▲
Une partie du noyau est codûˋe en assembleur i386 et le reste est codûˋ en langage C. La maûÛtrise de ce dernier ainsi que la connaissance des notions de base en assembleur sont donc un prûˋalable û la comprûˋhension de ce tutoriel.
Mûˆme si les notions importantes relatives û l'architecture i386 sont expliquûˋes ici au fur et û mesure, la lecture des documents suivants est fortement recommandûˋe.
Toutes les informations relatives û l'architecture Intel et û certains microcontrûÇleurs sont tûˋlûˋchargeablesô :
Les spûˋcifications permettant d'ûˋcrire un noyau respectant le standard Multibootô :
Concernant le format ELFô :
I-C-2. Outils▲
I-D. Ressources sur le web▲
- Osdev.org, en anglais, mais plein d'explications claires et surtout un forum trû´s actif et de haut niveau sur les systû´mes d'exploitation. û voir absolumentô !
- JamesM's kernel development tutorials
- OS Development Series
Et aussi, pour ceux qui dûˋbutent en administration systû´me, je recommande l'excellentissime Guide du Rootard.
II. Rûˋaliser un secteur de boot qui affiche un message▲
La programmation d'un noyau est difficile et ce tutoriel s'adresse en premier lieu aux programmeurs ayant dûˋjû une bonne expûˋrience de la programmation et une connaissance suffisante de la thûˋorie des systû´mes d'exploitation. L'ensemble des prûˋrequis nûˋcessaires û la bonne comprûˋhension de ce tutoriel est dûˋtaillûˋ dans l'introductionIntroduction. Si vous dûˋbutez en C, que vous ne connaissez pas l'assembleur ou bien que vous n'avez qu'une trû´s faible idûˋe des fonctionnalitûˋs d'un noyau, il vous sera donc trû´s difficile de tout saisir. Quoi qu'il en soit, je vous souhaite une excellente lecture et une bonne compilationô !
II-A. Qu'est-ce qu'un secteur de bootô ?▲
Un secteur de boot est un programme situûˋ sur le premier secteur d'une unitûˋ de stockage, et qui est chargûˋ et exûˋcutûˋ au dûˋmarrage du PC. Le programme de ce secteur a en principe pour tûÂche de charger un noyau en mûˋmoire et de l'exûˋcuter. Ce noyau peut ûˆtre prûˋsent au dûˋpart sur une disquette, un disque dur, une bande ou tout autre support magnûˋtique. Ce chapitre dûˋtaille ce qui se passe quand on boote sur disquette, mais les principes expliquûˋs ici restent valables pour tout autre support.
II-B. Comment est chargûˋ le secteur de boot au dûˋmarrage de l'ordinateurô ?▲
Au dûˋmarrage, le PC commence par initialiser et tester le processeur, la mûˋmoire et les pûˋriphûˋriques. C'est le Power On Self Test (POST). Ensuite, le PC charge et exûˋcute un programme particulier rûˋsidant en ROM, le BIOS (ô¨ô Basic Input/Output Systemô ô£ ou ô¨ô Built In Operating Systemô ô£). Le BIOS peut ûˆtre vu comme un systû´me d'exploitation minimal chargûˋ automatiquement par le PC et dont l'un des rûÇles est de charger un vûˋritable systû´me d'exploitation en essayant de trouver un secteur de boot valide parmi les unitûˋs de stockage. Une fois trouvûˋ, ce secteur est chargûˋ en mûˋmoire û l'adresse 0000:7C00 puis le BIOS passe la main au programme de boot fraûÛchement chargûˋ.
Le secteur de boot de l'unitûˋ de stockage est appelûˋ Master Boot Record (MBR). Il contient des donnûˋes, dont la table des partitions, et du code exûˋcutable. La table des partitions contient des informations sur les partitions primaires du disque (oû¿ elles commencent, leur taille, etc.). Le code exûˋcutable d'un MBR standard cherche sur la table des partitions une partition active, puis, si une telle partition existe, ce code charge le secteur de boot de cette partition (appelûˋ aussi VBR). C'est souvent ce deuxiû´me secteur de boot qui charge le noyau et lui donne la main.
II-C. Crûˋer un secteur de boot qui affiche un message▲
Dans notre cas, nous allons pour commencer crûˋer un secteur de boot trû´s simple qui ne fera qu'afficher un message de bienvenue. Cela n'est pas bien difficile et pour vous ûˋpargner un long suspense, voici le programmeô :
[BITS 16] ô ; indique a Nasm que l'on travaille en 16 bits
[ORG 0x0]
; initialisation des segments en 0x07C00
ô ô mov ax, 0x07C0
ô ô mov ds, ax
ô ô mov es, ax
ô ô mov ax, 0x8000
ô ô mov ss, ax
ô ô mov sp, 0xf000 ô ô ; pile de 0x8F000 -> 0x80000
; affiche un msg
ô ô mov si, msgDebut
ô ô call afficher
end:
ô ô jmp end
;--- Variables ---
ô ô msgDebut db "Hello World !", 13, 10, 0
;-----------------
;---------------------------------------------------------
; Synopsis: Affiche une chaûÛne de caractû´res se terminant par 0x0
; Entrûˋe: ô DS:SI -> pointe sur la chaûÛne û afficher
;---------------------------------------------------------
afficher:
ô ô push ax
ô ô push bx
.debut:
ô ô lodsb ô ô ô ô ; ds:si -> al
ô ô cmp al, 0 ô ô ; fin chaûÛne ?
ô ô jz .fin
ô ô mov ah, 0x0E ô ; appel au service 0x0e, int 0x10 du bios
ô ô mov bx, 0x07 ô ; bx -> attribut, al -> caractû´re ASCII
ô ô int 0x10
ô ô jmp .debut
.fin:
ô ô pop bx
ô ô pop ax
ô ô ret
;--- NOP jusqu'û 510 ---
ô ô times 510-($-$$) db 144
ô ô dw 0xAA55II-D. Que fait exactement ce programmeô ?▲
[BITS 16] indique û Nasm que l'on travaille en 16 bits.
On indique tout d'abord que l'on travaille sur 16 bits pour le codage des instructions et des donnûˋes, c'est le mode par dûˋfaut. Ceci n'est pas encore le dûˋbut du programme, c'est juste une directive de compilation pour que l'exûˋcutable obtenu soit bien sur 16 bits et pas sur 32 bits.
[ORG 0x0] Cette directive indique l'offset û ajouter û toutes les adresses rûˋfûˋrencûˋes.
; initialisation des segments en 0x07C00
ô ô mov ax, 0x07C0
ô ô mov ds, ax
ô ô mov es, axLe programme du secteur de boot est chargûˋ par le BIOS en 0x7C00, donc toutes les donnûˋes internes au programme sont situûˋes û partir de cette adresse. Le bloc ci-dessus initialise les registres ds et es qui servent û indiquer oû¿ dûˋbute le segment de donnûˋes. En mettant la valeur 0x7C00 dans le sûˋlecteur de donnûˋes, on accû´de en fait û l'adresse 0x07C0:0000 = 0x07C00.
L'adressage en mode rûˋel est particulier. La valeur du sûˋlecteur reprûˋsente les 16 bits ô¨ô hautsô ô£ d'une adresse linûˋaire sur 20 bits. Il faut donc multiplier par 0x10 (par 16 en dûˋcimal) la valeur du sûˋlecteur pour obtenir la base. Par exemple, l'adresse A000:1234 en mode rûˋel correspond û l'adresse physique A0000 + 1234 = A1234. Cela signifie aussi qu'un segment en mode rûˋel occupe 64ô k, et pas un octet de plusô !
; pile de 0x8F000 -> 0x80000
ô ô mov ax, 0x8000
ô ô mov ss, ax
ô ô mov sp, 0xf000Ensuite on initialise le segment de pile SS et le pointeur de pile SP en faisant commencer la pile en 0x8F000 et en la faisant finir en 0x80000. Noteô : le choix de ces valeurs est arbitraire, dans le cas prûˋsent, la pile aurait pu ûˆtre placûˋe ailleurs.
û ce stade du programmeô :
- le secteur de boot est chargûˋ en 0x07C00
- le segment de donnûˋes est initialisûˋ pour couvrir les adresses de 0x07C00 û 0x17C00
- la pile commence en 0x8F000 et finit en 0x80000.
|
|
; affiche un msg
ô ô mov si,msgDebut
ô ô call afficherUne fois les principaux registres initialisûˋs, la fonction afficher est appelûˋe pour mettre û l'ûˋcran le message pointûˋ par msgDebut. Cette fonction fait appel au BIOS pour gûˋrer l'affichage du message. Plus prûˋcisûˋment, elle appelle le service 0x0e de l'interruption logicielle 0x10 du BIOS qui permet d'afficher un caractû´re û l'ûˋcran en prûˋcisant ses attributs (couleur, luminositûˋãÎ). Il aurait ûˋtûˋ possible d'ûˋcrire ce message û l'ûˋcran en se passant de cette facilitûˋ offerte par le BIOS, mais cela aurait ûˋtûˋ beaucoup moins simple û rûˋaliser (c'est d'ailleurs l'objet du chapitre suivantãÎ patienceô !).
end:
ô ô jmp endUne fois le message affichûˋ, le programme boucle et ne fait plus rien.
msgDebut db "Hello world !", 13, 10, 0En fin de fichier, on dûˋfinit les variables et les fonctions utilisûˋes dans le programme. La chaûÛne de caractû´res affichûˋe au dûˋmarrage a pour nom msgDebut.
Ensuite, la fonction afficher est dûˋfinie. Elle prend en argument une chaûÛne de caractû´res pointûˋe par les registres DS et SI. DS correspond û l'adresse du segment de donnûˋes et SI est un dûˋplacement par rapport au dûˋbut de ce segment (un offset). La chaûÛne de caractû´res passûˋe en argument doit se terminer par un octet ûˋgal û 0 (comme en C).
;--- NOP jusqu'û 510 ---
ô ô times 510-($-$$) db 144
ô ô dw 0xAA55Cette directive ajoute du bourrage sous forme d'instructions NOP (opcode 0x90, ou 144), puis le mot 0xAA55 û la fin du code compilûˋ afin que le binaire gûˋnûˋrûˋ fasse 512 octets. Le mot 0xAA55 est crucialô : en fin de secteur, il est une signature pour indiquer au BIOS que le secteur en question est un MBRô !
II-E. Compiler et tester le programme▲
Le programme est ûˋcrit dans le fichier bootsect.asm. Pour le compiler avec Nasm et obtenir le binaire (exûˋcutable au boot) bootsect, il faut utiliser la commande suivanteô :
nasm -f bin -o bootsect bootsect.asmEnsuite, pour tester notre secteur de boot, nous pourrions l'ûˋcrire sur une disquette et rebooter notre machine prûˋfûˋrûˋe avec la disquette dedans. Mais cette dûˋmarche est trû´s fastidieuse, car un PC met toujours du temps û rebooter et les possibilitûˋs de dûˋbogage sont trû´s limitûˋes û ce stade. Heureusement, il existe de trû´s bons ûˋmulateurs de PC, tels que Bochs ou qemu. Pour ma part, j'utilise Bochs qui, contrairement û qemu, possû´de un mode debug puissant.
Bochs a la possibilitûˋ d'utiliser un fichier en faisant comme si c'ûˋtait une vraie disquette. Sous Unix, pour gûˋnûˋrer une image de disquetteô :
cat bootsect /dev/zero | dd of=floppyA bs=512 count=2880Je ne sais pas trop comment tout cela peut ûˆtre fait sous Windows (je ne travaille que sous Debian GNU/Linux). En revanche, vous trouverez d'autres dûˋveloppeurs Windows sur l'excellent forum Osdev.org.
Ensuite, la commande pour dûˋmarrer sur cette disquette virtuelle avec Bochs devrait ressembler û ûÏaô :
bochs 'boot:a' 'floppya: 1_44=floppyA, status=inserted'Il est assez peu probable que Bochs fonctionne du premier coup si vous ne vous ûˆtes pas donnûˋ la peine de lire sa documentation pour crûˋer un fichier de configuration qui lui soit intelligible. Je sais, ûÏa n'est pas la partie la plus passionnante, mais elle est hûˋlas indispensableô !
Pour ceux qui prûˋfû´rent utiliser qemu, il faut taper la commande suivanteô :
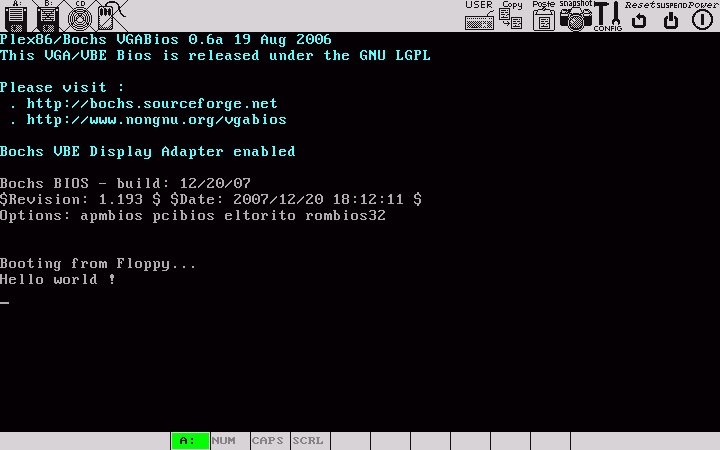
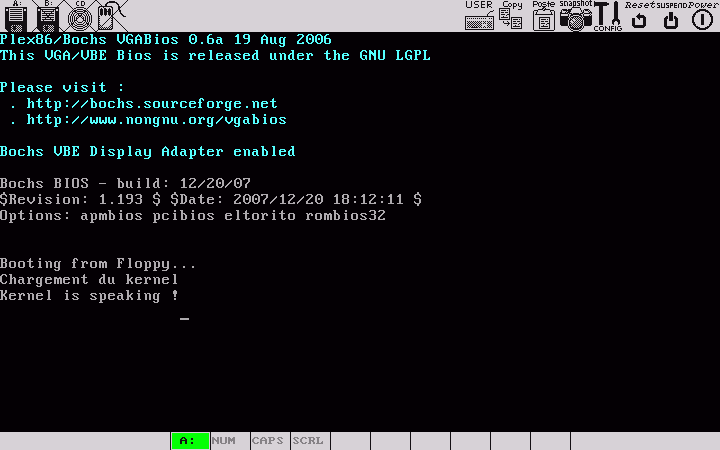
qemu -boot a -fda floppyALe rûˋsultat obtenu avec Bochsô :
|
|
III. Rûˋaliser un secteur de boot qui charge et exûˋcute un noyau▲
- Le programme du boot loaderLe programme du boot loader
- Organiser la mûˋmoireOrganiser la mûˋmoire
- Un premier noyauUn premier noyau
- Compiler et tester le boot loader et le noyauCompiler et tester le boot loader et le noyau
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : bootsect.tgz.
III-A. Le programme du boot loader▲
La partie prûˋcûˋdente explique par l'exemple les principes de fonctionnement d'un programme de boot. Dans cette partie, nous allons voir un programme de boot plus raffinûˋ qui, aprû´s avoir affichûˋ un message, charge en mûˋmoire un noyau trû´s rudimentaire et lui passe la main. Lû encore, nous allons faire au plus simple et le noyau se contentera seulement d'afficher un message.
Ce programme ressemble beaucoup û celui du chapitre prûˋcûˋdent. En fait, c'est le mûˆme avec juste quelques lignes de code en plus qui copient une partie de la disquette, contenant le noyau, en mûˋmoireô :
?fine BASE ô 0x100 ô ; 0x0100:0x0 = 0x1000
?fine KSIZE ô 1 ô ; nombre de secteurs de 512 octets û charger
[BITS 16]
[ORG 0x0]
jmp start
%include "UTIL.INC"
start:
; initialisation des segments en 0x07C0
ô ô mov ax, 0x07C0
ô ô mov ds, ax
ô ô mov es, ax
ô ô mov ax, 0x8000 ô ; stack en 0xFFFF
ô ô mov ss, ax
ô ô mov sp, 0xf000
; rûˋcupûˋration de l'unitûˋ de boot
ô ô mov [bootdrv], dl ô
; affiche un msg
ô ô mov si, msgDebut
ô ô call afficher
; charger le noyau
ô ô xor ax, ax
ô ô int 0x13
ô ô push es
ô ô mov ax, BASE
ô ô mov es, ax
ô ô mov bx, 0
ô ô mov ah, 2
ô ô mov al, KSIZE
ô ô mov ch, 0
ô ô mov cl, 2
ô ô mov dh, 0
ô ô mov dl, [bootdrv]
ô ô int 0x13
ô ô pop es
; saut vers le kernel
ô ô jmp dword BASE:0
msgDebut: db "Chargement du kernel", 13, 10, 0
bootdrv: db 0
;; NOP jusqu'û 510
times 510-($-$$) db 144
dw 0xAA55III-A-1. Que fait exactement ce programmeô ?▲
jmp start
ô ô %include "UTIL.INC"
ô ô start:Le programme commence par un saut û l'adresse start. La directive include ajoute au code du noyau le contenu du fichier UTIL.INC qui contient le code de la fonction afficher vue prûˋcûˋdemment.
; rûˋcupûˋration de l'unitûˋ de boot
ô ô mov [bootdrv], dlCette instruction met dans une variable un nombre servant û identifier le pûˋriphûˋrique de boot (ici le lecteur de disquettes). Cette variable sera rûˋutilisûˋe plus tard pour indiquer û partir de quel pûˋriphûˋrique doit ûˆtre chargûˋ le noyau.
; charger le noyau
ô ô xor ax, ax
ô ô int 0x13
ô ô push es
ô ô mov ax, BASE
ô ô mov es, ax
ô ô mov bx, 0
ô ô mov ah, 2
ô ô mov al, KSIZE
ô ô mov ch, 0
ô ô mov cl, 2
ô ô mov dh, 0
ô ô mov dl, [bootdrv]
ô ô int 0x13
ô ô pop esLe bout de code ci-dessus charge le noyau en mûˋmoire en faisant appel û l'interruption 0x13 du BIOS qui permet de copier un ou plusieurs secteurs d'une disquette en mûˋmoire. Dans notre cas, le noyau se situe au dûˋbut du second secteur de la disquette et le programme recopie ce secteur û l'adresse 0x1000 en RAM. Notez que le choix de cette adresse est arbitraire et on aurait trû´s bien pu choisir une autre valeur.
L'adresse physique 0x1000 est adressûˋe ici en mettant le sûˋlecteur û 0x0100. Mais on aurait trû´s bien pu procûˋder autrement, en utilisant un sûˋlecteur û 0 et un offset de 0x1000, ûÏa aurait aussi fonctionnûˋô !
La variable KSIZE dûˋfinit le nombre de secteurs û charger pour que tout le noyau soit bien recopiûˋ en mûˋmoire. Ce premier noyau, qui est dûˋcrit dans la partie suivante, est trû´s court (pas plus de 100 octets). On peut donc se contenter de mettre la valeur de KSIZE û 1 pour copier un seul secteur.
; saut vers le noyau
ô ô jmp dword BASE:0Ensuite, une instruction de saut donne la main au code du noyau.
III-B. Organiser la mûˋmoire▲
Programmer un secteur de boot et un noyau, cela signifie entre autres organiser l'occupation en mûˋmoire des diffûˋrents composants. Pour ne pas vous y perdre, je vous conseille d'utiliser des petits schûˋmas. Les 5 minutes passûˋes û crayonner sur un bout de papier vous feront parfois ûˋconomiser des heures de dûˋbogageô ! Dans notre cas, la mûˋmoire est occupûˋe de la faûÏon suivante aprû´s le chargement du noyauô :
|
|
III-C. Un premier noyau▲
Voici le programme du noyauô :
[BITS 16]
[ORG 0x0]
jmp start
%include "UTIL.INC"
start:
; initialisation des segments en 0x100
ô ô mov ax, 0x100
ô ô mov ds, ax
ô ô mov es, ax
; initialisation du segment de pile
ô ô mov ax, 0x8000
ô ô mov ss, ax
ô ô mov sp, 0xf000
; affiche un msg
ô ô mov si, msg00
ô ô call afficher
end:
ô ô jmp end
msg00: db 'Kernel is speaking !', 10, 0Ce programme initialise le registre de code et les registres de donnûˋes afin qu'ils pointent sur la bonne zone mûˋmoire, en 0x1000. Ensuite, un message est affichûˋ pour attester de la rûˋussite des opûˋrations. û la ligne suivante, le noyau ne fait vraiment pas grand-choseô : il boucle indûˋfiniment.
III-D. Compiler et tester le boot loader et le noyau▲
Le package contenant les sources est tûˋlûˋchargeable iciô : bootsect.tgz.
Le code se dûˋcompose enô :
- un fichier bibliothû´que, UTIL.INC, qui contient la fonction afficherô ;
- un fichier qui contient le code du secteur de bootô ;
- un fichier qui contient le code du noyau.
$ ls
UTIL.INC bootsect.asm kernel.asmOn compile le boot loader et le noyau sûˋparûˋmentô :
nasm -f bin -o bootsect bootsect.asm
nasm -f bin -o kernel kernel.asmOn remarque que le binaire du secteur de boot fait comme prûˋvu 512 octetsô :
$ ls -l
total 14
-rw-r--r-- 1 am users 492 Jan 17 17:20 UTIL.INC
-rw-r--r-- 1 am users 512 Jan 19 18:16 bootsect
-rw-r--r-- 1 am users 715 Jan 17 17:22 bootsect.asm
-rw-r--r-- 1 am users 297 Jan 17 17:50 kernel.asm
-rw-r--r-- 1 am users 69 Jan 19 18:16 kernelOn remarque aussi que le noyau fait seulement 69 octets, soit moins d'un secteur de disquette (512 octets), ce qui permet d'utiliser une valeur trû´s basse pour KSIZE. Au cas oû¿ le noyau occupe davantage de place, il faut augmenter cette valeur. Malheureusement, cela fonctionne dans une certaine limite, car la lecture de donnûˋes sur disque est complexe. Pour en savoir plusô :
- http://en.wikipedia.org/wiki/INT_13, dûˋcrit l'utilisation de l'interruption 0x13 du BIOSô ;
- https://fr.wikipedia.org/wiki/Cylinder/Head/Sector, dûˋcrit la structure des disques et des disquettes pour PC.
La disquette que nous allons faire aura le noyau placûˋ sur le deuxiû´me secteur. On rûˋalise une image de la disquette avec la commande suivanteô :
cat bootsect kernel /dev/zero | dd of=floppyA bs=512 count=2880
ls -l floppyA
-rw-r--r-- 1 am users 1474117 Jan 19 18:27 floppyA|
|
IV. Programmer un secteur de boot qui passe en mode protûˋgûˋ▲
- Pourquoi utiliser le mode protûˋgûˋPourquoi utiliser le mode protûˋgûˋô ?ô ?
- Adresser la mûˋmoire en mode protûˋgûˋAdresser la mûˋmoire en mode protûˋgûˋ
- Un boot loader qui passe en mode protûˋgûˋUn boot loader qui passe en mode protûˋgûˋ
- Un noyau trû´s simpleUn noyau trû´s simple
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : bootsect_PMode.tgz.
IV-A. Pourquoi utiliser le mode protûˋgûˋô ?▲
IV-A-1. Le mode protûˋgûˋ, c'est quoiô ?▲
Le microprocesseur d'un PC possû´de trois modes de fonctionnementô :
- le mode rûˋel, qui est le mode par dûˋfaut, fournit les mûˆmes fonctionnalitûˋs que le 8086. Mais cela a certaines consûˋquences comme l'impossibilitûˋ d'adresser plus de 1 Mo de mûˋmoireô ;
- le mode protûˋgûˋ (voir aussi sur Wikipûˋdia) permet d'exploiter la totalitûˋ des possibilitûˋs du microprocesseur, avec notamment l'adressage de toute la mûˋmoire et le support pour l'implûˋmentation de systû´mes multitûÂches et multiutilisateursô ;
- le mode virtuel est un mode particulier trû´s peu utilisûˋ.
Notre objectif ûˋtant de rûˋaliser un noyau multiutilisateur, multitûÂche et pouvant adresser toute la mûˋmoire, il nous faudra basculer le microprocesseur en mode protûˋgûˋ. Mais cela a d'importantes consûˋquences pour le programmeurô :
- le mûˋcanisme d'adressage en mode protûˋgûˋ est trû´s diffûˋrent de celui en mode rûˋelô ;
- le jeu d'instruction n'est plus sur 16 bits, mais sur 32 bits et 64 bits sur les processeurs actuellement utilisûˋsô ;
- il n'est pas possible avec ce mode de s'appuyer sur les routines du BIOS pour accûˋder aux pûˋriphûˋriques. Tous les drivers sont donc û rûˋûˋcrireô !
IV-A-2. Comment passer du mode rûˋel au mode protûˋgûˋ▲
Passer du mode rûˋel au mode protûˋgûˋ est trû´s simple, il suffit de mettre le bit 0 du registre CR0 û 1ô :
; PE mis a 1 (CR0)
ô ô mov eax, cr0
ô ô or ô ax, 1
ô ô mov cr0, eaxMais si cela suffit pour changer de mode, cela ne suffit pas û ce qu'un programme continue de fonctionner une fois le mode protûˋgûˋ ûˋtabli. Pourquoiô ? L'adressage en mode protûˋgûˋ, qui diffû´re de l'adressage en mode rûˋel, s'appuie sur des structures qui doivent ûˆtre correctement initialisûˋes lors du changement de mode pour que le processeur continue d'adresser correctement la mûˋmoire (et notamment le segment de donnûˋes, la pile et le pointeur d'instruction).
IV-B. Adresser la mûˋmoire en mode protûˋgûˋ▲
IV-B-1. Diffûˋrents types d'adresses▲
En mode protûˋgûˋ, il existe pour le programmeur trois types d'adressesô :
- l'adresse logique est directement manipulûˋe par le programmeur. Elle est composûˋe û partir d'un sûˋlecteur de segment et d'un offsetô ;
- cette adresse logique est transformûˋe par l'unitûˋ de segmentation en une adresse linûˋaire, sur 32 bitsô ;
- cette adresse linûˋaire est transformûˋe par l'unitûˋ de pagination en une adresse physique. Si la pagination n'est pas activûˋe, l'adresse linûˋaire correspond û l'adresse physique.
Le schûˋma ci-dessous rûˋsume le principe de l'adressage en mode protûˋgûˋô :
|
|

Dans un premier temps, nous allons utiliser uniquement le mûˋcanisme de segmentation sans le mûˋcanisme de pagination, plus dûˋlicat û mettre en éuvre.
IV-B-2. Le mûˋcanisme de segmentation▲
Une adresse logique est constituûˋe par un sûˋlecteur de segment et un offset. Le sûˋlecteur sûˋlectionne un bloc mûˋmoire d'une certaine taille, appelûˋ segment, qui dûˋfinit en quelque sorte l'espace de travail du programme. L'offset est un dûˋplacement par rapport au dûˋbut de ce bloc.
Un segment est dûˋcrit par une structure de 64 bits appelûˋe descripteur de segment qui prûˋciseô :
- sa base, l'endroit en mûˋmoire oû¿ commence le segmentô ;
- sa limite, la taille du segment exprimûˋe en octets ou en blocs de 4 koô ;
- son type (code, donnûˋes, pile ou autre).
Les descripteurs sont stockûˋs dans la Global Descriptor Table (GDT). Cette table peut rûˋsider n'importe oû¿ en mûˋmoire. Son adresse en mûˋmoire physique est renseignûˋe au processeur grûÂce û un registre particulierô : le GDTRô :
|
|
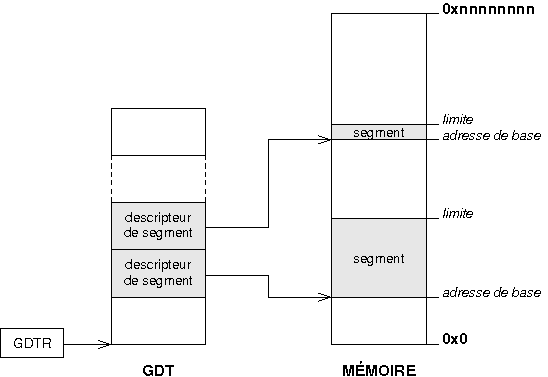
Le sûˋlecteur de segment est un registre de 16 bits directement manipulûˋ par le programmeur qui pointe sur un descripteur de segment dans la GDT et indique de ce fait dans quel segment on se situe. Ces registres sont bien connus de ceux qui ont dûˋjû programmûˋ en mode rûˋelô :
- CS est le sûˋlecteur de segment de codeô ;
- DS est le sûˋlecteur de segment de donnûˋesô ;
- ES, FS et GS sont des sûˋlecteurs de segments gûˋnûˋrauxô ;
- SS est le sûˋlecteur de segment de pile.
Sur les processeurs 64 bits, la segmentation n'est plus utilisûˋe sauf pour les segments FS et GS. En mode compatibilitûˋ, la segmentation est toujours prûˋsenteô :
Le sûˋlecteur pointe sur un descripteur qui donne l'adresse oû¿ commence le segment. En ajoutant l'offset û cette base, on obtient une adresse linûˋaire sur 32 bitsô :
|
|
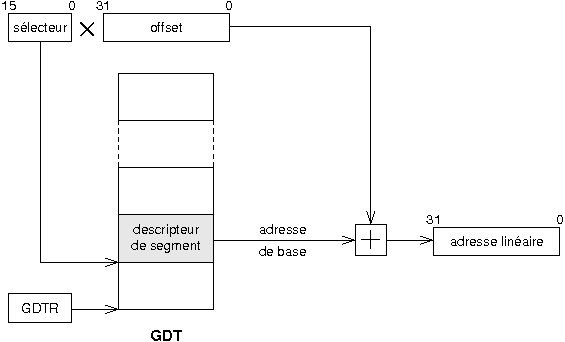
IV-B-3. Les descripteurs de segment en dûˋtail▲
Le schûˋma ci-dessous dûˋcrit la structure gûˋnûˋrale d'un descripteur de segmentô :
|
|
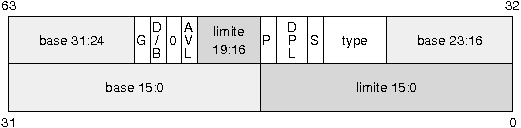
- la base, sur 32 bits, est l'adresse linûˋaire oû¿ dûˋbute le segment en mûˋmoireô ;
- la limite, sur 20 bits, dûˋfinit la longueur du segmentô ;
- si le bit G est û 0, la limite est exprimûˋe en octets, sinon, elle est exprimûˋe en nombre de pages de 4 koô ;
- le bit D/B prûˋcise la taille des instructions et des donnûˋes manipulûˋes. Il est mis û 1 pour 32 bitsô ;
- le bit AVL est librement disponibleô ;
- le bit P est utilisûˋ pour dûˋterminer si le segment est prûˋsent en mûˋmoire physique. Il est û 1 si c'est le casô ;
- le DPL indique le niveau de privilû´ge du segment. Le niveau 0 correspond au mode super-utilisateurô ;
- le bit S est mis û 1 pour un descripteur de segment et û 0 pour un descripteur systû´me (un genre particulier de descripteur que nous verrons plus tard)ô ;
- le type dûˋfinit le type de segment (code, donnûˋes ou pile).
IV-B-3-a. Descripteur d'un segment de code▲
|
|
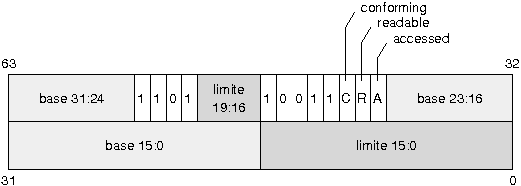
- Le bit G est mis û 1 (limite exprimûˋe en pages).
- Le bit D/B est mis û 1 (code sur 32 bits).
- Le bit P est mis û 1 (page prûˋsente en mûˋmoire).
- Le niveau de privilû´ge est mis û 0 (mode super-utilisateur).
- Le bit S est mis û 1 (descripteur de segment).
- Le premier bit û 1 pour le type indique que l'on a affaire û un segment de code.
- Pour pouvoir adresser toute la mûˋmoire, la base du segment doit ûˆtre û 0x0 et sa limite doit ûˆtre û 0xFFFFF avec le bit de granularitûˋ û 1.
- Le bit C indique si le segment de code est ô¨ô conformantô ô£ ou non. Pour le moment, ce bit sera mis û 0.
Ce flag est complexe û manipuler. Il est en lien avec les diffûˋrents niveaux de privilû´ges et de protection mis en éuvre par les microprocesseurs de type i386. La plupart des segments de code sont non conformants, ce qui signifie qu'ils peuvent transfûˋrer le contrûÇle (via un call ou un jmp) seulement û des segments de mûˆme privilû´ge. La gestion des niveaux de protection sur architecture i386 est rendue trû´s complexe par un foisonnement de mûˋcanismes impossibles û rûˋsumer ici. Pour une ûˋtude approfondie, l'ûˋtude de la documentation de rûˋfûˋrence est indispensableãÎ
- Le bit R est mis û 1 pour indiquer que le segment de code est accessible en lecture (en plus de l'ûˆtre en exûˋcution).
- Le bit A est mis û 1 par le processeur quand le segment est utilisûˋ.
IV-B-3-b. Descripteur d'un segment de donnûˋes▲
|
|
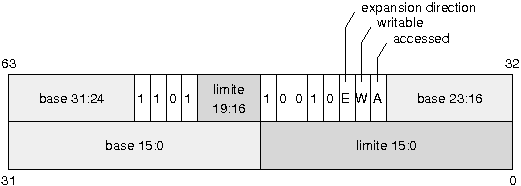
- Le segment de donnûˋes se distingue du segment de code par le champ type avec le premier bit qui est mis û 0.
- Le bit E indique le sens d'expansion des donnûˋes. Il est mis û 1 pour un segment de type ô¨ô pileô ô£ dans lequel les donnûˋes s'accumulent vers le dûˋbut de la mûˋmoire (expand-down segment).
Selon que le bit E est û 0 ou û 1, la limite s'interprû´te diffûˋremment. Pour un segment sur 32 bits, si le bit E est û 1, la limite supûˋrieure de la plage de donnûˋes est en 0xFFFFFFFF et la limite infûˋrieure est û l'adresse indiquûˋe par le champ limite. Noteô : û confirmer, mais il semble que la base soit dans ce cas purement ignorûˋe.
- Le bit W est mis û 1 pour indiquer que le segment est accessible en ûˋcriture (en plus de l'ûˆtre en lecture).
- Le bit A est mis û 1 par le processeur quand le segment est utilisûˋ.
IV-C. Un boot loader qui passe en mode protûˋgûˋ▲
IV-C-1. Quand passer en mode protûˋgûˋô ?▲
Il est possible de passer en mode protûˋgûˋ û plusieurs momentsô : lors de l'exûˋcution du secteur de boot ou du noyau. Notre noyau va utiliser un jeu d'instructions sur 32 bits, seulement utilisable en mode protûˋgûˋ. Le plus simple est donc de passer en mode protûˋgûˋ pendant le boot, avant que le noyau ne s'exûˋcute. Il est cependant possible que ce soit le noyau qui effectue la commutation, mais cela complique inutilement son ûˋcriture, car le code du noyau doit alors ûˆtre en partie sur 16 bits et en partie sur 32 bits.
IV-C-2. Le programme du boot loader▲
?fine BASE ô ô 0x100 ô ; 0x0100:0x0 = 0x1000
?fine KSIZE ô 50 ô ô ; nombre de secteurs û charger
[BITS 16]
[ORG 0x0]
jmp start
%include "UTIL.INC"
start:
; initialisation des segments en 0x07C0
ô ô mov ax, 0x07C0
ô ô mov ds, ax
ô ô mov es, ax
ô ô mov ax, 0x8000 ô ô ; stack en 0xFFFF
ô ô mov ss, ax
ô ô mov sp, 0xf000
; rûˋcupûˋration de l'unitûˋ de boot
ô ô mov [bootdrv], dl ô ô
; affiche un msg
ô ô mov si, msgDebut
ô ô call afficher
; charger le noyau
ô ô xor ax, ax
ô ô int 0x13
ô ô push es
ô ô mov ax, BASE
ô ô mov es, ax
ô ô mov bx, 0
ô ô mov ah, 2
ô ô mov al, KSIZE
ô ô mov ch, 0
ô ô mov cl, 2
ô ô mov dh, 0
ô ô mov dl, [bootdrv]
ô ô int 0x13
ô ô pop es
; initialisation du pointeur sur la GDT
ô ô mov ax, gdtend ô ô ; calcule la limite de GDT
ô ô mov bx, gdt
ô ô sub ax, bx
ô ô mov word [gdtptr], ax
ô ô xor eax, eax ô ô ô ; calcule l'adresse linûˋaire de GDT
ô ô xor ebx, ebx
ô ô mov ax, ds
ô ô mov ecx, eax
ô ô shl ecx, 4
ô ô mov bx, gdt
ô ô add ecx, ebx
ô ô mov dword [gdtptr+2], ecx
; passage en modep
ô ô cli
ô ô lgdt [gdtptr] ô ô ; charge la gdt
ô ô mov eax, cr0
ô ô or ô ax, 1
ô ô mov cr0, eax ô ô ô ô ; PE mis a 1 (CR0)
ô ô jmp next
next:
ô ô mov ax, 0x10 ô ô ô ô ; segment de donne
ô ô mov ds, ax
ô ô mov fs, ax
ô ô mov gs, ax
ô ô mov es, ax
ô ô mov ss, ax
ô ô mov esp, 0x9F000 ô ô
ô ô jmp dword 0x8:0x1000 ô ô ; rûˋinitialise le segment de code
;--------------------------------------------------------------------
bootdrv: ô db 0
msgDebut: db "Chargement du kernel", 13, 10, 0
;--------------------------------------------------------------------
gdt:
ô ô db 0, 0, 0, 0, 0, 0, 0, 0
gdt_cs:
ô ô db 0xFF, 0xFF, 0x0, 0x0, 0x0, 10011011b, 11011111b, 0x0
gdt_ds:
ô ô db 0xFF, 0xFF, 0x0, 0x0, 0x0, 10010011b, 11011111b, 0x0
gdtend:
;--------------------------------------------------------------------
gdtptr:
ô ô dw 0 ô ; limite
ô ô dd 0 ô ; base
;--------------------------------------------------------------------
;; NOP jusqu'a 510
times 510-($-$$) db 144
dw 0xAA55IV-C-2-a. Que fait exactement ce programmeô ?▲
Ce programme est identique û celui du chapitre prûˋcûˋdent avec en plus des instructions qui basculent le microprocesseur en mode protûˋgûˋ. Pour rûˋsumer, le numûˋro de pûˋriphûˋrique de boot est placûˋ dans une variable, les registres relatifs aux segments de code et de donnûˋes sont initialisûˋs, puis le noyau est chargûˋ en mûˋmoire û l'adresse 0x1000 (on note que la variable KSIZE a ûˋtûˋ augmentûˋe afin de charger un noyau plus volumineux). Ensuite, la GDT est initialisûˋe et chargûˋe en mûˋmoire, puis on bascule en mode protûˋgûˋ. Enfin, le noyau est exûˋcutûˋ.
Ce secteur de boot peut charger seulement des noyaux d'une taille limitûˋe et bien infûˋrieure û la capacitûˋ maximale d'une disquette. Nous verrons plus tard comment charger notre noyau û l'aide de GRUB.
IV-C-2-b. Passer en mode protûˋgûˋ▲
Avant de passer en mode protûˋgûˋ, il faut initialiser la GDT de faûÏon û ce qu'il n'y ait pas de problû´me d'adressage aprû´s le changement de mode. La GDT doit contenir des descripteurs pour les segments de code, de donnûˋes et de pile. Les directives ci-dessous dûˋclarent et initialisent la GDTô :
gdt:
ô ô db 0, 0, 0, 0, 0, 0, 0, 0
gdt_cs:
ô ô db 0xFF, 0xFF, 0x0, 0x0, 0x0, 10011011b, 11011111b, 0x0
gdt_ds:
ô ô db 0xFF, 0xFF, 0x0, 0x0, 0x0, 10010011b, 11011111b, 0x0
gdtend:L'ûˋtiquette gdt: est un pointeur sur le dûˋbut du tableau qui contient trois descripteursô :
- le premier descripteur ne doit pas ûˆtre utilisûˋ et les donnûˋes sont mises û zûˋro. Il s'agit du descripteur NULLô ;
- le deuxiû´me descripteur, avec l'ûˋtiquette gdt_cs: dûˋcrit le segment de codeô ;
- le troisiû´me descripteur, avec l'ûˋtiquette gdt_ds: dûˋcrit le segment de donnûˋes.
Chaque descripteur est initialisûˋ de faûÏon û pouvoir adresser l'ensemble de la RAM. La base de ces segments est û 0x0 avec une limite de 0xFFFFF pages (le bit G est û 1).
Les schûˋmas ci-dessous rûˋsument la faûÏon dont sont initialisûˋs les descripteurs.
Descripteur du segment de code
|
|
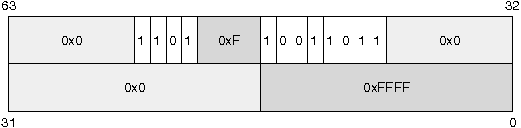
Descripteur du segment de donnûˋes
|
|
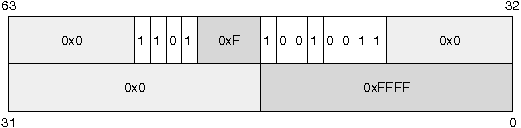
La GDT est directement initialisûˋe, mais avant de basculer en mode protûˋgûˋ, il faut renseigner le processeur pour qu'il prenne en compte la GDT. Cela se fait en mettant û jour le registre GDTR, de 6 octets, qui contient l'adresse de la GDT et sa taille (on parle aussi de limite). On charge ce registre spûˋcial avec l'instruction lgdt.
Dans le programme, gdtptr est un pointeur sur une structure qui contient les informations û charger dans le registre GDTR. La structure gdtptr est d'abord dûˋclarûˋe et initialisûˋe û zûˋro (comme une variable classique en C)ô :
gdtptr:
ô ô dw 0 ô ; limite
ô ô dd 0 ô ; baseEnsuite, on calcule les valeurs pour mettre dans cette structure. Le code suivant calcule la taille de la GDT et stocke la valeur dans le premier champ de gdptrô :
; initialisation du pointeur sur la GDT
ô ô mov ax, gdtend ô ô ; calcule la limite de GDT
ô ô mov bx, gdt
ô ô sub ax, bx
ô ô mov word [gdtptr], axCe code calcule l'adresse physique de la GDT en se basant sur les valeurs du segment de donnûˋes ds et de l'adresse de l'ûˋtiquette gdt. Le rûˋsultat de ce calcul est stockûˋ dans le second champ de gdptrô :
; calcule l'adresse linûˋaire de GDT
ô ô xor eax, eax
ô ô xor ebx, ebx
ô ô mov ax, ds
ô ô mov ecx, eax
ô ô shl ecx, 4
ô ô mov bx, gdt
ô ô add ecx, ebx
ô ô mov dword [gdtptr+2], ecxNotre structure est donc maintenant correctement initialisûˋe. Nous sommes maintenant presque prûˆt û passer en mode protûˋgûˋ. Avant cela, il faut inhiber les interruptions, car comme le systû´me d'adressage va changer, les routines appelûˋes par les interruptions ne seront plus valides aprû´s la bascule (il faudra les reprogrammer)ô :
; dûˋsactivation des interruptions
ô ô cliLe registre GDTR est chargûˋ avec l'instruction lgdt pour indiquer au microprocesseur oû¿ se trouve la GDTô :
; charge la gdt
ô ô lgdt [gdtptr]On peut maintenant passer en mode protûˋgûˋô :
; PE mis a 1 (CR0)
ô ô mov eax, cr0
ô ô or ô ax, 1
ô ô mov cr0, eaxEnfinô !ô :-)
Notre tûÂche semble terminûˋe. Mais au faitãÎ il reste encore û rûˋinitialiser les sûˋlecteurs de segment de code et de donnûˋesô ! La commande qui suit doit impûˋrativement ûˆtre la suivante afin de vider les caches internes du processeurô :
jmp gdt_next
next:En principe, il faudrait faire un far jump û la place du near jump ci-dessus pour rûˋinitialiser le sûˋlecteur de segment de code. Oui, mais voilû , le manuel spûˋcifieô : ô¨ô When the processor is switched into protected mode, the original code segment base-address value of FFFF0000H (located in the hidden part of the CS register) is retained and execution continues from the current offset in the EIP register. The processor will thus continue to execute code in the EPROM until a far jump or call is made to a new code segment, at which time, the base address in the CS register will be changed.ô ô£
Ensuite, on rûˋinitialise les sûˋlecteurs de donnûˋesô :
; segment de donnûˋes
ô ô mov ax, 0x10
ô ô mov ds, ax
ô ô mov fs, ax
ô ô mov gs, ax
ô ô mov es, axPuis le segment de pileô :
; la pile
ô ô mov ss, ax
ô ô mov esp, 0x9F000L'instruction suivante rûˋinitialise le sûˋlecteur de code et exûˋcute le noyau situûˋ û l'adresse physique 0x1000. Cette instruction est essentielle, car elle permet, outre l'exûˋcution du code du noyau, la rûˋinitialisation correcte du sûˋlecteur de code sur le bon descripteur (offset 0x8 dans la GDT)ô :
; rûˋinitialise le segment de code
ô ô jmp dword 0x8:0x1000Ensuite, le code du noyau s'exûˋcuteãÎ
IV-D. Un noyau trû´s simple▲
Ce noyau affiche juste un message de bienvenue et boucle ensuite indûˋfiniment. û ce stade, les routines du BIOS permettant d'afficher des caractû´res û l'ûˋcran ne sont plus utilisables, il faut donc que nous gûˋrions nous-mûˆme l'affichage.
IV-D-1. Le code du noyau▲
[BITS 32]
[ORG 0x1000]
; Affichage d'un message par ûˋcriture dans la RAM vidûˋo
ô ô mov byte [0xB8A00], 'H'
ô ô mov byte [0xB8A01], 0x57
ô ô mov byte [0xB8A02], 'E'
ô ô mov byte [0xB8A03], 0x0A
ô ô mov byte [0xB8A04], 'L'
ô ô mov byte [0xB8A05], 0x4E
ô ô mov byte [0xB8A06], 'L'
ô ô mov byte [0xB8A07], 0x62
ô ô mov byte [0xB8A08], 'O'
ô ô mov byte [0xB8A09], 0x0E
end:
ô ô jmp endIV-D-2. Afficher quelque chose û l'ûˋcran▲
La mûˋmoire vidûˋo est mappûˋe en mûˋmoire û l'adresse physique 0xB8000. On peut donc afficher des informations en manipulant directement les octets dûˋbutant û cette adresseô :
- la console d'affichage comprend 25 lignes et 80 colonnes.
- chaque caractû´re est dûˋcrit par 2 octets. Le premier contient le code ASCII du caractû´re û afficher et le suivant contient ses attributs (couleur, clignotementãÎ)
|
|

Les attributs sont codûˋs de la faûÏon suivanteô :
|
|
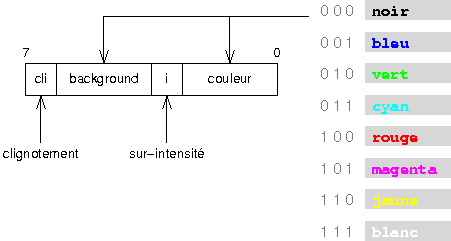
Par exemple, le code suivant affiche le caractû´re 'H' en blanc sur fond magenta en haut û gauche de l'ûˋcranô :
mov byte [0xB8000], 'H'
mov byte [0xB8001], 0x57IV-E. Compiler et tester le boot loader et le noyau▲
On compile le boot loader et le noyau sûˋparûˋment puis on crûˋe la disquetteô :
nasm -f bin -o bootsect bootsect.asm
nasm -f bin -o kernel kernel.asm
cat bootsect kernel /dev/zero | dd of=floppyA bs=512 count=2880|
|
V. ûcrire un noyau en C▲
- Pourquoi passer de l'assembleur au CPourquoi passer de l'assembleur au Cô ?ô ?
- Un noyau en assembleur qui fait appel û des fonctions en CUn noyau en assembleur qui fait appel û des fonctions en C
- Un noyau ûˋcrit entiû´rement en CUn noyau ûˋcrit entiû´rement en C
Sourcesô
Le package contenant toutes les sources est tûˋlûˋchargeable iciô : bootsect_kernelC.tgz.
V-A. Pourquoi passer de l'assembleur au Cô ?▲
La programmation en C offre par rapport û l'assembleur des avantages incontournablesô :
- concision de l'ûˋcritureô ;
- facilitûˋ du dûˋbogageô ;
- portabilitûˋ sur d'autres architectures.
Il est possible d'utiliser û peu prû´s n'importe quel langage compilûˋ pour ûˋcrire le code d'un noyau et chacun choisira le langage avec lequel il se sent le plus û l'aise (Pascal, C++ãÎ), la seule contrainte ûˋtant que ce langage doit permettre d'insûˋrer des routines en assembleur et de manipuler directement les adresses en mûˋmoire.
V-B. Un noyau en assembleur qui fait appel û des fonctions en C▲
V-B-1. Des routines pour afficher quelque chose û l'ûˋcran en C▲
Le fichier screen.c contient des fonctions permettant d'afficher des caractû´res û l'ûˋcranô :
#include "types.h"
#define RAMSCREEN 0xB8000ô ô ô ô /* dûˋbut de la mûˋmoire vidûˋo */
#define SIZESCREEN 0xFA0ô ô ô ô /* 4000, nombres d'octets d'une page texte */
#define SCREENLIM 0xB8FA0
char kX = 0;ô ô ô ô ô ô ô ô ô ô /* position courante du curseur û l'ûˋcran */
char kY = 17;
char kattr = 0x0E;ô ô ô ô ô ô ô /* attributs vidûˋo des caractû´res û afficher */
/*
ô * 'scrollup' scrolle l'ûˋcran (la console mappûˋe en ram) vers le haut
ô * de n lignes (de 0 a 25).
ô */
void scrollup(unsigned int n)
{
ô ô ô ô unsigned char *video, *tmp;
ô ô ô ô for (video = (unsigned char *) RAMSCREEN;
ô ô ô ô ô ô ô video < (unsigned char *) SCREENLIM; video += 2) {
ô ô ô ô ô ô ô ô tmp = (unsigned char *) (video + n * 160);
ô ô ô ô ô ô ô ô if (tmp < (unsigned char *) SCREENLIM) {
ô ô ô ô ô ô ô ô ô ô ô ô *video = *tmp;
ô ô ô ô ô ô ô ô ô ô ô ô *(video + 1) = *(tmp + 1);
ô ô ô ô ô ô ô ô } else {
ô ô ô ô ô ô ô ô ô ô ô ô *video = 0;
ô ô ô ô ô ô ô ô ô ô ô ô *(video + 1) = 0x07;
ô ô ô ô ô ô ô ô }
ô ô ô ô }
ô ô ô ô kY -= n;
ô ô ô ô if (kY < 0)
ô ô ô ô ô ô ô ô kY = 0;
}
void putcar(uchar c)
{
ô ô ô ô unsigned char *video;
ô ô ô ô int i;
ô ô ô ô if (c == 10) {ô ô ô ô ô /* CR-NL */
ô ô ô ô ô ô ô ô kX = 0;
ô ô ô ô ô ô ô ô kY++;
ô ô ô ô } else if (c == 9) {ô ô /* TAB */
ô ô ô ô ô ô ô ô kX = kX + 8 - (kX % 8);
ô ô ô ô } else if (c == 13) {ô ô /* CR */
ô ô ô ô ô ô ô ô kX = 0;
ô ô ô ô } else {ô ô ô ô ô ô ô ô /* autres caractû´res */
ô ô ô ô ô ô ô ô video = (unsigned char *) (RAMSCREEN + 2 * kX + 160 * kY);
ô ô ô ô ô ô ô ô *video = c;
ô ô ô ô ô ô ô ô *(video + 1) = kattr;
ô ô ô ô ô ô ô ô kX++;
ô ô ô ô ô ô ô ô if (kX > 79) {
ô ô ô ô ô ô ô ô ô ô ô ô kX = 0;
ô ô ô ô ô ô ô ô ô ô ô ô kY++;
ô ô ô ô ô ô ô ô }
ô ô ô ô }
ô ô ô ô if (kY > 24)
ô ô ô ô ô ô ô ô scrollup(kY - 24);
}
/*
ô * 'print' affiche û l'ûˋcran, û la position courante du curseur, une chaûÛne
ô * de caractû´res terminûˋe par \0.
ô */
void print(char *string)
{
ô ô ô ô while (*string != 0) {ô /* tant que le caractû´re est diffûˋrent de 0x0 */
ô ô ô ô ô ô ô ô putcar(*string);
ô ô ô ô ô ô ô ô string++;
ô ô ô ô }
}- Les variables kX et kY stockent en mûˋmoire l'emplacement du curseur a l'ûˋcran. La variable kattr contient les attributs vidûˋo des caractû´res affichûˋs.
- La fonction scrollup() prend en argument un entier n et scrolle l'ûˋcran de n lignes.
- La fonction putcar() affiche un caractû´re û l'ûˋcran.
- La fonction print() affiche une chaûÛne de caractû´res.
Notez que certains types ont ûˋtûˋ dûˋfinis dans le fichier types.hô :
#ifndef _I386_TYPE_
#define _I386_TYPE_
typedef unsigned char u8;
typedef unsigned short u16;
typedef unsigned int u32;
typedef unsigned char uchar;
#endifV-B-2. Un nouveau noyau en assembleur▲
Le code du noyau ci-dessous fait appel aux fonctions d'affichage dûˋfinies ci-dessus. Cet exemple est assez intûˋressant, car il montre comment un programme en assembleur fait appel û une fonction ûˋcrite en C (ce sujet est dûˋveloppûˋ dans l'annexe sur la compilation sûˋparûˋe en assembleur sous UnixAnnexe Aô :ô Compilation sûˋparûˋe en assembleur sous Unix)ô :
[BITS 32]
EXTERN scrollup, print
GLOBAL _start
_start:
ô ô mov ô eax, msg
ô ô push eax
ô ô call print
ô ô pop ô eax
ô ô mov ô eax, msg2
ô ô push eax
ô ô call print
ô ô pop ô eax
ô ô mov ô eax, 2
ô ô push eax
ô ô call scrollup
end:
ô ô jmp end
msg ô db 'un premier message', 10, 0
msg2 db 'un deuxiû´me message', 10, 0Par rapport aux prûˋcûˋdents noyaux, on note surtoutô :
- l'absence de directive ORG, qui sert au calcul des adresses en fonction de l'endroit oû¿ le code est relogûˋ. Ce calcul est maintenant rûˋalisûˋ par le linker ldô ;
- la prûˋsence du point d'entrûˋe _start, indispensable û ld.
V-B-3. Compiler le noyau▲
gcc -c screen.c
nasm -f elf -o kernel.o kernel.asm
ld --oformat binary -Ttext 1000 kernel.o screen.o -o kernelL'option -Ttext indique l'adresse linûˋaire û partir de laquelle le code commence. Par dûˋfaut, ld suppose que le code commence û l'adresse 0x0. Ici, ce paramû´tre est indispensable, car le code du noyau est recopiûˋ par le secteur de boot en 0x1000. La mûˆme fonctionnalitûˋ ûˋtait implûˋmentûˋe par la directive [ORG 0x1000] dans les noyaux prûˋcûˋdents en assembleur.
L'option -Tdata, qui sert û indiquer l'offset de dûˋbut de la section de donnûˋes, n'est pas utilisûˋe. Par dûˋfaut, le linker considû´re que la zone de donnûˋes suit la zone de texte (on remarque qu'elle est relogûˋe une page mûˋmoire plus loin).
V-C. Un noyau ûˋcrit entiû´rement en C▲
V-C-1. Le code▲
extern void scrollup(unsigned int);
extern void print(char *);
extern kY;
extern kattr;
void _start(void)
{
ô ô ô ô kY = 18;
ô ô ô ô kattr = 0x5E;
ô ô ô ô print("un message\n");
ô ô ô ô kattr = 0x4E;
ô ô ô ô print("un autre message\n");
ô ô ô ô scrollup(2);
ô ô ô ô while (1);
}Le code du noyau en C reprend de faûÏon fidû´le le code exprimûˋ plus haut en assembleur.
V-C-2. Compiler le noyau▲
gcc -c screen.c
gcc -c kernel.c
ld --oformat binary -Ttext 1000 kernel.o screen.o -o kernel|
|
VI. Programmer un noyau en C qui recharge la GDT▲
- Pourquoi changer de GDTPourquoi changer de GDTô ?ô ?
- Un noyau qui recharge la GDTUn noyau qui recharge la GDT
Sourcesô :
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_ReloadGDT.tgz
VI-A. Pourquoi changer de GDTô ?▲
Au boot, le programme du MBR commute le PC en mode protûˋgûˋ afin de pouvoir charger et exûˋcuter un noyau 32 bits. Le problû´me est que la GDT initialisûˋe par le secteur de boot ne correspond pas forcûˋment û celle que l'on souhaite pour le noyau. Par exemple, si on dûˋmarre notre noyau û l'aide de LILO ou d'un autre boot loader, on ne sait pas û l'avance oû¿ sera la GDT ni comment elle sera constituûˋe. Un noyau doit donc initialiser et charger sa propre GDT.
VI-B. Un noyau qui recharge la GDT▲
VI-B-1. Le programme principal▲
Il affiche un message, initialise la nouvelle GDT et la charge en mûˋmoire. Aprû´s avoir rûˋinitialisûˋ la pile, le noyau passe la main û la fonction main() qui affiche un message et boucle indûˋfinimentô :
#include "types.h"
#include "gdt.h"
#include "screen.h"
int main(void);
void _start(void)
{
ô ô ô ô kY = 18;
ô ô ô ô kattr = 0x5E;
ô ô ô ô print("kernel : loading new gdt...\n");
ô ô ô ô /* initialisation de la GDT et des segments */
ô ô ô ô init_gdt();
ô ô ô ô /* Initialisation du pointeur de pile %esp */
ô ô ô ô asm("ô ô movw $0x18, %ax \n \
ô ô ô ô ô ô ô ô movw %ax, %ss \n \
ô ô ô ô ô ô ô ô movl $0x20000, %esp");
ô ô ô ô main();
}
int main(void)
{
ô ô ô ô kattr = 0x4E;
ô ô ô ô print("kernel : new gdt loaded !\n");
ô ô ô ô while (1);
}VI-B-2. Initialiser la GDT▲
VI-B-2-a. Les descripteurs de segment en C▲
Les structures ci-dessous, dûˋfinies dans le fichier gdt.h, servent û crûˋer les descripteurs de segment et le registre GDTRô :
/* Descripteur de segment */
struct gdtdesc {
ô ô u16 lim0_15; ô ô
ô ô u16 base0_15;
ô ô u8 base16_23;
ô ô u8 acces;
ô ô u8 lim16_19 : 4;
ô ô u8 other : 4;
ô ô u8 base24_31;
} __attribute__ ((packed));
/* Registre GDTR */
struct gdtr {
ô ô u16 limite ;
ô ô u32 base ;
} __attribute__ ((packed));La directive __attribute__ ((packed)) indique û gcc que la structure en question doit occuper le moins de place possible en mûˋmoire. Sans cette directive, le compilateur insû´re des octets entre les champs de la structure afin de les aligner pour optimiser la vitesse d'accû´s. Or dans notre cas, nous voulons que la structure dûˋcrive exactement l'occupation en mûˋmoire des donnûˋes.
Pour ces mûˆmes raisons, il faut dûˋfinir de nouveaux types de donnûˋes afin de maûÛtriser les allocations en mûˋmoire. Ces types sont dûˋfinis dans le fichier types.h.
#ifndef _I386_TYPE_
#define _I386_TYPE_
typedef unsigned char u8;
typedef unsigned short u16;
typedef unsigned int u32;
typedef unsigned char uchar;
#endifVI-B-2-b. La fonction init_gdt()▲
Le fichier gdt.c contient la fonction init_gdt() qui initialise les descripteurs de segments et charge la nouvelle GDTô :
#include "types.h"
#include "lib.h"
#define __GDT__
#include "gdt.h"
/*
ô * 'init_desc' initialise un descripteur de segment situe en gdt ou en ldt.
ô * 'desc' est l'adresse linûˋaire du descripteur û initialiser.
ô */
void init_gdt_desc(u32 base, u32 limite, u8 acces, u8 other,
ô ô ô ô ô ô ô ô ô ô struct gdtdesc *desc)
{
ô ô ô ô desc->lim0_15 = (limite & 0xffff);
ô ô ô ô desc->base0_15 = (base & 0xffff);
ô ô ô ô desc->base16_23 = (base & 0xff0000) >> 16;
ô ô ô ô desc->acces = acces;
ô ô ô ô desc->lim16_19 = (limite & 0xf0000) >> 16;
ô ô ô ô desc->other = (other & 0xf);
ô ô ô ô desc->base24_31 = (base & 0xff000000) >> 24;
ô ô ô ô return;
}
/*
ô * Cette fonction initialise la GDT aprû´s que le kernel soit chargûˋ
ô * en mûˋmoire. Une GDT est dûˋjû opûˋrationnelle, mais c'est celle qui
ô * a ûˋtûˋ initialisûˋe par le secteur de boot et qui ne correspond
ô * pas forcement û celle que l'on souhaite.
ô */
void init_gdt(void)
{
ô ô ô ô /* initialisation des descripteurs de segment */
ô ô ô ô init_gdt_desc(0x0, 0x0, 0x0, 0x0, &kgdt[0]);
ô ô ô ô init_gdt_desc(0x0, 0xFFFFF, 0x9B, 0x0D, &kgdt[1]);ô ô ô /* code */
ô ô ô ô init_gdt_desc(0x0, 0xFFFFF, 0x93, 0x0D, &kgdt[2]);ô ô ô /* data */
ô ô ô ô init_gdt_desc(0x0, 0x0, 0x97, 0x0D, &kgdt[3]);ô ô ô ô ô /* stack */
ô ô ô ô /* initialisation de la structure pour GDTR */
ô ô ô ô kgdtr.limite = GDTSIZE * 8;
ô ô ô ô kgdtr.base = GDTBASE;
ô ô ô ô /* recopie de la GDT û son adresse */
ô ô ô ô memcpy((char *) kgdtr.base, (char *) kgdt, kgdtr.limite);
ô ô ô ô /* chargement du registre GDTR */
ô ô ô ô asm("lgdtl (kgdtr)");
ô ô ô ô /* initialisation des segments */
ô ô ô ô asm(" ô movw $0x10, %axô \n \
ô ô ô ô ô ô movw %ax, %dsô ô ô ô \n \
ô ô ô ô ô ô movw %ax, %esô ô ô ô \n \
ô ô ô ô ô ô movw %ax, %fsô ô ô ô \n \
ô ô ô ô ô ô movw %ax, %gsô ô ô ô \n \
ô ô ô ô ô ô ljmp $0x08, $nextô ô \n \
ô ô ô ô ô ô next:ô ô ô ô ô ô ô ô \n");
}Les descripteurs sont initialisûˋs et copiûˋs dans le tableau kgdt[]ô :
init_gdt_desc(0x0, 0xFFFFF, 0x9B, 0x0D, &kgdt[1]); ô ô ô /* code */
init_gdt_desc(0x0, 0xFFFFF, 0x93, 0x0D, &kgdt[2]); ô ô ô /* data */
init_gdt_desc(0x0, 0x0, 0x97, 0x0D, &kgdt[3]); ô ô ô ô ô /* stack */- Les segments de code et de donnûˋes ont leur base qui est û 0 et leur limite est de 0xFFFFF + 1 = 0x100000 pages de 4ô ko, soient 4 Go. Autrement dit, ils adressent l'ensemble de la mûˋmoire.
- De faûÏon un peu ûˋtonnante, le segment de pile a une base et une limite qui sont û 0ô ! Dans un segment de pile (expand down), la base n'est pas interprûˋtûˋe, elle est donc ici mise û 0. La limite se calcule comme pour les autres segments, mais elle doit ûˆtre interprûˋtûˋe comme la limite infûˋrieure du segment. Dans le cas prûˋsent, le segment de pile recouvre donc toute la mûˋmoire.
Une fois le tableau rempli, il est recopiûˋ û l'endroit en mûˋmoire oû¿ la GDT doit rûˋsiderô :
/* recopie de la GDT a son adresse */
memcpy((char *) kgdtr.base, (char *) kgdt, kgdtr.limite);Ensuite, la structure kgdtr est initialisûˋe puis chargûˋe dans le registre GDTR. û ce moment-lû , le changement de GDT est effectifô :
/* chargement du registre GDTR */
asm("lgdtl (kgdtr)");Une fois la nouvelle GDT chargûˋe, il faut mettre û jour les sûˋlecteurs de segments de donnûˋes (ds, es, fs , gs et ss). Un long jump permet de mettre û jour le sûˋlecteur du segment de codeô :
/* initialisation des segments */
ô asm(" ô movw $0x10, %axô ô ô ô \n \
ô ô ô ô ô movw %ax, %dsô \n \
ô ô ô ô ô movw %ax, %esô \n \
ô ô ô ô ô movw %ax, %fsô \n \
ô ô ô ô ô movw %ax, %gsô \n \
ô ô ô ô ô ljmp $0x08, $nextô ô ô \n \
ô ô ô ô ô next:ô ô ô ô ô \n");Vous avez sans doute remarquûˋ que le pointeur de pile est initialisûˋ aprû´s l'appel û la fonction init_gdt(). Pourquoi n'est-il pas initialisûˋ dans init_gdt() comme tous les autresô ? Parce que l'instruction assembleur leave, en fin de fonction, ûˋcrase le registre esp avec la valeur de ebp. Tout serait alors û refaireô ! Une solution serait de forcer la valeur de ebp de faûÏon û ce qu'elle coû₤ncide avec celle de esp, mais cela ne ferait que repousser le problû´meô : n'oubliez pas qu'en changeant la pile, on perd l'adresse sauvegardûˋe du compteur ordinal (eip) qui permet le retour.
VI-B-3. Une fonction main() pour dûˋjouer les piû´ges de gcc▲
/* initialisation de la GDT et des segments */
init_gdt();
/* Initialisation du pointeur de pile %esp */
asm(" ô movw $0x18, %ax \n \
ô ô ô ô movw %ax, %ss \n \
ô ô ô ô movl $0x20000, %esp");
main();Aprû´s avoir initialisûˋ la GDT, la pile est initialisûˋe pour pointer en 0x20000. Cette adresse est arbitraire, j'aurais pu choisir autre choseãÎ mais attention û prendre une valeur oû¿ la pile ne risque pas de corrompre le code ou des donnûˋesô !
Aprû´s ces initialisations, une fonction main() est appelûˋe. La crûˋation d'une nouvelle fonction peut sembler luxueuse quand on voit ce qu'elle rûˋaliseô : juste afficher un messager et boucler indûˋfiniment. N'aurait-on pas pu placer l'intûˋgralitûˋ du code dans la fonction _start()ô ? Non, car l'appel û la fonction print est rûˋalisûˋ par gcc de cette faûÏonô :
movlô ô $.LC1, (%esp)
callô ô printOn remarque que le passage d'argument ne se fait pas par un push, mais par un mov qui ûˋcrit l'adresse de la chaûÛne de caractû´res û afficher directement en 0x20000, ce qui est au-delû du sommet de la pileô ! En principe, pour passer un paramû´tre û une fonction, un compilateur doit utiliser push qui dûˋcrûˋmente d'abord la valeur de esp avant d'ûˋcrire sur la pile, mais gcc procû´de autrement en rûˋservant au dûˋbut de la fonction suffisamment de place sur la pile. Mais comme nous avons modifiûˋ entretemps la structure de la pile, et donc de la frame associûˋe û la fonction _start, cela ne peut plus fonctionnerô ! La fonction main() permet de repartir sur une frameAnnexe D - Gûˋrer les arguments sur la pile avec les Stack Frame propre.
VI-B-4. Compiler le bootloader et le noyau▲
tar xfz kernel_ReloadGDT.tgz
cd ReloadGDT
make|
|
VII. Programmer les interruptions du processeur i386 avec le contrûÇleur d'interruptions 8259A▲
- Des interruptions pour prûˋvenir le processeur d'un ûˋvûˋnementDes interruptions pour prûˋvenir le processeur d'un ûˋvûˋnement
- Un chipset pour gûˋrer les interruptions matûˋriellesô : le 8259AUn chipset pour gûˋrer les interruptions matûˋriellesô : le 8259A
- Exûˋcuter la bonne routine de service grûÂce û la table des descripteurs d'interruptionsExûˋcuter la bonne routine de service grûÂce û la table des descripteurs d'interruptions
VII-A. Des interruptions pour prûˋvenir le processeur d'un ûˋvûˋnement▲
Les interruptions sont des signaux envoyûˋs au processeur pour l'avertir d'ûˋvûˋnements particuliers. On distingue trois types d'interruptionsô :
- les interruptions matûˋrielles sont dûˋclenchûˋes par les pûˋriphûˋriques (clavier, disque, souris, etc.). Par exemple, une interruption matûˋrielle va ûˆtre dûˋclenchûˋe par une unitûˋ de disque pour prûˋvenir le processeur que des donnûˋes sont prûˆtes en lecture ou par une carte rûˋseau pour prûˋvenir de l'arrivûˋe d'une trame Ethernetô ;
- les interruptions logicielles sont dûˋclenchûˋes volontairement par le programme. Elles permettent de gûˋrer les appels systû´meô ;
- les exceptions sont dûˋclenchûˋes par le processeur en cas de faute (division par zûˋro, dûˋfaut de page, etc.).
Lorsque le processeur reûÏoit une interruption, il interrompt la tûÂche en cours, sauvegarde le contexte de celle-ci, et exûˋcute la routine de service associûˋe û l'interruption (ISR - Interrupt Service Routine) . Une fois la routine exûˋcutûˋe, le systû´me redonne en gûˋnûˋral la main û la tûÂche interrompue.
VII-A-1. Un exemple d'interruption▲
Quand on presse ou qu'on relûÂche une touche du clavier d'un PC, le contrûÇleur du clavier envoie une interruption û un chipset chargûˋ de multiplexer les interruptionsô : le contrûÇleur d'interruptions. Si l'interruption en question n'est pas masquûˋe, le contrûÇleur dûˋclenche une interruption matûˋrielle pour prûˋvenir le processeur. Le processeur exûˋcute alors une routine pour traiter l'ûˋvûˋnement (touche pressûˋe ou relûÂchûˋe). En gûˋnûˋral, cette routine va interroger le contrûÇleur du clavier pour savoir quelle touche a ûˋtûˋ pressûˋe (ou relûÂchûˋe), puis il va ûˋventuellement afficher le caractû´re correspondant et/ou le stocker dans un buffer. Une fois la routine de traitement de caractû´re terminûˋe, la tûÂche interrompue peut reprendre.
VII-B. Un chipset pour gûˋrer les interruptions matûˋriellesô : le 8259A▲
VII-B-1. û quoi sert le 8259Aô ?▲
Les interruptions matûˋrielles peuvent ûˆtre vues comme des sonnettes tirûˋes par les pûˋriphûˋriques pour prûˋvenir le processeur que quelque chose se passe. Mais si chaque pûˋriphûˋrique pouvait envoyer directement un signal au processeur, il faudrait sur celui-ci autant de broches que de pûˋriphûˋriques. Le contrûÇleur d'interruption programmable (PIC, Programmable interrupt controler) est un chipset qui permet d'ûˋviter cela en multiplexant les requûˆtes d'interruption envoyûˋes par les pûˋriphûˋriques. Le 8259A est l'un des premiers PIC dûˋveloppûˋs par Intel.
Chaque 8259A peut gûˋrer les interruptions de 8 pûˋriphûˋriques, mais la plupart des PC ont deux contrûÇleurs cascadûˋs entre eux, ce qui leur permet de gûˋrer jusqu'û 14 pûˋriphûˋriques. Le second contrûÇleur (esclave) est chaûÛnûˋ au premier (contrûÇleur maûÛtre). Un contrûÇleur peut rûˋaliser des fonctions plus complexes que la simple transmission d'interruptionsô : il peut masquer des interruptions et dûˋfinir des prioritûˋs de traitement.
Sur les machines modernes, les PIC 8259 sont remplacûˋs par les APûC rûˋtrocompatibles.https://en.wikipedia.org/wiki/Advanced_Programmable_Interrupt_Controller
VII-B-2. Comment le 8259A traite les interruptions▲
Quand un pûˋriphûˋrique transmet au 8259A une requûˆte pour une interruption, celle-ci subit un traitement complexeô :
- Le registre IMR (Interrupt Mask Register) interne au contrûÇleur permet de masquer certaines interruptions. Si l'interruption est masquûˋe, on ne la traite pasô ;
- Le registre IRR (Interrupt Request Register) est chargûˋ de gûˋrer les prioritûˋs entre interruptions au cas oû¿ plusieurs d'entre elles surviennent en mûˆme temps. La requûˆte avec la plus haute prioritûˋ est ûˋvaluûˋeô ;
- Le 8259A signale au processeur la demande d'interruption. La requûˆte faite par le contrûÇleur au processeur est appelûˋe IRQ (Interrupt Request)ô ;
- Le processeur acquitte ce signal puis demande au contrûÇleur, par un autre signal, le numûˋro de l'interruption demandûˋe afin de dûˋclencher la bonne routine ISRô ;
- Le contrûÇleur dûˋpose sur le bus de donnûˋes un octet, le vecteur d'interruptionô ;
- Une fois la routine terminûˋe, le processeur doit envoyer au contrûÇleur un signal pour l'avertir que le traitement de l'interruption est terminûˋ.
VII-B-3. Comment programmer le 8259Aô ?▲
Il est possible de paramûˋtrer les deux PIC d'un PC en ûˋcrivant dans leurs registres internes via les ports d'entrûˋe/sortie du processeur. On accû´de au contrûÇleur maûÛtre via les ports 0x20 et 0x21 et au contrûÇleur esclave via les ports 0xA0 et 0xA1. En ûˋcrivant sur ces ports, on envoie au contrûÇleur des donnûˋes qui seront inscrites dans l'un de ses registres.
Il y a deux types de registresô :
- les registres ICW (Initialization Command Word), qui rûˋinitialisent le contrûÇleurô ;
- les registres OCW (Operation Control Word), qui permettent de paramûˋtrer certaines fonctions du contrûÇleur une fois que celui-ci a ûˋtûˋ rûˋinitialisûˋ.
Pour rûˋinitialiser un contrûÇleur, il faut remplir les registres d'initialisation ICW1, ICW2, ICW3 et ICW4 en respectant cet ordre. Aprû´s avoir transmis les donnûˋes pour le registre ICW1, le contrûÇleur attend une valeur û mettre dans le registre ICW2 et ainsi de suite. S'il n'y a qu'un seul contrûÇleur, ce n'est pas la peine de renseigner les registres ICW3 et ICW4.
Les registres OCW peuvent ûˆtre remplis û n'importe quel moment aprû´s l'initialisation des PIC. Le registre OCW1 permet notamment de masquer et dûˋmasquer les interruptions.
VII-B-3-a. Registres ICW▲
ICW1 (port 0x20 / port 0xA0)
|0|0|0|1|x|0|x|x|
| | +--- avec ICW4 (1) ou sans (0)
| +----- un seul contrûÇleur (1), ou cascadûˋs (0)
+--------- dûˋclenchement par niveau (level) (1) ou par front (edge) (0)Par exemple, pour mettre û jour le registre ICW1 du contrûÇleur maûÛtre et du contrûÇleur esclaveô :
mov al, 0x11 ô ; Initialisation de ICW1
out 0x20, al ô ; maûÛtre
out 0xA0, al ô ; esclaveICW2 (port 0x21 / port 0xA1)ô :
|x|x|x|x|x|0|0|0|
| | | | |
+----------------- adresse de base des vecteurs d'interruptionLes bits de poids fort servent û calculer l'adresse de base du vecteur d'interruption. Cette valeur correspond û un offset dans la table IDT (voir plus loin). Par exemple, pour initialiser les adresses de base des vecteurs d'interruption des deux contrûÇleursô :
mov al, 0x20
out 0x21, al ô ; maûÛtre, vecteur de dûˋpart = 32
mov al, 0x70 ô
out 0xA1, al ô ; esclave, vecteur de dûˋpart = 96Dans l'exemple ci-dessus, les IRQ 0-7 sont mappûˋes pour utiliser les interruptions 0x20-0x27 et les IRQ 8-15 sont mappûˋes sur les interruptions 0x70-0x77. Noteô : sur les architectures de type x86, les 32 premiers vecteurs (0x0-0x19) sont rûˋservûˋs û la gestion des exceptions. Cela explique pourquoi les IRQ ne sont pas mappûˋes û partir du dûˋbut de la table.
ICW3 (port 0x21 / port 0xA1)ô :
Ce registre informe les contrûÇleurs de la faûÏon dont ils sont connectûˋs entre euxô :
|x|x|x|x|x|x|x|x| pour le maûÛtre
| | | | | | | |
+------------------ contrûÇleur esclave rattachûˋ û la broche d'interruption (1), ou non (0)Remarqueô : un contrûÇleur maûÛtre peut ûˆtre rattachûˋ û plusieurs contrûÇleurs esclaves.
|0|0|0|0|0|x|x|x| pour l'esclave
| | |
+-------- Identifiant de l'esclave, qui correspond au numûˋro de broche IR sur le maûÛtreOn dûˋtermine ici par quelles broches communiquent les deux contrûÇleurs. Dans l'exemple suivant, le contrûÇleur esclave est rattachûˋ û la broche 2 du maûÛtreô :
mov al, 0x04 ; maûÛtre
out 0x21, al
mov al, 0x02 ; esclave
out 0xA1, alICW4 (port 0x21 / port 0xA1)ô :
ce registre spûˋcifie dans quel mode doit fonctionner le contrûÇleur. Ceci vient du fait que le 8259A a ûˋtûˋ conûÏu pour ûˆtre gûˋnûˋrique et supporter diffûˋrents systû´mesô :
|0|0|0|x|x|x|x|1|
| | | +------ mode "automatic end of interrupt" AEOI (1)
| | +-------- mode bufferisûˋ esclave (0) ou maûÛtre (1)
| +---------- mode bufferisûˋ (1)
+------------ mode "fully nested" (1)Dans le cas prûˋsent, nous avons seulement besoin du mode par dûˋfautô :
mov al, 0x01
out 0x21, al
out 0xA1, alSi on initialise les registres d'un contrûÇleur les uns û la suite des autres, une petite temporisation est nûˋcessaireô :
mov al, 0x11 ô ; initialisation de ICW1
out 0x20, al
jmp .1 ô ô ô ô ; temporisation
.1:
mov al, 0x20 ô ; initialisation de ICW2
out 0x21, al ô ; vecteur de dûˋpart = 32
jmp .2 ô ô ô ô ; temporisation
.2:
mov al, 0x04 ô ; initialisation de ICW3
out 0x21, al
jmp .3 ô
.3:
mov al, 0x01 ô ; initialisation de ICW4
out 0x21, alVII-B-3-b. Registres OCW▲
OCW1 (port 0x21 / port 0xA1)ô :
|x|x|x|x|x|x|x|x|
| | | | | | | |
+------------------ pour chaque IRQ : masque d'interruption ûˋtabli (1) ou non (0)Pour modifier le registre IMR permettant de masquer les interruptionsô :
in ô al, 0x21 ô ; lecture de l'Interrupt Mask Register (IMR)
and al, 0xEF ô ; 0xEF => 11101111b. dûˋbloque l'IRQ 4
out 0x21, al ô ; recharge l'IMROCW2 (port 0x20 / port 0xA0)ô :
Ce registre est utilisûˋ essentiellement pour avertir le contrûÇleur que l'interruption en cours a ûˋtûˋ traitûˋe et qu'il peut rûˋtablir les interruptions matûˋriellesô :
mov al, 0x20
out 0x20, al ô ; "End Of Interrupt" (EOI) envoyûˋ au PICPour une description des registres OCW2 et OCW3, non utilisûˋs dans le noyau, consultez la documentation de rûˋfûˋrence.
VII-C. Exûˋcuter la bonne routine de service grûÂce û la table des descripteurs d'interruptions▲
La table IDT (Interrupt Descriptor Table) permet d'associer û chaque interruption une routine de service. Chaque entrûˋe de l'IDT est un descripteur particulier qui pointe sur une routine. Lorsqu'une interruption survient, le contrûÇleur transmet au processeur un vecteur d'interruption. Le processeur l'utilise pour calculer un offset dans l'IDT, charge un descripteur systû´me, puis active la routine de service correspondantô :
|
|
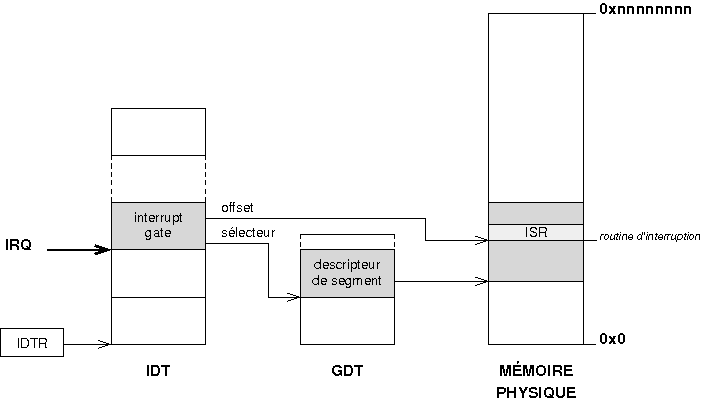
Les descripteurs dans l'IDT utilisûˋs pour gûˋrer les interruptions sont des descripteurs systû´me d'un type particulierô : les interrupt gate.
Il est aussi possible d'utiliser des descripteurs du type trap gate. La seule diffûˋrence est que ces derniers ne dûˋsactivent pas les interruptions (via le bit IF du registre EFLAGS) lorsqu'une interruption est reûÏue.
VII-C-1. Descripteur systû´me de type Interrupt Gate▲
|
|
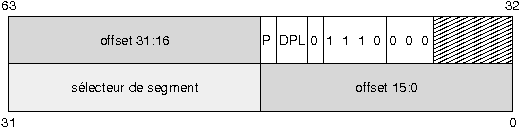
- Le bit P est utilisûˋ pour dûˋterminer si le segment est prûˋsent en mûˋmoire physique. Il est û 1 si c'est le cas.
- Le DPL indique le niveau de privilû´ge du segment. Le niveau 0 correspond au mode super-utilisateur.
VIII. Gûˋrer les interruptions - la mise en éuvre▲
- Prûˋalableô : ûˋtendre le code C du noyau û l'aide de directives en assembleurPrûˋalableô : ûˋtendre le code C du noyau û l'aide de directives en assembleur
- Initialiser la table IDTInitialiser la table IDT
- Le programme principal du noyauLe programme principal du noyau
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_ManageINT.tgz
Notez que vous pouvez utiliser la commande diff pour visualiser les parties modifiûˋes ou ajoutûˋes par rapport aux sources du chapitre prûˋcûˋdentô :
diff -u -r -N ReloadGDT/ ManageINT/VIII-A. Prûˋalableô : ûˋtendre le code C du noyau û l'aide de directives en assembleur▲
Un certain nombre d'instructions existent en assembleur, et sont nûˋcessaires û l'ûˋcriture de notre noyau, mais n'ont pas d'ûˋquivalent en C. C'est notamment le cas des instructions cli, sti, in et out. Les macros dûˋfinies dans le fichier io.h permettent de contourner cette difficultûˋ en ûˋtendant le jeu d'instructions.
/* dûˋsactive les interruptions */
#define cli asm("cli"::)
/* rûˋactive les interruptions */
#define sti asm("sti"::)
/* ûˋcrit un octet sur un port */
#define outb(port,value) \
ô ô ô ô asm volatile ("outb %%al, %%dx" :: "d" (port), "a" (value));
/* ûˋcrit un octet sur un port et marque une temporisation ô */
#define outbp(port,value) \
ô ô ô ô asm volatile ("outb %%al, %%dx; jmp 1f; 1:" :: "d" (port), "a" (value));
/* lit un octet sur un port */
#define inb(port) ({ ô ô \
ô ô ô ô unsigned char _v; ô ô ô \
ô ô ô ô asm volatile ("inb %%dx, %%al" : "=a" (_v) : "d" (port)); \
ô ô ô ô _v; ô ô \
})Nous avons dûˋjû vu dans les chapitres prûˋcûˋdents comment inclure de l'assembleur dans le code C de gcc avec la directive asm(). Il faut noter la particularitûˋ suivanteô : gcc se base sur gas qui utilise la syntaxe AT&T.
VIII-B. Initialiser la table IDT▲
VIII-B-1. Crûˋer les descripteurs systû´me de type Interrupt Gate▲
Les descripteurs systû´me de l'IDT gûˋrant les interruptions, dont le fonctionnement est expliquûˋ au chapitre prûˋcûˋdentProgrammer les interruptions du processeur i386 avec le contrûÇleur d'interruptions 8259A, ont ce modû´leô :
|
|
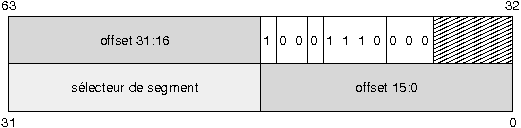
La structure ci-dessous, dûˋfinie dans le fichier idt.h, sert û crûˋer les descripteurs d'interruption. Notez lû encore la prûˋsence de la directive __attribute__ ((packed)) pour empûˆcher gcc d'insûˋrer des octets de padding au sein de la structureô :
/* descripteur de segment */
struct idtdesc {
ô ô u16 offset0_15; ô ô
ô ô u16 select;
ô ô u16 type;
ô ô u16 offset16_31; ô ô
} __attribute__ ((packed));La fonction init_idt_desc() sert û initialiser les descripteurs systû´me.
void init_idt_desc(u16 select, u32 offset, u16 type, struct idtdesc* desc) {
ô ô desc->offset0_15 = (offset & 0xffff);
ô ô desc->select = select;
ô ô desc->type = type;
ô ô desc->offset16_31 = (offset & 0xffff0000) >> 16;
ô ô return;
}Par exemple, pour initialiser le descripteur associûˋ û l'IRQ 1 (interruptions clavier), on utilise le code suivantô :
init_idt_desc(0x08, (u32) _asm_irq_1, INTGATE, &kidt[33]); /* clavier */- le premier argument pointe sur le descripteur de segment de code qui contient la routine de gestion de l'interruption (dans notre cas le descripteur est û l'offset 0x08 dans la GDT)ô ;
- le deuxiû´me argument est l'offset par rapport au dûˋbut du segment de code pour trouver le dûˋbut de la routine. Cet offset correspond au nom de la fonction û exûˋcuterô ;
- le troisiû´me argument comprend le type de descripteur dans l'IDT (ici interrupt gate) et le niveau de privilû´ge du segmentô ;
- le dernier argument correspond au descripteur û initialiser.
VIII-B-2. Crûˋer une routine d'interruption (ISR)▲
Lors d'une interruption, un vecteur est transmis par le PIC au processeur pour exûˋcuter la bonne ISR. Une ISR obûˋit û deux contraintes particuliû´resô :
- une fois l'interruption traitûˋe, il faut avertir le contrûÇleur de la fin du traitement de l'interruption en lui envoyant un message End of Interrupt (EOI)ô ;
- une routine d'interruption doit retourner en utilisant la directive assembleur iret (au lieu de ret, utilisûˋ habituellement lors de l'appel û une fonction).
Pour envoyer au contrûÇleur un message EOI, indiquant que l'interruption en cours a ûˋtûˋ traitûˋe, on utilise le code assembleur suivantô :
; envoyer EOI au PIC
ô ô mov al, 0x20
ô ô out 0x20, alEn revanche, pour retourner de la routine d'interruption, rien en C ne nous permet d'utiliser iret. La routine d'interruption appelûˋe doit donc ûˆtre ûˋcrite en assembleur. Par exemple, pour gûˋrer l'interruption de l'IRQ 1ô :
_asm_irq_1:
ô ô call isr_kbd_int
ô ô mov al,0x20 ô ; EOI
ô ô out 0x20,al
ô ô iretCe code appelle la fonction isr_kbd_int() qui effectue rûˋellement la gestion de l'interruption du clavier, puis elle envoie un EOI au contrûÇleur avant de retourner. La partie de code en assembleur ne fait donc qu'encapsuler le code ûˋcrit en C dans le fichier interrupt.c.
#include "types.h"
#include "screen.h"
void isr_default_int(void)
{
ô ô ô ô print("interrupt\n");
}
void isr_clock_int(void)
{
ô ô ô ô static int tic = 0;
ô ô ô ô static int sec = 0;
ô ô ô ô tic++;
ô ô ô ô if (tic % 100 == 0) {
ô ô ô ô ô ô ô ô sec++;
ô ô ô ô ô ô ô ô tic = 0;
ô ô ô ô ô ô ô ô print("clock\n");
ô ô ô ô }
}
void isr_kbd_int(void)
{
ô ô ô ô print("keyboard\n");
}Les routines en assembleur sont dans le fichier int.asm.
extern isr_default_int, isr_clock_int, isr_kbd_int
global _asm_default_int, _asm_irq_0, _asm_irq_1
_asm_default_int:
ô ô ô ô call isr_default_int
ô ô ô ô mov al,0x20
ô ô ô ô out 0x20,al
ô ô ô ô iret
_asm_irq_0:
ô ô ô ô call isr_clock_int
ô ô ô ô mov al,0x20
ô ô ô ô out 0x20,al
ô ô ô ô iret
_asm_irq_1:
ô ô ô ô call isr_kbd_int
ô ô ô ô mov al,0x20
ô ô ô ô out 0x20,al
ô ô ô ô iretEst-on vraiment obligûˋs d'utiliser, pour chaque routine d'interruption, ces enveloppes en assembleur et n'est-il pas plus rapide d'inclure dans le code en C une directive du type asm("iret")ô ? Le problû´me est qu'en sortant d'une fonction de cette faûÏon, on oublie de restaurer convenablement les registres, dont le pointeur de pile esp.
VIII-B-3. Initialiser l'IDT avec la fonction init_idt()▲
La fonction init_idt() effectue l'initialisation des descripteurs systû´me et le chargement de l'IDT. ûtant donnûˋ leur similaritûˋ, le code nûˋcessaire pour initialiser et charger l'IDT ressemble beaucoup û celui utilisûˋ pour l'initialisation de la GDT. û l'exception des descripteurs associûˋs aux IRQ 0 et 1 (respectivement l'horloge et le clavier), l'ensemble des descripteurs pointent vers un handler d'interruption par dûˋfautô :
for (i = 0; i < IDTSIZE; i++) ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô /* defaut */
ô ô ô ô init_idt_desc(0x08, (u32) _asm_default_int, INTGATE, &kidt[i]);
init_idt_desc(0x08, (u32) _asm_irq_0, INTGATE, &kidt[32]); ô ô ô /* horloge */
init_idt_desc(0x08, (u32) _asm_irq_1, INTGATE, &kidt[33]); ô ô ô /* clavier */VIII-C. Le programme principal du noyau▲
#include "types.h"
#include "gdt.h"
#include "screen.h"
#include "io.h"
#include "idt.h"
void init_pic(void);
int main(void);
void _start(void)
{
ô ô ô ô kY = 16;
ô ô ô ô kattr = 0x0E;
ô ô ô ô init_idt();
ô ô ô ô print("kernel : idt loaded\n");
ô ô ô ô init_pic();
ô ô ô ô print("kernel : pic configured\n");
ô ô ô ô /* initialisation de la GDT et des segments */
ô ô ô ô init_gdt();
ô ô ô ô /* Initialisation du pointeur de pile %esp */
ô ô ô ô asm("ô ô movw $0x18, %ax \n \
ô ô ô ô ô ô ô ô movw %ax, %ss \n \
ô ô ô ô ô ô ô ô movl $0x20000, %esp");
ô ô ô ô main();
}
int main(void)
{
ô ô ô ô print("kernel : gdt loaded\n");
ô ô ô ô sti;
ô ô ô ô kattr = 0x47;
ô ô ô ô print("kernel : allowing interrupt\n");
ô ô ô ô kattr = 0x07;
ô ô ô ô while (1);
}- La fonction init_gdt() rûˋinitialise la GDT puis la fonction init_idt() configure et charge la table IDT des descripteurs d'interruptions.
- Les chipsets 8259A (maûÛtre et esclave) sont reprogrammûˋs par la fonction init_pic(). Cette fonction, dûˋfinie dans le fichier pic.c, initialise les contrûÇleurs d'interruption maûÛtre et esclave de la faûÏon dûˋcrite au chapitre prûˋcûˋdentProgrammer les interruptions du processeur i386 avec le contrûÇleur d'interruptions 8259A.
- Une fois les PIC configurûˋs et la table IDT en mûˋmoire, on rûˋactive les interruptions avec la macro sti.
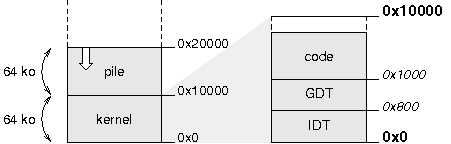
Le schûˋma ci-dessous rûˋsume l'organisation des donnûˋes en mûˋmoire physique aprû´s les initialisationsô :
|
|
VIII-C-1. Compiler et exûˋcuter le noyau▲
tar xfz kernel_ManageINT.tgz
cd ManageINT
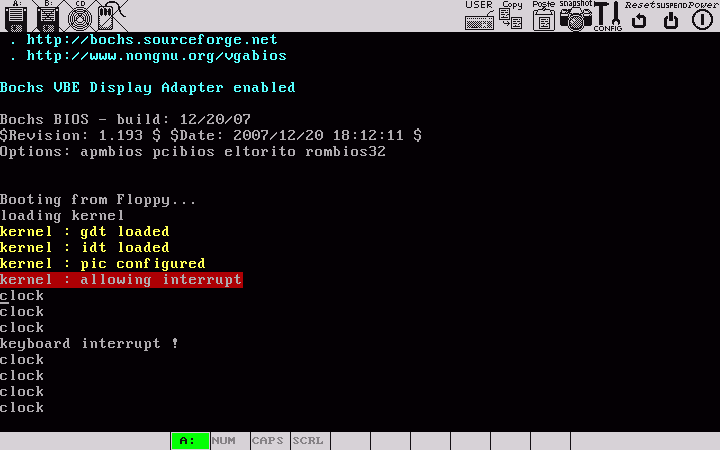
makeû l'exûˋcution du noyau, un tic est affichûˋ toutes les 100 interruptions de l'horloge. En revanche, pour le moment, l'appui d'une touche du clavier ne fonctionne qu'une seule fois. Nous verrons plus tard comment gûˋrer correctement le clavierô :
|
|
IX. Gûˋrer les interruptions du clavier▲
Sourcesô
Le package contenant les sourcesô : kernel_ManageKBD.tgz
IX-A. Le chipset 8042▲
Le clavier contient un microcontrûÇleur chargûˋ de gûˋrer les diffûˋrents ûˋvûˋnements (pression, relûÂchement des touches et affichages lumineux)ô : le 8042. Les ports d'entrûˋe/sortie utilisûˋs pour communiquer avec ce chipset sont les suivantsô :
- 60h pour la lecture ou la transmission de donnûˋesô ;
- 64h pour connaûÛtre le statut ou ûˋmettre des commandes.
Quand une touche est pressûˋe ou relûÂchûˋe, le contrûÇleur ûˋcrit dans son registre de donnûˋes un code appelûˋ scan code. Le contenu de ce registre est accessible via le port 60hô :
i = inb(0x60);La routine suivante attend que le buffer de sortie du 8042 soit plein puis stocke le contenu de celui-ciô :
do {
ô ô i = inb(0x64);
} while((i & 0x01) == 0);
i = inb(0x60);Il existe deux types de scan codeô :
- la pression d'une touche gûˋnû´re un make codeô ;
- le relûÂchement d'une touche gûˋnû´re un break code (break_code = make_code + 0x80).
La routine d'interruption complû´te pour la gestion des interruptions du clavierô : isr_kbd_int()
#include "types.h"
#include "screen.h"
#include "io.h"
#include "kbd.h"
void isr_default_int(void)
{
ô ô ô ô print("interrupt\n");
}
void isr_clock_int(void)
{
ô ô ô ô static int tic = 0;
ô ô ô ô static int sec = 0;
ô ô ô ô tic++;
ô ô ô ô if (tic % 100 == 0) {
ô ô ô ô ô ô ô ô sec++;
ô ô ô ô ô ô ô ô tic = 0;
ô ô ô ô }
}
void isr_kbd_int(void)
{
ô ô ô ô uchar i;
ô ô ô ô static int lshift_enable;
ô ô ô ô static int rshift_enable;
ô ô ô ô static int alt_enable;
ô ô ô ô static int ctrl_enable;
ô ô ô ô do {
ô ô ô ô ô ô ô ô i = inb(0x64);
ô ô ô ô } while ((i & 0x01) == 0);
ô ô ô ô i = inb(0x60);
ô ô ô ô i--;
ô ô ô ô //// putcar('\n'); dump(&i, 1); putcar(' ');
ô ô ô ô if (i < 0x80) {ô ô ô ô ô /* touche enfoncûˋe */
ô ô ô ô ô ô ô ô switch (i) {
ô ô ô ô ô ô ô ô case 0x29:
ô ô ô ô ô ô ô ô ô ô ô ô lshift_enable = 1;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô case 0x35:
ô ô ô ô ô ô ô ô ô ô ô ô rshift_enable = 1;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô case 0x1C:
ô ô ô ô ô ô ô ô ô ô ô ô ctrl_enable = 1;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô case 0x37:
ô ô ô ô ô ô ô ô ô ô ô ô alt_enable = 1;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô default:
ô ô ô ô ô ô ô ô ô ô ô ô putcar(kbdmap
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô [i * 4 + (lshift_enable || rshift_enable)]);
ô ô ô ô ô ô ô ô }
ô ô ô ô } else {ô ô ô ô ô ô ô ô /* touche relûÂchûˋe */
ô ô ô ô ô ô ô ô i -= 0x80;
ô ô ô ô ô ô ô ô switch (i) {
ô ô ô ô ô ô ô ô case 0x29:
ô ô ô ô ô ô ô ô ô ô ô ô lshift_enable = 0;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô case 0x35:
ô ô ô ô ô ô ô ô ô ô ô ô rshift_enable = 0;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô case 0x1C:
ô ô ô ô ô ô ô ô ô ô ô ô ctrl_enable = 0;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô case 0x37:
ô ô ô ô ô ô ô ô ô ô ô ô alt_enable = 0;
ô ô ô ô ô ô ô ô ô ô ô ô break;
ô ô ô ô ô ô ô ô }
ô ô ô ô }
ô ô ô ô show_cursor();
}IX-B. La gestion du curseur▲
Le curseur est gûˋrûˋ en s'adressant directement au contrûÇleur VGA via le port 0x3d4 (contrûÇle) et le port 0x3d5 (donnûˋes). La routine qui affiche le curseur û l'ûˋcran est trû´s simpleô :
void move_cursor (u8 x, u8 y)
{
ô ô u16 c_pos;
ô ô c_pos = y * 80 + x;
ô ô outb(0x3d4, 0x0f);
ô ô outb(0x3d5, (u8) c_pos);
ô ô outb(0x3d4, 0x0e);
ô ô outb(0x3d5, (u8) (c_pos >> 8));
}
void show_cursor (void)
{
ô ô move_cursor(kX, kY);
}|
|
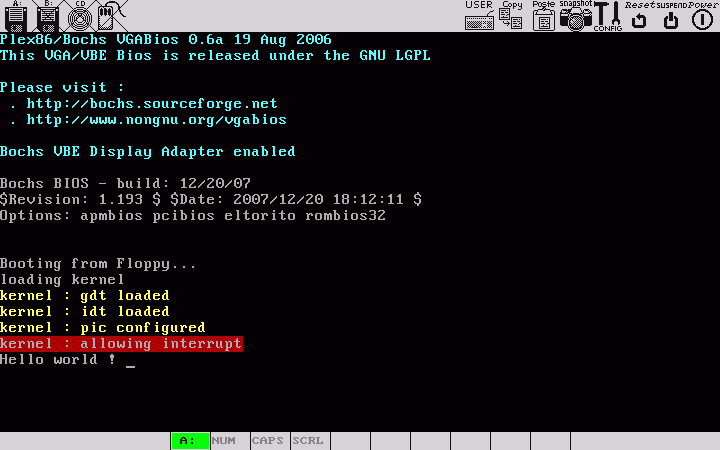
X. Crûˋer une tûÂcheô : un noyau qui exûˋcute une tûÂche utilisateur▲
- Mode noyau et mode utilisateurMode noyau et mode utilisateur
- Dûˋfinir des segments de mûˋmoire distinctsDûˋfinir des segments de mûˋmoire distincts
- Copier le code exûˋcutable en RAMCopier le code exûˋcutable en RAM
- Crûˋer et initialiser un TSSCrûˋer et initialiser un TSS
- Exûˋcuter une tûÂcheExûˋcuter une tûÂche
- Sauvegarder le contexte d'une tûÂcheSauvegarder le contexte d'une tûÂche
- Compiler et exûˋcuter le noyauCompiler et exûˋcuter le noyau
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_MonoTask.tgz
X-A. Mode noyau et mode utilisateur▲
X-A-1. Pourquoiô ?▲
Nous avons vu comment crûˋer un programme qui peut û tout moment accûˋder û n'importe quel endroit de la mûˋmoire et exûˋcuter n'importe quelle instruction. Cette libertûˋ a un prixô : le risque de corrompre des donnûˋes ou d'exûˋcuter une instruction indûˋsirable. Si ce risque est un mal nûˋcessaire pour le noyau qui doit nûˋcessairement pouvoir tout faire, il n'est pas souhaitable que le code d'un utilisateur bûˋnûˋficie des mûˆmes permissions. Ce dernier ne doit pas pouvoir accûˋder aux donnûˋes des autres utilisateurs ou corrompre l'ensemble du systû´me (intentionnellement ou non).
On distingue deux types de modes d'exûˋcution d'un programmeô : le mode noyau (ou privilûˋgiûˋ ou encore superviseur) et le mode utilisateurô :
- le code en mode noyau a un accû´s total û la machine (mûˋmoire, instructions, pûˋriphûˋriques)ô ;
- le code en mode utilisateur n'a qu'un accû´s limitûˋ û la mûˋmoire et il ne peut pas exûˋcuter certaines instructions dangereuses.
Par exemple, sur un systû´me de type Unix, un programme utilisateur peut seulement accûˋder û ses propres donnûˋes et il ne peut pas, par exemple, rebooter la machine.
X-A-2. Commentô ?▲
La famille de processeur i386 offre plusieurs mûˋthodes pour exûˋcuter du code en mode utilisateur. La mûˋthode dûˋcrite ici est celle du software task switching. Pour commuter une tûÂche par cette mûˋthode, le noyau doitô :
- Dûˋfinir les segments de mûˋmoire utilisables par la tûÂcheô ;
- Copier la tûÂche (le code exûˋcutable et les donnûˋes) en mûˋmoireô ;
- Crûˋer et initialiser la structure TSSô ;
- Empiler certaines valeurs clefs permettant la commutation sur la pileô ;
- Commuter grûÂce û l'instruction iret.
Cela peut sembler un peu compliquûˋ, mais pourtant il n'en est rien. Ces diffûˋrents points sont expliquûˋs en dûˋtail ci-dessous.
X-B. Dûˋfinir des segments de mûˋmoire distincts▲
Dans les chapitres prûˋcûˋdents, nous avons vu comment utiliser le mûˋcanisme de segmentation pour adresser l'ensemble de la mûˋmoire en mode protûˋgûˋ. Le mûˋcanisme de segmentation permet de restreindre la mûˋmoire accessible par une tûÂche utilisateur en lui associant des descripteurs de segment dont les champs base et limite dûˋfinissent une plage de mûˋmoire restreinte. La sûˋcurisation est ûˋgalement ûˋtendue par l'utilisation du champ DPL des descripteurs qui permet d'empûˆcher l'utilisation de certaines instructions critiques.
Dans notre implûˋmentation, nous avons une seule tûÂche en mode utilisateur dont l'espace accessible est restreint û ô :
- un segment de code de 4Kô ;
- un segment de donnûˋes de 4K confondu avec le segment de codeô ;
- un segment de pile de 4K.
Le noyau, quant û lui, peut adresser l'ensemble de la mûˋmoire (cela n'est pas clairement reprûˋsentûˋ dans le schûˋma ci-dessous)ô :
|
|
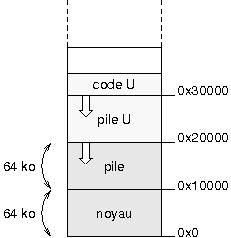
Les descripteurs de segment associûˋs û la tûÂche utilisateur sont crûˋûˋs et initialisûˋs de la faûÏon suivanteô :
/* descripteur de segments en mode utilisateur */
init_gdt_desc(0x30000, 0x0, 0xFF, 0x0D, &kgdt[4]); /* ucode */
init_gdt_desc(0x30000, 0x0, 0xF3, 0x0D, &kgdt[5]); /* udata */
init_gdt_desc(0x0, 0x20, ô ô 0xF7, 0x0D, &kgdt[6]); /* ustack */X-C. Copier le code exûˋcutable en RAM▲
Pour cette premiû´re implûˋmentation, la tûÂche utilisateur est une fonction trû´s simple qui boucle sur elle-mûˆmeô :
void task1(void)
{
ô ô ô ô while(1);
ô ô ô ô return; /* never go there */
}De faûÏon arbitraire, il a ûˋtûˋ dûˋcidûˋ que le code de la tûÂche doit rûˋsider en 0x30000. Pour le moment, nous n'avons pas vraiment de moyen de crûˋer un exûˋcutable et de le charger en mûˋmoire via un chargeur ELF ou quelque chose de similaire. Nous allons donc tout simplement crûˋer une fonction dans le noyau et copier le code de cette fonction û l'endroit voulu. Comme c'est une toute petite fonction qui occupe au maximum 100 octets, elle est chargûˋe en mûˋmoire par le code suivantô :
/* Copie de la fonction a son adresse */
ô ô ô ô memcpy((char*) 0x30000, &task1, 100); /* copie de 100 instructions */X-D. Crûˋer et initialiser un TSS▲
Le TSS (Task State Segment) est une structure qui permet de garder en mûˋmoire l'ûˋtat des registres lors d'une commutation de tûÂche ou d'une interruption. Dans notre cas, le TSS va uniquement servir û garder en mûˋmoire les indications relatives û la pile du noyau (û savoir les valeurs des registres SS et ESP). Cette structure, utilisûˋe de faûÏon assez diverse selon l'implûˋmentation de la commutation de tûÂche, peut rûˋsider n'importe oû¿ en mûˋmoire. Elle est localisable grûÂce û un descripteur particulier dans la GDTô : le descripteur de TSS. Un sûˋlecteur de segment spûˋcifique, le Task Register (TR), permet de pointer sur ce descripteurô :
|
|
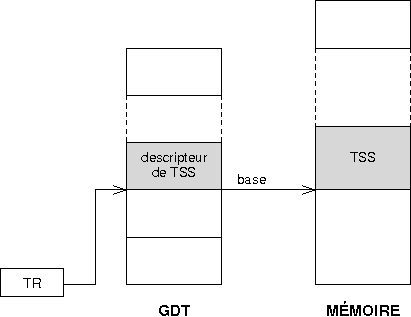
X-D-1. Descripteur de TSS▲
|
|
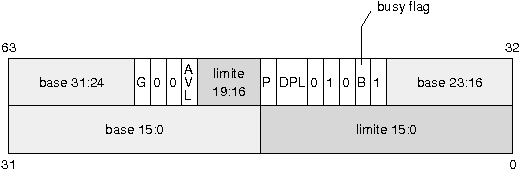
X-D-2. Initialiser le TSS▲
L'initialisation du TSS se fait en plusieurs ûˋtapesô :
-
Crûˋation et initialisation de la structure du TSS
Sélectionnezstructtss{ô ô u16 ô ô previous_task, __previous_task_unused; ô ô u32 ô ô esp0; ô ô u16 ô ô ss0, __ss0_unused; ô ô u32 ô ô esp1; ô ô u16 ô ô ss1, __ss1_unused; ô ô u32 ô ô esp2; ô ô u16 ô ô ss2, __ss2_unused; ô ô u32 ô ô cr3; ô ô u32 ô ô eip, eflags, eax, ecx, edx, ebx, esp, ebp, esi, edi; ô ô u16 ô ô es, __es_unused; ô ô u16 ô ô cs, __cs_unused; ô ô u16 ô ô ss, __ss_unused; ô ô u16 ô ô ds, __ds_unused; ô ô u16 ô ô fs, __fs_unused; ô ô u16 ô ô gs, __gs_unused; ô ô u16 ô ô ldt_selector, __ldt_sel_unused; ô ô u16 ô ô debug_flag, io_map;}__attribute__((packed));Sélectionnezstructtss default_tss; ô ô default_tss.debug_flag=0x00; ô ô default_tss.io_map=0x00; ô ô default_tss.esp0=0x20000; ô ô default_tss.ss0=0x18; -
Crûˋation du descripteur de TSS
Sélectionnezinit_gdt_desc((u32)&default_tss,0x67,0xE9,0x00,&kgdt[7]);/* descripteur de tss */ -
Chargement du registre TR û l'aide de l'instruction ltr
Sélectionnezasm("ô movw $0x38, %ax\n\ô ô ô ô ltr %ax"); - La mise û jour du segment et du pointeur de pile noyau du TSS (champs ss0 et esp0 du TSS) avec les valeurs courantes se fait trû´s simplementô :
asm(" ô movw %%ss, %0 \n \
ô ô ô ô movl %%esp, %1" : "=m" (default_tss.ss0), "=m" (default_tss.esp0) : );X-E. Exûˋcuter une tûÂche▲
Intel(c) propose plusieurs mûˋcanismes pour effectuer une commutation de tûÂche. La commutation hardware est ô¨ô presqueô ô£ entiû´rement gûˋrûˋe par le processeur. Elle est cependant rarement utilisûˋe, carô :
- sa mise en éuvre est paradoxalement plutûÇt difficileô ;
- le nombre de processus est limitûˋ par la taille de la GDT.
La commutation logicielle, û l'inverse, est comparativement simple û mettre en éuvre et n'a pas de limitation concernant le nombre de processus possible. Pour commuter une tûÂche de faûÏon logicielle, il suffit deô :
- Empiler certaines valeurs clefs sur la pileô ;
- Commuter grûÂce û l'instruction iret.
X-E-1. Simuler un retour d'interruption pour changer de tûÂche▲
L'instruction iret sert normalement û retourner d'une interruption. Dans le cas prûˋsent, une petite astuce û la base de notre implûˋmentation va se servir de iret pour donner la main û une tûÂche non privilûˋgiûˋe.
Quand une tûÂche utilisateur s'exûˋcute et qu'une interruption survient, le processeur va automatiquement sauvegarder sur la pile noyau diffûˋrents registres lui permettant de retourner dans le contexte utilisateur une fois le traitement de l'interruption terminûˋô :
|
|
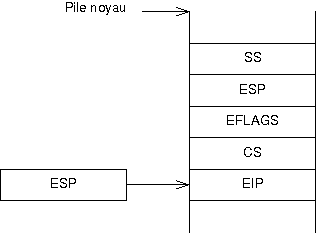
Une fois l'interruption traitûˋe, l'instruction iret fait les choses suivantesô :
- Le processeur dûˋpile les registres EIP et CSô ;
- Il vûˋrifie s'il y a un changement de privilû´geô ;
- Il met û jour les registres EIP et CSô ;
- Il dûˋpile et met û jour le registre EFLAGSô ;
- En cas de changement de privilû´ge, il dûˋpile et met û jour les registres SS et ESP.
Pour commuter en mode non privilûˋgiûˋ, il suffit donc deô :
- Empiler des registres SS et ESP qui pointent sur la pile utilisateurô ;
- Empiler un registre d'ûˋtat EFLAGS valideô ;
- Empiler des registres CS et EIP qui pointent vers le code utilisateurô ;
- Exûˋcuter iret.
Le code ci-dessous effectue un saut vers la fonction task1() en mode utilisateurô :
asm(" ô cli \n \
ô ô ô ô ô ô push $0x33 \n \
ô ô ô ô ô ô push $0x30000 \n \
ô ô ô ô ô ô pushfl \n \
ô ô ô ô ô ô popl %?x \n \
ô ô ô ô ô ô orl $0x200, %?x \n \
ô ô ô ô ô ô and $0xffffbfff, %?x \n \
ô ô ô ô ô ô push %?x \n \
ô ô ô ô ô ô push $0x23 \n \
ô ô ô ô ô ô push $0x0 \n \
ô ô ô ô ô ô movl $0x20000, %0 \n \
ô ô ô ô ô ô movw $0x2B, %%ax \n \
ô ô ô ô ô ô movw %%ax, %%ds \n \
ô ô ô ô ô ô iret" : "=m" (default_tss.esp0) : );X-E-1-a. Le code vu pas û pas▲
asm(" ô cli \n \On commence par dûˋsactiver les interruptions.
push $0x33 \n \
push $0x30000 \n \Nous avons vu plus haut que le descripteur de segment de pile est û l'offset 0x30 dans la GDT et qu'il dûˋfinit un espace mûˋmoire de 4ô K dûˋbutant û l'adresse 0x20000. Le sommet de la pile est donc en 0x30000. On commence par placer le futur sûˋlecteur et le futur pointeur de pile utilisateur sur la pile noyau.
Lors de l'appel û iret, nous voulons que le processeur mette û jour le segment de pile SS avec celui qui est û l'index 0x30 de la GDT (la pile utilisateur). Mais nous voulons aussi que le processeur passe û un niveau d'exûˋcution diffûˋrent (ici, moins privilûˋgiûˋ). On indique ce niveau d'exûˋcution au processeur en l'ajoutant dans le champ RPL (Requested Privilege Level) du sûˋlecteurô :
|
|

Dans notre exemple, nous voulons passer en mode utilisateur (valeur de privilû´ge 3, on parle aussi de passer en mode ring 3). Il faut donc utiliser le sûˋlecteur 0x30 + 3 = 0x33 pour utiliser le segment de pile utilisateur en tant qu'utilisateur. Sans cela, le processeur va dûˋclencher une exception de type General Protection fault.
pushfl ô ô ô ô ô ô \n \
popl %?x ô ô ô ô \n \
orl $0x200, %?x \n \
and $0xffffbfff, %?x \n \
push %?x ô ô ô ô \n \On place le registre EFLAGS sur la pile en ayant pris soin de dûˋsactiver le bit Nested Task (NT) et en ayant activûˋ le bit Interrupt Flag (IF).
push $0x23 \n \
push $0x0 \n \On place sur la pile le sûˋlecteur et le pointeur de code utilisateur. Comme avec le segment de pile, nous voulons que le processeur passe û un niveau d'exûˋcution diffûˋrent, ici moins privilûˋgiûˋ. On indique ce niveau de privilû´ge, ici 3, au processeur en l'ajoutant û la valeur du sûˋlecteur. Dans notre exemple, il faut donc utiliser le sûˋlecteur 0x20 + 3 = 0x23 pour utiliser le segment de code utilisateur avec un niveau de privilû´ge de 3.
û ce stade-lû , la pile est prûˆte pour basculer vers la tûÂche utilisateur.
movl $0x20000, %0 \n \Cette instruction met û jour la valeur de default_tss.esp0, qui contient la valeur du pointeur de pile noyau utilisûˋ par les interruptions pendant que la tûÂche utilisateur s'exûˋcute.
movw $0x2B, %%ax \n \
movw %%ax, %%ds \n \On initialise le sûˋlecteur de segment de donnûˋes en le faisant pointer sur le descripteur de la partie utilisateur. On applique la mûˆme remarque que vu prûˋcûˋdemment avec les segments de code et de pile et on utilise donc le sûˋlecteur 0x28 + 3 = 0x2B.
iret" : "=m" (default_tss.esp0) : );L'instruction iret est normalement utilisûˋe pour retourner d'une interruption. Elle dûˋpile l'adresse de retour (CS et EIP), le registre EFLAGS et les informations de pile (SS et ESP). On note queô :
- le bit NT du registre EFLAGS doit ûˆtre dûˋsactivûˋ pour ûˋviter que le processeur fasse une commutation de tûÂche hardwareô ;
- le bit IF du registre EFLAGS doit ûˆtre activûˋ pour autoriser les interruptions une fois en mode utilisateur.
X-F. Sauvegarder le contexte d'une tûÂche▲
X-F-1. Des interruptions qui sauvegardent la tûÂche en cours▲
Quand le processeur est en mode utilisateur et qu'une interruption est reûÏue, il doit passer en mode privilûˋgiûˋ pour exûˋcuter l'ISR appropriûˋe. En cas de changement de privilû´ge, le processeur fait automatiquement les choses suivantesô :
- Il rûˋcupû´re dans le TSS les valeurs des champs ss0 et esp0 correspondant aux registres SS et ESP de la pile noyauô ;
- Il bascule sur la pile noyau et il empile dessus les registres SS, ESP, EFLAGS, CS et EIP liûˋs û la tûÂche utilisateurô ;
- Dans certains cas, il empile un code d'erreurô ;
- Il exûˋcute l'ISR.
Mais cela n'est pas suffisant. Pour sauvegarder entiû´rement le contexte d'exûˋcution de la tûÂche utilisateur, il faut stocker quelque part, par exemple en les empilant sur la pile noyau, les autres registres du processeur susceptibles d'ûˆtres modifiûˋs par la routine d'interruption.
Pour illustrer ce point, û l'origine notre handler pour l'interruption IRQ0 ûˋtaitô :
_asm_irq_0:
ô ô call isr_clock_int
ô ô mov al,0x20
ô ô out 0x20,al
ô ô iretNous devons le modifier afin qu'il sauvegarde les registres (on remarque aussi qu'il initialise le sûˋlecteur de segment de donnûˋes DS afin que le noyau puisse accûˋder au segment de donnûˋes)ô :
%macro ô SAVE_REGS 0
ô ô ô ô pushad
ô ô ô ô push ds
ô ô ô ô push es
ô ô ô ô push fs
ô ô ô ô push gs
ô ô ô ô push ebx
ô ô ô ô mov bx,0x10
ô ô ô ô mov ds,bx
ô ô ô ô pop ebx
%endmacro
%macro ô RESTORE_REGS 0
ô ô ô ô pop gs
ô ô ô ô pop fs
ô ô ô ô pop es
ô ô ô ô pop ds
ô ô ô ô popad
%endmacro
_asm_irq_0:
ô ô ô ô SAVE_REGS
ô ô ô ô call isr_clock_int
ô ô ô ô mov al,0x20
ô ô ô ô out 0x20,al
ô ô ô ô RESTORE_REGS
ô ô ô ô iretX-G. Compiler et exûˋcuter le noyau▲
La compilation n'apporte aucune surpriseô :
tar xfz kernel_MonoTask.tgz
cd MonoTask
makeEn revanche, pour tester le nouveau noyau, il faut utiliser Bochs en mode debug. La fenûˆtre ci-dessous montre ce qui se passe aprû´s l'exûˋcution de l'instruction iret. L'instruction d'aprû´s est en mode utilisateur et adresse le bon segment de code. Un point est affichûˋ toutes les 100 interruptions d'horloge, ce qui prouve que les interruptions fonctionnent correctement malgrûˋ le passage en mode utilisateurô :
|
|
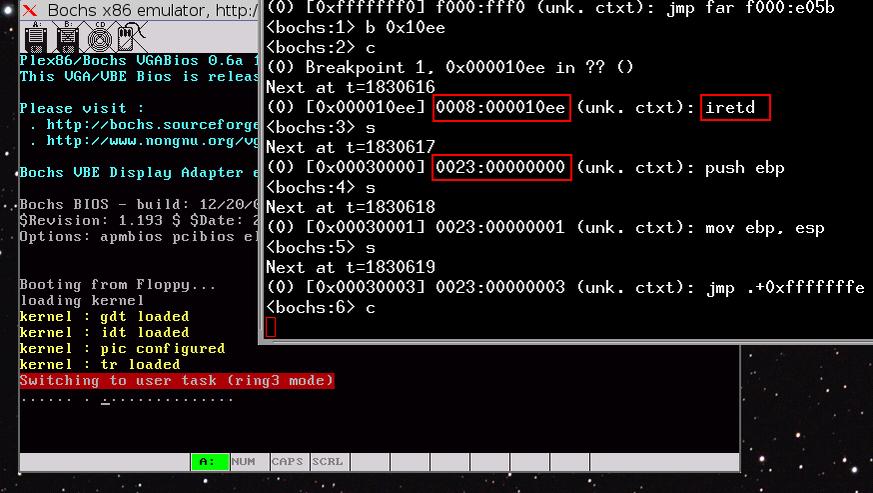
XI. Les appels systû´meô : un noyau monotûÂche qui implûˋmente des appels systû´me▲
- Des appels systû´me pour accûˋder aux services du noyauDes appels systû´me pour accûˋder aux services du noyau
- Charger une tûÂcheCharger une tûÂche
- Exûˋcuter le noyauExûˋcuter le noyau
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_MonoTask_Syscall.tgz
En 64 bits, l'appel aux services systû´me diffû´re. On ne passe pas par des interruptions logicielles, mais par l'instruction SYSENTER. Les registres utilisûˋs pour le passage de paramû´tres (eax pour le numûˋro d'appel, puis ebx, ecx, edx, esi, edi, ebp en 32 bits, rax pour le numûˋro d'appel, puis rdi, rsi, rdx, rcx, r8, et r9 en 64 bits).
XI-A. Des appels systû´me pour accûˋder aux services du noyau▲
XI-A-1. Pourquoiô ?▲
Le mûˋcanisme de segmentation empûˆche le code utilisateur d'accûˋder librement aux pûˋriphûˋriques ou au noyau. Pour accûˋder û ces ressources, par exemple pour ûˋcrire dans la mûˋmoire vidûˋo ou sur disque, le code utilisateur utilise des services implûˋmentûˋs au niveau du noyauô : les appels systû´me. Le noyau illustrûˋ ici implûˋmente un appel systû´me permettant d'afficher un message û l'ûˋcran.
XI-A-2. Appeler une routine privilûˋgiûˋe û l'aide d'une interruption logicielle▲
Nous avons vu aux chapitres prûˋcûˋdents que des interruptions peuvent ûˆtre dûˋclenchûˋes par les pûˋriphûˋriques ou directement par le processeur en cas d'exception. Un troisiû´me type d'interruption existe, ce sont les interruptions logicielles, dûˋclenchûˋes volontairement par le code noyau ou utilisateur û l'aide de l'instruction int. Ce sont ces interruptions qui vont nous servir pour implûˋmenter les appels systû´me.
XI-A-3. Une interruption logicielle qui utilise un Trap Gate▲
Nous avons dûˋjû dûˋtaillûˋ la faûÏon dont fonctionnent les interruptions matûˋrielles. Les interruptions logicielles fonctionnent exactement de la mûˆme faûÏon û deux diffûˋrences prû´sô :
- nous allons utiliser un descripteur de Trap Gate au lieu d'un descripteur de type Interrupt Gate. La seule diffûˋrence entre les deux est qu'un Trap Gate ne dûˋsactive pas les interruptionsô ;
- nous allons initialiser diffûˋremment le champ DPL du descripteur.
XI-A-3-a. Descripteur systû´me de type Trap Gate▲
|
|
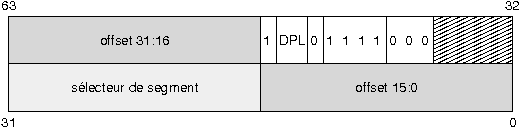
Le DPL (Descriptor Privilege Level) est utilisûˋ pour contrûÇler l'accû´s au segment selon le niveau de privilû´ge du code appelant. La valeur 3 indique que toutes les applications, mûˆme les moins privilûˋgiûˋes, peuvent utiliser le trap gate tandis que la valeur 0 restreint son utilisation au seul code noyau. Comme nous voulons que le trap gate soit utilisable par les applications utilisateur, il faut un DPL de 3ô :
|
|
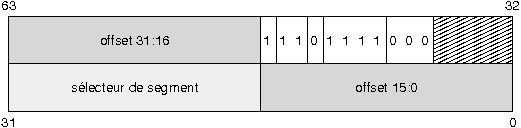
Il est initialisûˋ û l'aide du code suivantô :
init_idt_desc(0x08, (u32) _asm_syscalls, 0xEF00, &kidt[48]); /* appels systeme - int 0x30 */GrûÂce û ce descripteur, suite û une interruption de type int 0x30, le processeur va exûˋcuter la routine de service _asm_syscalls.
XI-A-4. Comment passer des paramû´tres û l'appel systû´meô ?▲
Nous avons vu ci-dessus qu'un appel systû´me se fait trû´s simplement grûÂce aux interruptions logicielles. Le noyau peut ainsi fournir des services aux applications utilisateur, mais comment passer des paramû´tres û ces servicesô ? Deux solutions sont trû´s courantesô :
- passer les paramû´tres via la pile utilisateurô ;
- passer les paramû´tres en les plaûÏant dans les registres, la plus simple û implûˋmenter.
Nous allons voir comment implûˋmenter la deuxiû´me solution. Elle a le mûˋrite d'ûˆtre simple, mais le nombre rûˋduit de registres sur les architectures i386 limite le nombre de paramû´tres que l'on peut passer par cette mûˋthode (eax, ebx, ecx, edx, edi et esi).
Dans notre implûˋmentation d'un appel systû´me qui affiche une chaûÛne de caractû´res û l'ûˋcran, les registres utilisûˋs sontô :
- eax, qui contient le numûˋro d'appel systû´meô ;
- ebx, qui contient l'adresse de la chaûÛne de caractû´res û afficher.
Le code qui rûˋalise l'appelô :
asm("mov %0, %?x; mov $0x01, %?x; int $0x30" :: "m" (msg));XI-A-5. La routine d'interruption (1)▲
La routine de traitement de l'interruption est semblable û celle dûˋjû vue pour les interruptions matûˋrielles. Elle commence par sauvegarder les registres utilisateur et par initialiser le registre DS pour qu'il pointe sur le segment de donnûˋes du noyau. Ensuite, elle pousse sur la pile le registre eax, qui contient le numûˋro de l'appel systû´me, pour le transmettre û la fonction do_syscalls() appelûˋe juste aprû´sô :
_asm_syscalls:
ô ô ô ô SAVE_REGS
ô ô ô ô push eax ô ô ô ô ô ô ô ô ; transmission du numûˋro d'appel
ô ô ô ô call do_syscalls
ô ô ô ô pop eax
ô ô ô ô RESTORE_REGS
ô ô ô ô iretXI-A-6. La routine d'interruption (2)▲
La fonction do_syscalls() effectue le vrai travail de gestion de l'interruption. Le principe de cette fonction est simpleô :
- dûˋterminer l'appel systû´me grûÂce au numûˋro passûˋ en argument û la fonctionô ;
- rûˋcupûˋrer les paramû´tres de l'appel, placûˋs dans les registres et poussûˋs sur la pile
#include "types.h"
#include "gdt.h"
#include "screen.h"
void do_syscalls(int sys_num)
{
ô ô ô ô u16 ds_select;
ô ô ô ô u32 ds_base;
ô ô ô ô struct gdtdesc *ds;
ô ô ô ô uchar *message;
ô ô ô ô if (sys_num == 1) {
ô ô ô ô ô ô ô ô asm("ô ô mov 44(%?p), %?xô ô \n \
ô ô ô ô ô ô ô ô ô ô ô ô mov %?x, %0ô ô ô ô ô ô \n \
ô ô ô ô ô ô ô ô ô ô ô ô mov 24(%?p), %%axô ô ô \n \
ô ô ô ô ô ô ô ô ô ô ô ô mov %%ax, %1" : "=m"(message), "=m"(ds_select) : );
ô ô ô ô ô ô ô ô ds = (struct gdtdesc *) (GDTBASE + (ds_select & 0xF8));
ô ô ô ô ô ô ô ô ds_base = ds->base0_15 + (ds->base16_23 << 16) + (ds->base24_31 << 24);
ô ô ô ô ô ô ô ô print((char*) (ds_base + message));
ô ô ô ô } else {
ô ô ô ô ô ô ô ô print("syscall\n");
ô ô ô ô }
ô ô ô ô return;
}XI-A-6-a. Que fait exactement cette fonctionô ?▲
void do_syscalls(int sys_num)La ligne ci-dessus permet de rûˋcupûˋrer le numûˋro d'appel systû´me passûˋ en paramû´tre û la fonction (par le biais de l'instruction push eax). Dans notre implûˋmentation, il n'y a pour le moment qu'un appel systû´me, mais un noyau en a gûˋnûˋralement plusieurs dizaines ou centaines.
if (sys_num == 1) {Le bloc traite l'appel systû´me numûˋro 1.
asm(" ô mov 44(%?p), %?xô ô \n \
ô ô ô ô mov %?x, %0ô ô ô ô ô ô \n \
ô ô ô ô mov 24(%?p), %%ax ô ô \n \
ô ô ô ô mov %%ax, %1" : "=m" (message), "=m" (ds_select) : );Dans notre implûˋmentation, les paramû´tres sont passûˋs û l'appel systû´me û l'aide des registres. Nous savons que l'adresse de la chaûÛne û afficher a ûˋtûˋ placûˋe par le programme utilisateur dans le registre EBX. Mais û cet endroit de la fonction do_syscalls, rien ne nous garantit que ce registre n'a pas ûˋtûˋ modifiûˋ. Heureusement, ce registre a ûˋtûˋ sauvegardûˋ sur la pile noyau, ce qui permet de rûˋcupûˋrer sa valeur.
Une fois rûˋcupûˋrûˋe la valeur de EBX, on devrait pouvoir afficher la chaûÛne sans problû´meô ? Eh bien nonô !
La chaûÛne de caractû´res contenant le message û afficher n'est toujours pas accessible, car EBX contient seulement un dûˋplacement et il faut rûˋcupûˋrer l'adresse de la base du segment de donnûˋes utilisateur pour connaûÛtre l'adresse physique exacte oû¿ se situe la chaûÛne. On obtient cette adresse û partir de la valeur sauvegardûˋe du registre DS qui pointe sur le bon descripteur de segment dans la GDT.
Noteô : l'annexe sur les Stack FrameAnnexe D - Gûˋrer les arguments sur la pile avec les Stack Frame explique dans le dûˋtail comment rûˋcupûˋrer des paramû´tres sur la pile.
ds = (struct gdtdesc*) (GDTBASE + (ds_select & 0xF8));
ds_base = ds->base0_15 + (ds->base16_23 << 16) + (ds->base24_31 << 24);û partir de la valeur ds_select, on retrouve l'emplacement du descripteur de segment de donnûˋes dans la GDT. La valeur du registre DS n'est pas utilisûˋe telle quelle, car le champ RPL a ûˋtûˋ positionnûˋ. Pour obtenir l'offset du descripteur dans la GDT, il faut appliquer le masque 0xF8. L'adresse de base est ensuite reconstituûˋe û partir de ses diffûˋrents champs.
print(ds_base + message);Enfin, la fonction print() est appelûˋe avec l'adresse physique de la chaûÛne û afficher.
} else {
ô ô print("syscall\n");
}
return;Pour les autres appels systû´me, on affiche seulement un petit message û l'ûˋcran et la fonction se termine.
XI-B. Charger une tûÂche▲
Le code applicatif est assez simple et affiche simplement un message avant de boucler indûˋfiniment.
Le modû´le d'organisation de la mûˋmoire utilisûˋ est dûˋcrit au chapitre prûˋcûˋdent. Il spûˋcifie que le code applicatif, dûˋfini par la fonction task1(), doit ûˆtre en 0x30000. Comme ce code fait au maximum 100 octets, le noyau le recopie directement û l'adresse voulueô :
/* copie de la fonction a son adresse */
memcpy((char*) 0x30000, (char*) &task1, 100); /* copie de 100 instructions */Les donnûˋes utilisateur, ici le message û afficher, doivent ûˆtre stockûˋes dans le segment entre 0x30000 et 0x31000. En principe, nous aimerions avoir une fonction utilisateur ressemblant û ceciô :
void task1(void)
{
ô ô ô ô char *msg = "hello world !\n";Hûˋlas, û ce stade du dûˋveloppement de notre noyau, ûÏa n'est pas possible, car la fonction task1() fait partie du noyau et n'a pas ûˋtûˋ compilûˋe pour tenir compte du fait qu'elle serait relogûˋe ailleurs. Nous sommes donc obligûˋs de ruser un peu pour stocker la chaûÛne de caractû´res quelque part entre 0x30000 et 0x31000. Arbitrairement (enfin pas tout û fait, nous avons pris soin de prendre une valeur qui n'ûˋcrase pas le code de la fonction), la chaûÛne est placûˋe en 0x30100ô :
void task1(void)
{
ô ô ô ô char *msg = (char*) 0x100; /* le message sera stockûˋ en 0x30100 */
ô ô ô ô msg[0] = 't';
ô ô ô ô msg[1] = 'a';
ô ô ô ô msg[2] = 's';
ô ô ô ô msg[3] = 'k';
ô ô ô ô msg[4] = '1';
ô ô ô ô msg[5] = '\n';
ô ô ô ô msg[6] = 0;
ô ô ô ô asm("mov %0, %?x; mov $0x01, %?x; int $0x30" :: "m" (msg));
ô ô ô ô while(1);
ô ô ô ô return; /* never goes there */
}Une fois la chaûÛne placûˋe en 0x30100, le code peut exûˋcuter l'appel systû´me permettant de l'afficher û l'ûˋcranô :
asm("mov %0, %?x; mov $0x01, %?x; int $0x30" :: "m" (msg));XI-C. Exûˋcuter le noyau▲
La tûÂche en mode utilisateur fait un appel systû´me au service d'affichage, en mode noyau, qui ûˋcrit dans la mûˋmoire vidûˋoô :
|
|
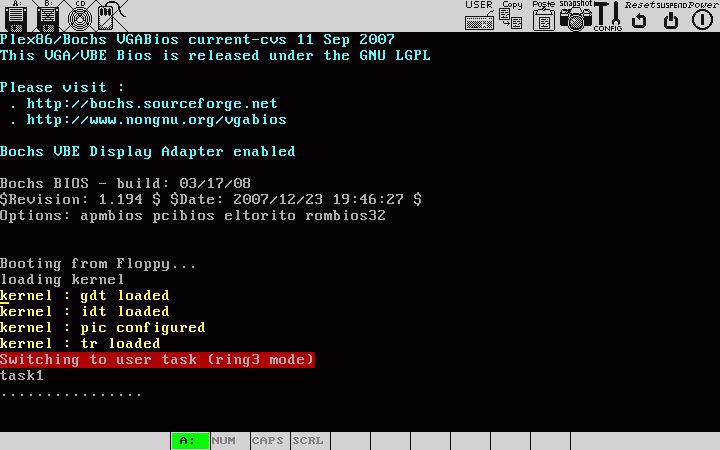
XII. Gûˋrer la mûˋmoire - un noyau qui implûˋmente la pagination▲
- Mûˋmoire virtuelle et mûˋmoire physiqueMûˋmoire virtuelle et mûˋmoire physique
- Une premiû´re implûˋmentation trû´s simpleUne premiû´re implûˋmentation trû´s simple
- Exûˋcuter le noyauExûˋcuter le noyau
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_PagingEnable.tgz
XII-A. Mûˋmoire virtuelle et mûˋmoire physique▲
XII-A-1. Prûˋsentation▲
Nous avons dûˋjû vu que dans le systû´me de segmentation, une adresse physique est calculûˋe û partir d'un sûˋlecteur de segment et d'un offset. Avec la pagination activûˋe, l'adresse obtenue par la segmentation est une adresse linûˋaire qui sera ensuite traduite en une adresse physiqueô :
|
|
La pagination est un mûˋcanisme d'adressage de la mûˋmoire qui permetô :
- de s'affranchir des limites en mûˋmoire de l'ordinateur en utilisant le disque dur comme extensionô ;
- d'affecter û chaque tûÂche son propre espace d'adressageô ;
- d'allouer et de dûˋsallouer dynamiquement de la mûˋmoire de faûÏon simple.
Quand la pagination est activûˋe, le processeur dûˋcoupe l'espace d'adressage linûˋaire (ou virtuel) et la mûˋmoire physique en pages de taille fixe (gûˋnûˋralement 4ko ou 4Mo) qui peuvent ûˆtre associûˋes librement. La traduction des adresses linûˋaires en adresses physiques est rûˋalisûˋe par le processeur grûÂce û plusieurs structuresô :
- le rûˋpertoire de pages (Page Directory) est un tableau dont les entrûˋes pointent vers des tables de pages. Son adresse est stockûˋe dans le registre CR3ô ;
- les tables de pages (Page Table) sont des tableaux dont les entrûˋes sont des pointeurs vers des pages.
Le schûˋma ci-dessous illustre l'association entre des pages en mûˋmoire linûˋaire (ou virtuelle) et en mûˋmoire physique par l'unitûˋ de pagination de la MMU (Memory Management Unit)ô :
|
|
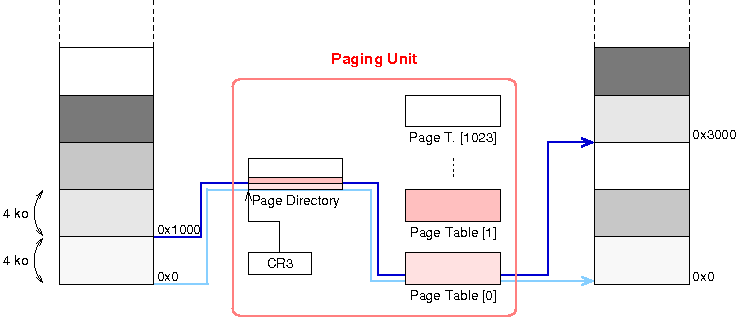
XII-A-2. Le fonctionnement▲
La traduction d'une adresse linûˋaire en une adresse physique se fait en plusieurs ûˋtapesô :
- Le processeur utilise le registre CR3 pour connaûÛtre l'adresse physique du rûˋpertoire de pagesô ;
- Les 10 premiers bits de l'adresse linûˋaire forment un offset, entre 0 et 1023, qui pointe sur une entrûˋe de ce rûˋpertoire de pagesô ;
- Cette entrûˋe du rûˋpertoire contient l'adresse physique d'une table de pagesô ;
- Les 10 bits suivants de l'adresse linûˋaire forment un offset qui pointe sur une entrûˋe de cette table de pagesô ;
- L'entrûˋe sûˋlectionnûˋe dans la table de pages pointe sur une page de 4 koô ;
- Les 12 derniers bits de l'adresse linûˋaire forment un offset, d'une valeur comprise entre 0 et 4095. Ce dûˋplacement permet de pointer sur une adresse prûˋcise en mûˋmoire.
|
|
XII-A-3. Les entrûˋes des rûˋpertoires et des tables de pages▲
Les entrûˋes de ces deux tableaux se ressemblent beaucoup. Seuls les champs en grisûˋ seront utilisûˋs dans nos premiû´res implûˋmentationsô :
|
|
|
|


- le bit P indique si la page ou la table pointûˋe est en mûˋmoire physiqueô ;
- le bit R/W indique si la page ou la table est accessible en ûˋcriture (bit û 1)ô ;
- le bit U/S est û 1 pour permettre l'accû´s aux tûÂches non privilûˋgiûˋesô ;
- le bit PWT et le bit PCD sont liûˋs û la gestion du cache des pages, que nous ne verrons pas pour le momentô ;
- le bit A indique si la page ou la table a ûˋtûˋ accûˋdûˋeô ;
- le bit D (table de pages seulement) indique si la page a ûˋtûˋ ûˋcriteô ;
- le bit PS (rûˋpertoire de pages seulement) indique la taille des pages (bit û 0 pour 4ô ko et û 1 pour 4ô Mo)ô ;
- le bit G est liûˋ û la gestion du cache des pagesô ;
- le champ Avail. est librement utilisable.
On peut noter que les adresses physiques du rûˋpertoire de pages ou de la table des pages sontãÎ sur 20 bitsô ! En fait, ces adresses doivent ûˆtre alignûˋes sur 4ô ko, ce qui signifie que les 12 bits de poids faible doivent ûˆtre û 0. Le processeur forme cette adresse û partir des 20 bits de poids fort et la complû´te avec 12 bits û 0. Nous avions dûˋjû vu ce type de mûˋcanisme avec les sûˋlecteurs de segment de la GDT.
XII-A-3-a. Un peu d'arithmûˋtique▲
- Un rûˋpertoire ou une table de pages occupent en mûˋmoire 1024*4 = 4096 octets = 4ô k.
- Une table de pages peut adresser en tout 1024 * 4ô k = 4 Mo.
- Un rûˋpertoire de pages peut adresser en tout 1024 * (1024 * 4ô k) = 4 Go.
En 64 bits, un niveau supplûˋmentaire est ajoutûˋ, nommûˋ PLM4
XII-A-4. Notes sur le cache▲
Le TLB (Translation Lookaside Buffer) est un cache des rûˋpertoires et des tables des pages utilisûˋs afin d'accûˋlûˋrer la traduction d'adresse. Quand un rûˋpertoire ou une table des pages sont modifiûˋs, les pages concernûˋes doivent ûˆtre immûˋdiatement invalidûˋes dans le TLB. Dans un premier temps, nous n'aurons pas besoin de nous prûˋoccuper de ces dûˋtails.
XII-A-5. Activer la pagination▲
Pour activer la pagination, il suffit de passer le bit 31 du registre CR0 û 1ô :
asm(" ô mov %%cr0, %?x; \
ô ô ô ô or %1, %?x; ô ô \
ô ô ô ô mov %?x, %%cr0" \
ô ô ô ô :: "i"(0x80000000));Bien entendu, pour que cela fonctionne, il faut au prûˋalable avoir initialisûˋ un rûˋpertoire et au moins une table des pagesô !
XII-B. Une premiû´re implûˋmentation trû´s simple▲
Pour une premiû´re implûˋmentation, nous n'allons pas crûˋer de tûÂche utilisateur. La pagination s'appliquera donc uniquement au noyau.
XII-B-1. Une organisation simple de la mûˋmoire avec l'identity mapping▲
Dans cette premiû´re implûˋmentation, nous allons activer la pagination pour le noyau tel que les quatre premiers Mo de mûˋmoire virtuelle coû₤ncident avec les 4 premiers Mo de mûˋmoire physiqueô :
|
|
Ce modû´le est simpleô : la premiû´re page en mûˋmoire virtuelle correspond û la premiû´re page en mûˋmoire physique, la deuxiû´me page en mûˋmoire virtuelle correspond û la deuxiû´me en mûˋmoire physique et ainsi de suiteãÎ
Nous avons vu dans les chapitres prûˋcûˋdents que notre noyau est tout petit et qu'il loge dans moins de 64 ko, nous allons adopter l'organisation suivanteô :
- le code et les donnûˋes du noyau occupent l'espace entre l'adresse 0x0 et 0x10000ô ;
- la pile du noyau utilise l'espace entre l'adresse 0x10000 et 0x20000ô ;
- le rûˋpertoire de pages sera chargûˋ û l'adresse 0x20000ô ;
- pour adresser 4 Mo, une seule table de pages suffit. Elle sera en 0x21000.
|
|
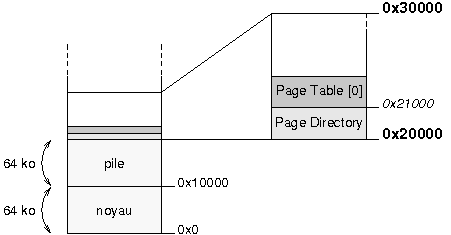
XII-B-2. Initialiser le rûˋpertoire et les tables de pages▲
Les entrûˋes du rûˋpertoire et de la table seront initialisûˋes avec les valeurs suivantesô :
- le bit 0 et le bit 1 mis û 1 indiquent que les pages/tables pointûˋes sont prûˋsentes en mûˋmoire et qu'elles sont en lecture et en ûˋcritureô ;
- le bit 2 est û 0 pour indiquer que leur accû´s est rûˋservûˋ au noyauô ;
- le bit 7 du rûˋpertoire est û 0 pour indiquer que les pages font 4ô ko.
|
|

La fonction init_mm() initialise le rûˋpertoire et les tables de pages du noyau et active la paginationô :
#include "types.h"
#defineô PAGING_FLAGô ô ô 0x80000000ô ô ô /* CR0 - bit 31 */
#define PD0_ADDR 0x20000ô ô ô ô /* addr. page directory kernel */
#define PT0_ADDR 0x21000ô ô ô ô /* addr. page table[0] kernel */
/* crûˋûˋ un mapping tel que vaddr = paddr sur 4Mo */
void init_mm(void)
{
ô ô ô ô u32 *pd0;ô ô ô ô /* kernel page directory */
ô ô ô ô u32 *pt0;ô ô ô ô /* kernel page table */
ô ô ô ô u32 page_addr;
ô ô ô ô int i;
ô ô ô ô /* Crûˋation du Page Directory */
ô ô ô ô pd0 = (u32 *) PD0_ADDR;
ô ô ô ô pd0[0] = PT0_ADDR;
ô ô ô ô pd0[0] |= 3;
ô ô ô ô for (i = 1; i < 1024; i++)
ô ô ô ô ô ô ô ô pd0[i] = 0;
ô ô ô ô /* Crûˋation de la Page Table[0] */
ô ô ô ô pt0 = (u32 *) PT0_ADDR;
ô ô ô ô page_addr = 0;
ô ô ô ô for (i = 0; i < 1024; i++) {
ô ô ô ô ô ô ô ô pt0[i] = page_addr;
ô ô ô ô ô ô ô ô pt0[i] |= 3;
ô ô ô ô ô ô ô ô page_addr += 4096;
ô ô ô ô }
ô ô ô ô asm("ô ô mov %0, %?x ô ô \n \
ô ô ô ô ô ô ô ô mov %?x, %%cr3 \n \
ô ô ô ô ô ô ô ô mov %%cr0, %?x \n \
ô ô ô ô ô ô ô ô or %1, %?x ô ô \n \
ô ô ô ô ô ô ô ô mov %?x, %%cr0" :: "i"(PD0_ADDR), "i"(PAGING_FLAG));
}XII-B-2-a. Que fait exactement cette fonctionô ?▲
pd0 = (u32 *) PD0_ADDR;Cette instruction fait pointer la variable pd0 sur le rûˋpertoire de pages û l'adresse physique 0x20000. Notez que pd0 peut aussi ûˆtre vu comme un tableau de 1024 entrûˋes.
pd0[0] = PT0_ADDR;
pd0[0] |= 3;Ensuite, on initialise la premiû´re entrûˋe du rûˋpertoire en pd0[0] pour la faire pointer sur la premiû´re table de pages. Cette table est situûˋe juste aprû´s le rûˋpertoire, û l'adresse physique 0x21000.
Pourquoi avoir choisi la premiû´re page de table et pas une des 1023 autresô ? Tout simplement parce que l'un des points clefs de notre schûˋma d'adressage est que l'adresse 0 virtuelle doit correspondre û l'adresse 0 en mûˋmoire physique et ainsi que pour toutes les adresses dans la plage adressûˋe. Le choix d'une autre table aurait ûˋtûˋ possible, mais cela aurait gûˋnûˋrûˋ un dûˋcalage entre les adresses en mûˋmoire virtuelle et celles en mûˋmoire physique.
Les deux premiers bits sont mis û 1 pour indiquer que les pages/tables pointûˋes sont prûˋsentes en mûˋmoire et qu'elles sont accessibles en lecture et en ûˋcriture.
for (i = 1; i < 1024; i++)
ô ô ô ô pd0[i] = 0;Les autres entrûˋes du rûˋpertoire de pages sont mises û zûˋro. On n'utilise donc qu'une seule table de pages, ce qui suffit pour adresser 4 Mo.
/* Crûˋation de la Page Table[0] */
pt0 = (u32 *) PT0_ADDR;
page_addr = 0;
for (i = 0; i < 1024; i++) {
ô ô ô ô pt0[i] = page_addr;
ô ô ô ô pt0[i] |= 3;
ô ô ô ô page_addr += 4096;
}La table de pages est initialisûˋe de faûÏon û ce que chacune de ses entrûˋes pointe sur une page mûˋmoire successive. La premiû´re page adresse la mûˋmoire û partir de l'adresse 0 et les autres pages se succû´dent.
XII-B-3. Une nouvelle exception pour gûˋrer les Page Fault▲
init_idt_desc(0x08, (u32) _asm_exc_PF, INTGATE, &kidt[14]); /* #PF */Lorsque le processeur tente d'accûˋder û une page qui n'est pas prûˋsente en mûˋmoire physique, il dûˋclenche une exception de type Page Fault. L'adresse qui a provoquûˋ le dûˋfaut de page est stockûˋe dans le registre CR2. û partir de cette adresse et selon le contexte d'exûˋcution qui a provoquûˋ l'exception, la routine de traitement devrait au choixô :
- terminer le programme en renvoyant une erreur de type segmentation faultô ;
- charger en mûˋmoire la page qui ûˋtait temporairement stockûˋe sur le disque dur dans la zone de swapô ;
- allouer une page.
Dans notre cas, le noyau va simplement afficher un message d'erreur et stopper.
XII-C. Exûˋcuter le noyau▲
L'affichage du message et des petits points montre que malgrûˋ le passage en mode paginûˋ, le noyau fonctionne normalement. L'annexe sur le mode debug de BochsAnnexe C - Bochs en mode debug indique quelques commandes utiles pour vûˋrifier la bonne prise en compte du rûˋpertoire et des tables de pages.
|
|
XIII. Gûˋrer la mûˋmoire - utiliser la pagination pour une tûÂche utilisateur▲
- Prûˋalableô : gûˋrer la mûˋmoire physiquePrûˋalableô : gûˋrer la mûˋmoire physique
- Comment organiser l'espace d'adressage d'une tûÂche utilisateurComment organiser l'espace d'adressage d'une tûÂche utilisateur
- Comment organiser l'espace noyau, pour gûˋrer les appels systû´meComment organiser l'espace noyau, pour gûˋrer les appels systû´me
- Crûˋer une tûÂcheCrûˋer une tûÂche
- Exûˋcuter la tûÂche utilisateurExûˋcuter la tûÂche utilisateur
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_PagingUserEnable.tgz
XIII-A. Prûˋalableô : gûˋrer la mûˋmoire physique▲
Pour crûˋer une tûÂche utilisateur, nous avons la vague idûˋe que le noyau doive mettre û jour le rûˋpertoire et les tables de pages, qu'il doive crûˋer une pile, et qu'il doive aussi rûˋserver de la mûˋmoire pour y copier le code et les donnûˋes.
Cela suffit-ilô ? Nonô ! Car avant toute chose, le noyau doit savoir quelles pages en mûˋmoire physique sont libres et lesquelles sont utilisûˋes. Il faut donc un systû´me de gestion des pages de la mûˋmoire physique.
Le systû´me de gestion des pages mis en éuvre ici repose sur l'utilisation d'un bitmap. Un bitmap est un tableau dont chaque ûˋlûˋment est un bit. Dans notre cas, chaque bit correspond û une page en mûˋmoire physiqueô : le premier bit correspond û la premiû´re page, le deuxiû´me bit correspond û la deuxiû´me page, etc. Chaque bit renseigne sur le statut libre ou occupûˋ de la page associûˋeô :
u8 mem_bitmap[RAM_MAXPAGE / 8]; /* bitmap allocation de pages */Nous utilisons ici un bitmap pour gûˋrer l'utilisation des pages physiques (page frame), mais d'autres solutions sont possibles comme l'utilisation d'une pile d'adresses libres ou bien d'une liste chaûÛnûˋe de structures dûˋcrivant les pages allouables.
XIII-A-1. Initialisation du bitmap▲
La premiû´re ûˋtape du gestionnaire est d'initialiser le bitmap de faûÏon û marquer les pages dûˋjû occupûˋes/rûˋservûˋes. L'espace physique sera organisûˋ de la faûÏon suivanteô :
|
|
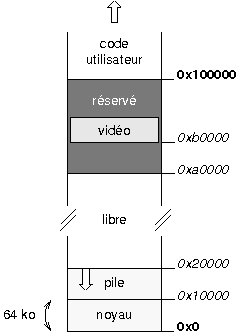
On remarque que la tûÂche utilisateur sera chargûˋe physiquement û l'adresse 0x100000. C'est un choix arbitraire et trû´s simplifiûˋ qui nous servira û mettre au point la pagination dans le contexte d'une tûÂche utilisateur. Nous verrons dans les chapitres suivants comment mettre au point un vrai gestionnaire de mûˋmoire.
Les pages utilisûˋes par le noyau ainsi que celles utilisûˋes par le hardware doivent ûˆtre marquûˋes comme ûˋtant prisesô :
/* Initialisation du bitmap de pages physiques */
for (pg = 0; pg < RAM_MAXPAGE / 8; pg++)
ô ô ô ô mem_bitmap[pg] = 0;
/* Pages rûˋservûˋes pour le noyau */
for (pg = PAGE(0x0); pg < PAGE(0x20000); pg++)
ô ô ô ô set_page_frame_used(pg);
/* Pages rûˋservûˋes pour le hardware */
for (pg = PAGE(0xA0000); pg < PAGE(0x100000); pg++)
ô ô ô ô set_page_frame_used(pg);Ce bout de code fait appel û deux macrosô :
- PAGE(addr) calcule, pour une adresse donnûˋe, le numûˋro de page physique û laquelle elle appartientô ;
- set_page_frame_used(page) met û jour le bitmap pour indiquer qu'une page est utilisûˋe.
Mais il existe ûˋgalement d'autres macros et fonctions indispensables û la gestion des pages physiquesô :
- rûˋserver une page libreô : get_page_frame()ô ;
- dûˋsallouer une page occupûˋe pour la rendre libreô : release_page_frame()ô ;
Toutes ces fonctions sont dans le fichier mm.c et dans le fichier mm.h
mm.cô :
#include "types.h"
#define __MM__
#include "mm.h"
/*
ô * Parcourt le bitmap û la recherche d'une page libre et la marque
ô * comme utilisûˋe avant de retourner son adresse physique.
ô */
char* get_page_frame(void)
{
ô ô ô ô int byte, bit;
ô ô ô ô int page = -1;
ô ô ô ô for (byte = 0; byte < RAM_MAXPAGE / 8; byte++)
ô ô ô ô ô ô ô ô if (mem_bitmap[byte] != 0xFF)
ô ô ô ô ô ô ô ô ô ô ô ô for (bit = 0; bit < 8; bit++)
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô if (!(mem_bitmap[byte] & (1 << bit))) {
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô page = 8 * byte + bit;
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô set_page_frame_used(page);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô return (char *) (page * PAGESIZE);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô }
ô ô ô ô return (char *) -1;
}
/* Crûˋûˋ un mapping tel que vaddr = paddr sur 4Mo */
void init_mm(void)
{
ô ô ô ô u32 page_addr;
ô ô ô ô int i, pg;
ô ô ô ô /* Initialisation du bitmap de pages physiques */
ô ô ô ô for (pg = 0; pg < RAM_MAXPAGE / 8; pg++)
ô ô ô ô ô ô ô ô mem_bitmap[pg] = 0;
ô ô ô ô /* Pages rûˋservûˋes pour le noyau */
ô ô ô ô for (pg = PAGE(0x0); pg < PAGE(0x20000); pg++)
ô ô ô ô ô ô ô ô set_page_frame_used(pg);
ô ô ô ô /* Pages rûˋservûˋes pour le hardware */
ô ô ô ô for (pg = PAGE(0xA0000); pg < PAGE(0x100000); pg++)
ô ô ô ô ô ô ô ô set_page_frame_used(pg);
ô ô ô ô /* Prend une page pour le Page Directory et une pour la Page Table[0] */
ô ô ô ô pd0 = (u32*) get_page_frame();
ô ô ô ô pt0 = (u32*) get_page_frame();
ô ô ô ô /* Initialisation du Page Directory */
ô ô ô ô pd0[0] = (u32) pt0;
ô ô ô ô pd0[0] |= 3;
ô ô ô ô for (i = 1; i < 1024; i++)
ô ô ô ô ô ô ô ô pd0[i] = 0;
ô ô ô ô /* Initialisation de la Page Table[0] */
ô ô ô ô page_addr = 0;
ô ô ô ô for (pg = 0; pg < 1024; pg++) {
ô ô ô ô ô ô ô ô pt0[pg] = page_addr;
ô ô ô ô ô ô ô ô pt0[pg] |= 3;
ô ô ô ô ô ô ô ô page_addr += 4096;
ô ô ô ô }
ô ô ô ô asm("ô ô mov %0, %?x \n \
ô ô ô ô ô ô ô ô mov %?x, %%cr3 \n \
ô ô ô ô ô ô ô ô mov %%cr0, %?x \n \
ô ô ô ô ô ô ô ô or %1, %?x \n \
ô ô ô ô ô ô ô ô mov %?x, %%cr0"::"m"(pd0), "i"(PAGING_FLAG));
}
/* Crûˋe un rûˋpertoire de pages pour une tûÂche */
u32 *pd_create_task1(void)
{
ô ô ô ô u32 *pd, *pt;
ô ô ô ô u32 i;
ô ô ô ô /* Prend et initialise une page pour le Page Directory */
ô ô ô ô pd = (u32*) get_page_frame();
ô ô ô ô for (i = 0; i < 1024; i++)
ô ô ô ô ô ô ô ô pd[i] = 0;
ô ô ô ô /* Prend et initialise une page pour la Page Table[0] */
ô ô ô ô pt = (u32*) get_page_frame();
ô ô ô ô for (i = 0; i < 1024; i++)
ô ô ô ô ô ô ô ô pt[i] = 0;
ô ô ô ô /* Espace kernel */
ô ô ô ô pd[0] = pd0[0];
ô ô ô ô pd[0] |= 3;
ô ô ô ô /* Espace u */
ô ô ô ô pd[USER_OFFSET >> 22] = (u32) pt;
ô ô ô ô pd[USER_OFFSET >> 22] |= 7;
ô ô ô ô pt[0] = 0x100000;
ô ô ô ô pt[0] |= 7;
ô ô ô ô return pd;
}mm.hô :
#include "types.h"
#defineô PAGESIZE ô ô ô ô 4096
#defineô RAM_MAXPAGEô ô ô 0x10000
#defineô VADDR_PD_OFFSET(addr)ô ô ((addr) & 0xFFC00000) >> 22
#defineô VADDR_PT_OFFSET(addr)ô ô ((addr) & 0x003FF000) >> 12
#defineô VADDR_PG_OFFSET(addr)ô ô (addr) & 0x00000FFF
#define PAGE(addr)ô ô ô ô ô ô ô (addr) >> 12
#define PAGING_FLAG 0x80000000ô /* CR0 - bit 31 */
#define USER_OFFSET 0x40000000
#define USER_STACK ô 0xE0000000
#ifdef __MM__
u32 *pd0;ô ô ô ô ô ô ô ô ô ô ô ô /* kernel page directory */
u32 *pt0;ô ô ô ô ô ô ô ô ô ô ô ô /* kernel page table */
u8 mem_bitmap[RAM_MAXPAGE / 8];ô /* bitmap allocation de pages (1 Go) */
#endif
struct pd_entry {
ô ô ô ô u32 present:1;
ô ô ô ô u32 writable:1;
ô ô ô ô u32 user:1;
ô ô ô ô u32 pwt:1;
ô ô ô ô u32 pcd:1;
ô ô ô ô u32 accessed:1;
ô ô ô ô u32 _unused:1;
ô ô ô ô u32 page_size:1;
ô ô ô ô u32 global:1;
ô ô ô ô u32 avail:3;
ô ô ô ô u32 page_table_base:20;
} __attribute__ ((packed));
struct pt_entry {
ô ô ô ô u32 present:1;
ô ô ô ô u32 writable:1;
ô ô ô ô u32 user:1;
ô ô ô ô u32 pwt:1;
ô ô ô ô u32 pcd:1;
ô ô ô ô u32 accessed:1;
ô ô ô ô u32 dirty:1;
ô ô ô ô u32 pat:1;
ô ô ô ô u32 global:1;
ô ô ô ô u32 avail:3;
ô ô ô ô u32 page_base:20;
} __attribute__ ((packed));
/* Marque une page comme utilisûˋe/libre dans le bitmap */
#define set_page_frame_used(page)ô ô ô ô mem_bitmap[((u32) page)/8] |= (1 << (((u32) page)%8))
#define release_page_frame(p_addr)ô ô ô mem_bitmap[((u32) p_addr/PAGESIZE)/8] &= ~(1 << (((u32) p_addr/PAGESIZE)%8))
/* Sûˋlectionne une page libre dans le bitmap */
char *get_page_frame(void);
/* Initialise les structures de donnûˋes de gestion de la mûˋmoire */
void init_mm(void);
/* Crûˋe un rûˋpertoire de pages pour une tûÂche */
u32 *pd_create_task1(void);XIII-B. Comment organiser l'espace d'adressage d'une tûÂche utilisateur▲
Lors de la compilation d'une tûÂche utilisateur, il n'est pas possible de savoir û l'avance oû¿ elle rûˋsidera en mûˋmoire physique. Or, û partir du moment oû¿ la tûÂche va manipuler des adresses, cette information est essentielle. Comment faireô ? Une solution qui se base sur la pagination va ûˆtre exposûˋe en dûˋtail ici. Son principe est trû´s simpleãÎ
Tout d'abord, la tûÂche est liûˋe de faûÏon û toujours s'exûˋcuter û la mûˆme adresse. Le choix de cette adresse est arbitraire et dans notre cas, les tûÂches doivent ûˆtre liûˋes en tenant compte qu'elles seront chargûˋes û l'adresse 0x40000000. L'adresse 0x40000000 est une adresse virtuelle, mais ûÏa, le compilateur n'en sait rienô ! La tûÂche pourra ûˆtre chargûˋe û n'importe quel endroit de la mûˋmoire physique. C'est le noyau qui, grûÂce au rûˋpertoire et aux tables de pages propres û cette tûÂche, se chargera de faire la correspondance entre l'espace d'adressage virtuel et la mûˋmoire physique. Par exemple, si la tûÂche est chargûˋe physiquement en 0x100000, le noyau (via le MMU) se chargera de faire la correspondance avec l'espace virtuel dûˋbutant en 0x40000000. La tûÂche aura donc toujours l'impression de s'exûˋcuter rûˋellement û cette adresseô :
|
|
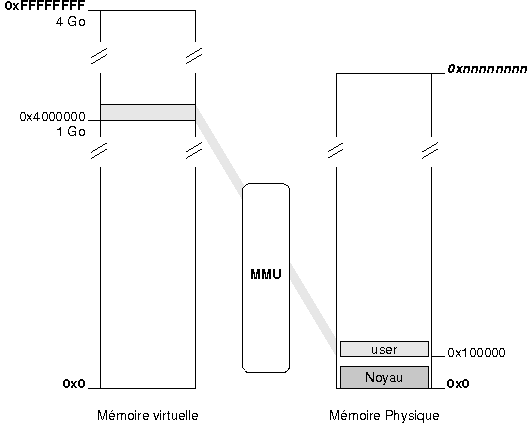
XIII-C. Comment organiser l'espace noyau, pour gûˋrer les appels systû´me▲
L'utilisation de la pagination n'introduit pas de changements sur la faûÏon dont sont implûˋmentûˋs les appels systû´meLes appels systû´meô : un noyau monotûÂche qui implûˋmente des appels systû´me. Ceux-ci sont toujours implûˋmentûˋs en utilisant une interruptionô :
init_idt_desc(0x08, (u32) _asm_syscalls, TRAPGATE, &kidt[48]); /* appels systeme - int 0x30 */La seule diffûˋrence par rapport au modû´le segmentûˋ concerne la faûÏon d'adresser les donnûˋes du noyau et de l'utilisateur. Mais nous verrons ci-dessous que cela va dans le sens d'une simplificationô !
Supposons par exemple que l'appel systû´me doive ûˋcrire û l'ûˋcran une chaûÛne de caractû´res situûˋe en 0x40000100. Au moment de l'appel systû´me, la tûÂche fournit en paramû´tre l'adresse de la chaûÛne en la plaûÏant dans le registre ebx. Au moment de l'appel systû´me, le noyau doit pouvoirô :
- accûˋder aux donnûˋes de cette tûÂche (dans notre exemple, code et donnûˋes dûˋbutent en 0x40000000)ô ;
- accûˋder aux donnûˋes et aux fonctions du noyau, par exemple la fonction printk et la mûˋmoire vidûˋo en 0xB8000.
Pour pouvoir accûˋder aux donnûˋes utilisateur, c'est trû´s simpleô : il suffit que le noyau utilise le rûˋpertoire de pages de la tûÂche en question. Mais comment faire pour accûˋder au code et aux donnûˋes du noyauô ? La solution est trû´s simpleô : pour pouvoir accûˋder aux donnûˋes du noyau, il faut que ce rûˋpertoire de pages ait aussi les entrûˋes adûˋquates pour accûˋder û l'espace virtuel du noyau. Autrement dit, le rûˋpertoire de pages de la tûÂche utilisateur comprend une partie qui lui permet d'accûˋder û son propre espace d'adressage, et une autre partie qui lui permet d'accûˋder û l'espace d'adressage du noyauô !ô :
|
|
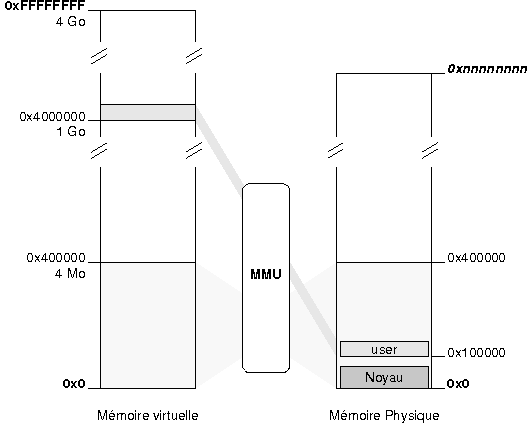
Le traitement de l'appel systû´me servant û afficher une chaûÛne est maintenant trû´s simple, car l'adresse passûˋe en paramû´tre est directement accessibleô :
#include "types.h"
#include "lib.h"
void do_syscalls(int sys_num)
{
ô ô ô ô char *u_str;
ô ô ô ô if (sys_num == 1) {
ô ô ô ô ô ô ô ô asm("mov %?x, %0": "=m"(u_str) :);
ô ô ô ô ô ô ô ô printk(u_str);
ô ô ô ô } else {
ô ô ô ô ô ô ô ô printk("unknown syscall %d\n", sys_num);
ô ô ô ô }
ô ô ô ô return;
}XIII-C-1. Note concernant la sûˋcuritûˋ▲
Bien que prûˋsent dans son espace d'adressage virtuel, la tûÂche ne doit pas pouvoir accûˋder û l'espace du noyau û tout momentô : cela constituerait un gros problû´me de sûˋcuritûˋ. Pour empûˆcher la tûÂche en mode utilisateur d'accûˋder û l'espace noyau hors d'un appel systû´me, il suffit de positionner le bit US des entrûˋes du rûˋpertoire et des tables de pages û ô :
- 0 (espace privilûˋgiûˋ) pour les pages du noyauô ;
- 1 (espace non privilûˋgiûˋ) pour les pages de l'espace utilisateur.
Nous voulons que la tûÂche accû´de au noyau uniquement via des services prûˋcis, en l'occurrence des appels systû´me. Le processeur, jusque lû en mode utilisateur (ring 3), passe alors en mode noyau (ring 0). Pour distinguer ces deux ûˋtats, on dit que la tûÂche s'exûˋcute en mode utilisateur ou en mode noyau.
XIII-D. Crûˋer une tûÂche▲
XIII-D-1. Une tûÂche trû´s simple▲
Pour servir d'exemple, la tûÂche û exûˋcuter est une fonction trû´s simple, presque identique û celle utilisûˋe au chapitre traitant des appels systû´meLes appels systû´meô : un noyau monotûÂche qui implûˋmente des appels systû´me. La seule diffûˋrence concerne l'adressageô :
- selon notre organisation de la mûˋmoire, la tûÂche va s'exûˋcuter û l'adresse virtuelle 0x40000000ô ;
- dans notre exemple, la tûÂche sera chargûˋe physiquement û l'adresse 0x100000ô ;
- cela signifie que le bloc de mûˋmoire virtuelle commenûÏant en 0x40000000 sera mappûˋ sur le bloc de mûˋmoire physique en 0x100000 grûÂce au rûˋpertoire et aux tables de pages.
Le code ci-dessus recopie les caractû´res û cet emplacement puis fait un appel systû´me pour afficher la chaûÛneô :
void task1(void)
{
ô ô ô ô char *msg = (char*) 0x40000100; /* le message sera stockûˋ en 0x100100 */
ô ô ô ô msg[0] = 't';
ô ô ô ô msg[1] = 'a';
ô ô ô ô msg[2] = 's';
ô ô ô ô msg[3] = 'k';
ô ô ô ô msg[4] = '1';
ô ô ô ô msg[5] = '\n';
ô ô ô ô msg[6] = 0;
ô ô ô ô asm("mov %0, %?x; mov $0x01, %?x; int $0x30" :: "m" (msg));
ô ô ô ô while(1);
ô ô ô ô return; /* never go there */
}XIII-D-2. Charger la tûÂche▲
Dans le modû´le d'organisation de la mûˋmoire, nous avons dûˋcidûˋ que la tûÂche serait en 0x100000 en mûˋmoire physique. Cette fonction occupe au maximum 100 octets, la fonction ci-dessous effectue la copie du code û la bonne adresseô :
memcpy((u32*) 0x100000, &task1, 100); /* copie de 100 instructions */XIII-D-3. Crûˋer et initialiser le rûˋpertoire et les tables de pages de la tûÂche utilisateur▲
L'utilisation de la pagination repose sur le mode protûˋgûˋ qui implique l'utilisation de la segmentation. Il faut donc crûˋer des descripteurs de segments pour le code, les donnûˋes et la pile utilisateur. Pour simplifier le modû´le, ces segments parcourent toute la mûˋmoireô :
init_gdt_desc(0x0, 0xFFFFF, 0xFF, 0x0D, &kgdt[4]); /* ucode */
init_gdt_desc(0x0, 0xFFFFF, 0xF3, 0x0D, &kgdt[5]); /* udata */
init_gdt_desc(0x0, 0x0, ô ô 0xF7, 0x0D, &kgdt[6]); /* ustack */Il faut ûˋgalement crûˋer et initialiser le rûˋpertoire et les tables de pages propres û la tûÂche utilisateur. C'est le rûÇle de la fonction pd_create_task1(). Elle utilise les fonctions d'allocation et de dûˋsallocation de pages de la mûˋmoire physique pour y stocker les rûˋpertoires et les tables de pagesô :
u32 *pd_create_task1(void)
{
ô ô ô ô u32 *pd, *pt;
ô ô ô ô u32 i;
ô ô ô ô /* Prend et initialise une page pour le Page Directory */
ô ô ô ô pd = (u32*) get_page_frame();
ô ô ô ô for (i = 0; i < 1024; i++)
ô ô ô ô ô ô ô ô pd[i] = 0;
ô ô ô ô /* Prend et initialise une page pour la Page Table[0] */
ô ô ô ô pt = (u32*) get_page_frame();
ô ô ô ô for (i = 0; i < 1024; i++)
ô ô ô ô ô ô ô ô pt[i] = 0;
ô ô ô ô /* Espace kernel */
ô ô ô ô pd[0] = pd0[0];
ô ô ô ô pd[0] |= 3;
ô ô ô ô /* Espace u */
ô ô ô ô pd[USER_OFFSET >> 22] = (u32) pt;
ô ô ô ô pd[USER_OFFSET >> 22] |= 7;
ô ô ô ô pt[0] = 0x100000;
ô ô ô ô pt[0] |= 7;
ô ô ô ô return pd;
}Cette implûˋmentation est une simplification qui vise û illustrer la pagination, mais il faut garder û l'esprit que le modû´le mûˋmoire utilisûˋ ici est trû´s rudimentaire. Nous verrons plus tard que dans un OS plus complet, qui offre une gestion plus fine de la mûˋmoire, la gestion des rûˋpertoires et des tables de pages obûˋit û des mûˋcanismes plus complexes.
XIII-E. Exûˋcuter la tûÂche utilisateur▲
Le code principal du noyau dans le fichier kernel.c.
#include "types.h"
#include "lib.h"
#include "gdt.h"
#include "screen.h"
#include "io.h"
#include "idt.h"
#include "mm.h"
void init_pic(void);
int main(void);
void _start(void)
{
ô ô ô ô kY = 16;
ô ô ô ô kattr = 0x0E;
ô ô ô ô /* Initialisation de la GDT et des segments */
ô ô ô ô init_gdt();
ô ô ô ô /* Initialisation du pointeur de pile %esp */
ô ô ô ô asm(" ô movw $0x18, %ax \n \
ô ô ô ô ô ô ô ô movw %ax, %ss \n \
ô ô ô ô ô ô ô ô movl $0x20000, %esp");
ô ô ô ô main();
}
void task1(void)
{
ô ô ô ô char *msg = (char *) 0x40000100;ô ô ô ô /* le message sera stockûˋ en 0x100100 */
ô ô ô ô msg[0] = 't';
ô ô ô ô msg[1] = 'a';
ô ô ô ô msg[2] = 's';
ô ô ô ô msg[3] = 'k';
ô ô ô ô msg[4] = '1';
ô ô ô ô msg[5] = '\n';
ô ô ô ô msg[6] = 0;
ô ô ô ô asm("mov %0, %?x; mov $0x01, %?x; int $0x30"::"m"(msg));
ô ô ô ô while (1);
ô ô ô ô return;ô ô ô ô ô ô ô ô ô /* never go there */
}
int main(void)
{
ô ô ô ô u32 *pd;
ô ô ô ô printk("kernel : gdt loaded\n");
ô ô ô ô init_idt();
ô ô ô ô printk("kernel : idt loaded\n");
ô ô ô ô init_pic();
ô ô ô ô printk("kernel : pic configured\n");
ô ô ô ô hide_cursor();
ô ô ô ô /* Initialisation du TSS */
ô ô ô ô asm("ô ô movw $0x38, %ax \n \
ô ô ô ô ô ô ô ô ltr %ax");
ô ô ô ô printk("kernel : tr loaded\n");
ô ô ô ô init_mm();
ô ô ô ô printk("kernel : paging enable\n");
ô ô ô ô pd = pd_create_task1();
ô ô ô ô memcpy((char *) 0x100000, (char *) &task1, 100);ô ô ô ô /* copie de 100 instructions */
ô ô ô ô printk("kernel : task created\n");
ô ô ô ô kattr = 0x47;
ô ô ô ô printk("kernel : trying switch to user task...\n");
ô ô ô ô kattr = 0x07;
ô ô ô ô asm (" ô cli \n \
ô ô ô ô ô ô ô ô movl $0x20000, %0 \n \
ô ô ô ô ô ô ô ô movl %1, %?x \n \
ô ô ô ô ô ô ô ô movl %?x, %%cr3 \n \
ô ô ô ô ô ô ô ô push $0x33 \n \
ô ô ô ô ô ô ô ô push $0x40000F00 \n \
ô ô ô ô ô ô ô ô pushfl \n \
ô ô ô ô ô ô ô ô popl %?x \n \
ô ô ô ô ô ô ô ô orl $0x200, %?x \n \
ô ô ô ô ô ô ô ô and $0xFFFFBFFF, %?x \n \
ô ô ô ô ô ô ô ô push %?x \n \
ô ô ô ô ô ô ô ô push $0x23 \n \
ô ô ô ô ô ô ô ô push $0x40000000 \n \
ô ô ô ô ô ô ô ô movw $0x2B, %%ax \n \
ô ô ô ô ô ô ô ô movw %%ax, %%ds \n \
ô ô ô ô ô ô ô ô iret" : "=m"(default_tss.esp0) : "m"(pd));
ô ô ô ô while (1);
}Pour vûˋrifier avec Bochs l'utilisation de la pagination pour la tûÂche utilisateur, il est possible de poser un point d'arrûˆt sur une adresse virtuelle. L'adresse ci-dessous correspond au point d'entrûˋe de la tûÂche utilisateur. Ensuite, la directive info tab indique comment la MMU traduit les adressesô :
<bochs:1> lb 0x40000000
<bochs:2> c
...
<bochs:3> info tab
cr3: 0x00022000
0x00000000-0x003fffff -> 0x00000000-0x003fffff
0x40000000-0x40000fff -> 0x00100000-0x00100fff|
|
XIV. Un systû´me multitûÂche simple▲
- Exûˋcuter plusieurs tûÂches simultanûˋment grûÂce û l'ordonnanceurExûˋcuter plusieurs tûÂches simultanûˋment grûÂce û l'ordonnanceur
- Un ordonnanceur appelûˋ û chaque interruption d'horloge|outlineUn ordonnanceur appelûˋ û chaque interruption d'horloge
- Charger une tûÂche en mûˋmoireCharger une tûÂche en mûˋmoire
- Le contexte d'une tûÂcheLe contexte d'une tûÂche
- Exûˋcuter plusieurs tûÂchesExûˋcuter la tûÂche utilisateur
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_MultiTask.tgz
XIV-A. Exûˋcuter plusieurs tûÂches simultanûˋment grûÂce û l'ordonnanceur▲
Nous avons dûˋtaillûˋ dans une partie prûˋcûˋdenteGûˋrer la mûˋmoire - utiliser la pagination pour une tûÂche utilisateur comment le noyau charge et exûˋcute une tûÂche utilisateur. Dans ce chapitre, nous allons voir comment implûˋmenter un ordonnanceur (scheduler) simple qui permet au noyau d'exûˋcuter plusieurs tûÂches en quasi simultanûˋitûˋ.
L'implûˋmentation actuelle est trû´s simpleô :
- le noyau charge plusieurs tûÂchesô ;
- les interruptions sont ensuite rûˋtabliesô ;
-
lors de chaque interruption d'horloge, le processeur appelle une fonction particuliû´re dont le rûÇle est de partager le temps CPU entre les diffûˋrentes tûÂches. Si une tûÂche est ûˋligible, le noyau vaô :
- Sauvegarder la tûÂche en cours,
- Choisir la nouvelle tûÂche,
- Effectuer la commutationô ;
- la nouvelle tûÂche s'exûˋcute jusqu'û la nouvelle interruption d'horloge (ãÎ).
XIV-B. Un ordonnanceur appelûˋ û chaque interruption d'horloge▲
Lors de chaque interruption d'horloge, le processeur fait appel û la fonction schedule()ô :
void isr_clock_int(void)
{
ô ô static int tic = 0;
ô ô static int sec = 0;
ô ô tic++;
ô ô if (tic%100 == 0) {
ô ô ô ô sec++;
ô ô ô ô tic = 0;
ô ô }
ô ô schedule();
}La fonction schedule() peut ûˆtre confrontûˋe û diffûˋrents casô :
- si aucune tûÂche n'est prûˆte, le scheduler ne fait rienô ;
- si aucune tûÂche ne tourne, mais qu'une tûÂche est prûˆte, nous sommes dans une situation dûˋjû vue prûˋcûˋdemmentô ! Le noyau passe la main û la tûÂche utilisateur û la diffûˋrence que celle-ci n'est pas chargûˋe par le programme principal, mais suite û une interruption d'horlogeô ;
-
si une tûÂche tourne et qu'au moins une autre tûÂche est prûˆteô : le scheduler effectue un changement de tûÂche. Cette partie est la plus dûˋlicate et nous place dans le vif du sujetãÎ Pour passer la main û une nouvelle tûÂche, le noyau doitô :
- sauvegarder la tûÂche en cours,
- charger la nouvelle tûÂche,
- effectuer la commutation.
Le code de l'ordonnanceur est prûˋsent dans le fichier schedule.c
#include "types.h"
#include "gdt.h"
#include "process.h"
void schedule(void)
{
ô ô ô ô u32* stack_ptr;
ô ô ô ô u32 esp0, eflags;
ô ô ô ô u16 ss, cs;
ô ô ô ô /* Stocke dans stack_ptr le pointeur vers les registres sauvegardes */
ô ô ô ô asm("mov (%?p), %?x; mov %?x, %0" : "=m" (stack_ptr) : );
ô ô ô ô /* s'il n'y a pas de processus charge et qu'au moins un est prûˆt, on le charge */
ô ô ô ô if (current == 0 && n_proc) {
ô ô ô ô ô ô ô ô current = &p_list[0];
ô ô ô ô }
ô ô ô ô /*
ô ô ô ô ô * S'il y a un seul processus (qu'on laisse tourner) ou aucun
ô ô ô ô ô * processus, on retourne directement.
ô ô ô ô ô */
ô ô ô ô else if (n_proc <= 1) {
ô ô ô ô ô ô ô ô return;
ô ô ô ô }
ô ô ô ô /* s'il y a au moins deux processus, on commute vers le suivant */
ô ô ô ô else if (n_proc>1) {
ô ô ô ô ô ô ô ô /* Sauver les registres du processus courant */
ô ô ô ô ô ô ô ô current->regs.eflags = stack_ptr[16];
ô ô ô ô ô ô ô ô current->regs.cs ô = stack_ptr[15];
ô ô ô ô ô ô ô ô current->regs.eip = stack_ptr[14];
ô ô ô ô ô ô ô ô current->regs.eax = stack_ptr[13];
ô ô ô ô ô ô ô ô current->regs.ecx = stack_ptr[12];
ô ô ô ô ô ô ô ô current->regs.edx = stack_ptr[11];
ô ô ô ô ô ô ô ô current->regs.ebx = stack_ptr[10];
ô ô ô ô ô ô ô ô current->regs.ebp = stack_ptr[8];
ô ô ô ô ô ô ô ô current->regs.esi = stack_ptr[7];
ô ô ô ô ô ô ô ô current->regs.edi = stack_ptr[6];
ô ô ô ô ô ô ô ô current->regs.ds = stack_ptr[5];
ô ô ô ô ô ô ô ô current->regs.es = stack_ptr[4];
ô ô ô ô ô ô ô ô current->regs.fs = stack_ptr[3];
ô ô ô ô ô ô ô ô current->regs.gs = stack_ptr[2];
ô ô ô ô ô ô ô ô current->regs.esp = stack_ptr[17];
ô ô ô ô ô ô ô ô current->regs.ss = stack_ptr[18];
ô ô ô ô ô ô ô ô
ô ô ô ô ô ô ô ô /*
ô ô ô ô ô ô ô ô ô * La fonction l'interruption et la fonction schedule()
ô ô ô ô ô ô ô ô ô * empilent un grand nombre de registres sur la pile.
ô ô ô ô ô ô ô ô ô * L'instruction ci-dessous permet de repartir sur une pile
ô ô ô ô ô ô ô ô ô * noyau propre une fois la commutation effectuûˋe.
ô ô ô ô ô ô ô ô ô */
ô ô ô ô ô ô ô ô default_tss.esp0 = (u32) (stack_ptr + 19);
ô ô ô ô ô ô ô ô /* Choix du nouveau processus (un simple roundrobin) */
ô ô ô ô ô ô ô ô if (n_proc > current->pid+1)
ô ô ô ô ô ô ô ô ô ô ô ô current = &p_list[current->pid+1];
ô ô ô ô ô ô ô ô else
ô ô ô ô ô ô ô ô ô ô ô ô current = &p_list[0];
ô ô ô ô }
ô ô ô ô /*
ô ô ô ô ô * Empile les registres ss, esp, eflags, cs et eip nûˋcessaires û la
ô ô ô ô ô * commutation. Ensuite, la fonction do_switch() restaure les
ô ô ô ô ô * registres, la table de pages du nouveau processus courant et commute
ô ô ô ô ô * avec l'instruction iret.
ô ô ô ô ô */
ô ô ô ô ss = current->regs.ss;
ô ô ô ô cs = current->regs.cs;
ô ô ô ô eflags = (current->regs.eflags | 0x200) & 0xFFFFBFFF;
ô ô ô ô esp0 = default_tss.esp0;
ô ô ô ô
ô ô ô ô asm("ô ô mov %0, %%esp; \
ô ô ô ô ô ô ô ô push %1; \
ô ô ô ô ô ô ô ô push %2; \
ô ô ô ô ô ô ô ô push %3; \
ô ô ô ô ô ô ô ô push %4; \
ô ô ô ô ô ô ô ô push %5; \
ô ô ô ô ô ô ô ô push %6; \
ô ô ô ô ô ô ô ô ljmp $0x08, $do_switch" \
ô ô ô ô ô ô ô ô :: \
ô ô ô ô ô ô ô ô "m" (esp0), \
ô ô ô ô ô ô ô ô "m" (ss), \
ô ô ô ô ô ô ô ô "m" (current->regs.esp), \
ô ô ô ô ô ô ô ô "m" (eflags), \
ô ô ô ô ô ô ô ô "m" (cs), \
ô ô ô ô ô ô ô ô "m" (current->regs.eip), \
ô ô ô ô ô ô ô ô "m" (current)
ô ô ô ô );
}XIV-B-1. Sauvegarder la tûÂche en cours▲
Nous allons tout d'abord dûˋtailler comment la fonction schedule() sauvegarde les registres de la tûÂche en cours (celle qui a ûˋtûˋ interrompue) dans la structure qui lui est dûˋdiûˋe et pointûˋe par current.
Les registres û sauvegarder ont dûˋjû ûˋtûˋ empilûˋs sur la pile noyau par l'interruption d'horloge (ss, esp, eflags, cs et eip) et par l'appel explicite aux instructions pushad et push.
|
|
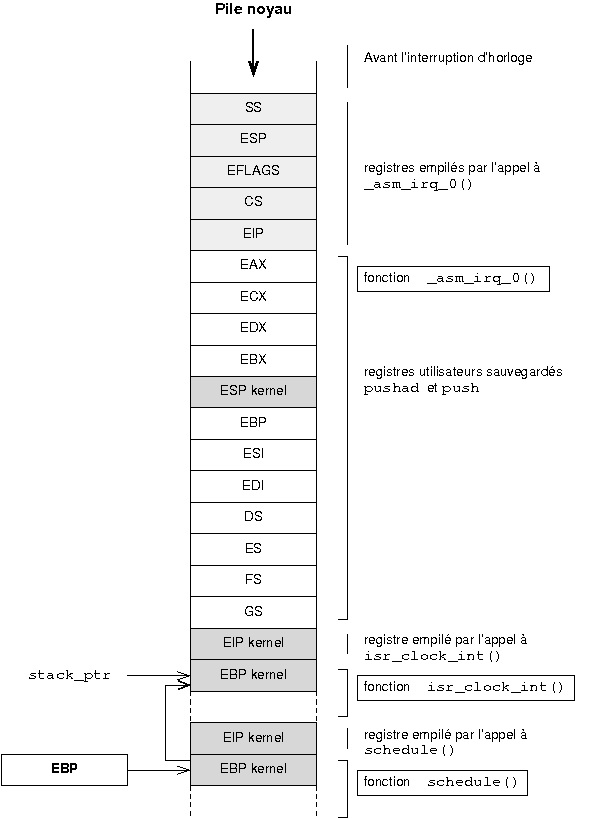
La sauvegarde des registres se fait dans la structure struct process associûˋe û la tûÂche encore en cours et pointûˋe par currentô :
struct process {
ô ô ô ô unsigned int pid;
ô ô ô ô struct {
ô ô ô ô ô ô ô ô u32 eax, ecx, edx, ebx;
ô ô ô ô ô ô ô ô u32 esp, ebp, esi, edi;
ô ô ô ô ô ô ô ô u32 eip, eflags;
ô ô ô ô ô ô ô ô u32 cs:16, ss:16, ds:16, es:16, fs:16, gs:16;
ô ô ô ô ô ô ô ô u32 cr3;
ô ô ô ô } regs __attribute__ ((packed));
} __attribute__ ((packed));Le procûˋdûˋ pour rûˋcupûˋrer ces valeurs sur la pile repose sur l'utilisation du registre ebp (voir pour plus de dûˋtails la partie sur les Stack FrameAnnexe D - Gûˋrer les arguments sur la pile avec les Stack Frame). La variable stack_ptr adresse la pile de faûÏon û pouvoir ensuite rûˋcupûˋrer facilement le contenu des registres sauvegardûˋs lors de l'interruptionô :
/* stocke dans stack_ptr le pointeur vers les registres sauvegardes */
asm("mov (%?p), %?x; mov %?x, %0" : "=m" (stack_ptr) : );
/* sauve l'ensemble des registres */
current->regs.ss ô = stack_ptr[18];
current->regs.esp = stack_ptr[17];
current->regs.eflags = stack_ptr[16];
/* etc... */XIV-B-2. Choisir la nouvelle tûÂche▲
L'ordonnanceur choisit une nouvelle tûÂche et fait pointer la variable current vers la structure de la nouvelle tûÂche û activerô :
/* Choix du nouveau processus (un simple round robin) */
if (n_proc > current->pid+1)
ô ô ô ô current = &p_list[current->pid+1];
else
ô ô ô ô current = &p_list[0];XIV-B-3. Commuter▲
Une fois que l'ancienne tûÂche est sauvegardûˋe et que la nouvelle tûÂche est choisie, le scheduler doit charger les registres du processeur avec les valeurs sauvegardûˋes prûˋcûˋdemment avant de commuter.
En premier lieu, le pointeur de pile noyau du TSS est initialisûˋ de faûÏon û ce queô :
- la pile noyau, sur laquelle des registres ont ûˋtûˋ sauvegardûˋs, soit nettoyûˋe une fois la commutation effectuûˋeô ;
- la pile noyau soit prûˋparûˋe pour la nouvelle tûÂche.
default_tss.esp0 = (u32) (stack_ptr + 19);L'utilisation d'une seule pile noyau pour l'ensemble des tûÂches a l'avantage de la simplicitûˋ, mais a ûˋgalement un inconvûˋnient importantô : il est impossible de prûˋempter une tûÂche alors qu'elle effectue un appel systû´me. La raison est exposûˋe en dûˋtail au chapitre suivant qui traite de la rûˋalisation d'un systû´me multitûÂche avec des appels systû´me interruptibles.
Ensuite, les valeurs sauvegardûˋes correspondant aux registres ss, esp, eflags, cs et eip sont empilûˋes afin de prûˋparer la commutation. La fonction do_switch() est appelûˋe pour effectuer la commutation proprement diteô :
asm(" ô mov %0, %%esp; \
ô ô ô ô push %1; \
ô ô ô ô push %2; \
ô ô ô ô push %3; \
ô ô ô ô push %4; \
ô ô ô ô push %5; \
ô ô ô ô push %6; \
ô ô ô ô ljmp $0x08, $do_switch" \
ô ô ô ô :: \
ô ô ô ô "m" (esp0), \
ô ô ô ô "m" (ss), \
ô ô ô ô "m" (current->regs.esp), \
ô ô ô ô "m" (eflags), \
ô ô ô ô "m" (cs), \
ô ô ô ô "m" (current->regs.eip), \
ô ô ô ô "m" (current)
);XIV-B-3-a. La fonction do_switch()▲
La fonction do_switch(), implûˋmentûˋe dans le fichier sched.asm, n'est pas trû´s compliquûˋeô :
global do_switch
do_switch:
ô ô ô ô ; recuper l'adresse de *current
ô ô ô ô mov esi, [esp]
ô ô ô ô pop eaxô ô ô ô ô ô ô ô ô ; depile @current
ô ô ô ô ; prûˋpare les registres
ô ô ô ô push dword [esi+4]ô ô ô ; eax
ô ô ô ô push dword [esi+8]ô ô ô ; ecx
ô ô ô ô push dword [esi+12]ô ô ô ; edx
ô ô ô ô push dword [esi+16]ô ô ô ; ebx
ô ô ô ô push dword [esi+24]ô ô ô ; ebp
ô ô ô ô push dword [esi+28]ô ô ô ; esi
ô ô ô ô push dword [esi+32]ô ô ô ; edi
ô ô ô ô push dword [esi+48]ô ô ô ; ds
ô ô ô ô push dword [esi+50]ô ô ô ; es
ô ô ô ô push dword [esi+52]ô ô ô ; fs
ô ô ô ô push dword [esi+54]ô ô ô ; gs
ô ô ô ô ; enlû´ve le mask du PIC
ô ô ô ô mov al, 0x20
ô ô ô ô out 0x20, al
ô ô ô ô ; charge table des pages
ô ô ô ô mov eax, [esi+56]
ô ô ô ô mov cr3, eax
ô ô ô ô ; charge les registres
ô ô ô ô pop gs
ô ô ô ô pop fs
ô ô ô ô pop es
ô ô ô ô pop ds
ô ô ô ô pop edi
ô ô ô ô pop esi
ô ô ô ô pop ebp
ô ô ô ô pop ebx
ô ô ô ô pop edx
ô ô ô ô pop ecx
ô ô ô ô pop eax
ô ô ô ô ; retourne
ô ô ô ô iret- L'adresse de la structure de la nouvelle tûÂche est rûˋcupûˋrûˋe dans le registre esiô ;
- Un signal est envoyûˋ au PIC pour rûˋtablir les interruptions hardwareô ;
- Le rûˋpertoire de pages de la nouvelle tûÂche est chargûˋ (noteô : û ce point-lû , nous sommes toujours dans l'espace d'adressage du noyau, partagûˋ par toutes les tûÂches)ô ;
- Les registres sont directement chargûˋs û partir de la structure de la nouvelle tûÂcheô ;
- L'instruction iret retourne de l'interruption et charge les registres ss, esp, eflags, cs et eip.
û ce moment, la commutation est achevûˋe et la nouvelle tûÂche utilisateur s'exûˋcuteô !
XIV-B-4. Note concernant les appels systû´me▲
Dans cette premiû´re implûˋmentation, les tûÂches ne peuvent ûˆtres prûˋemptûˋes alors qu'elles rûˋalisent un appel systû´me, car le partage de la pile noyau conduirait û des incohûˋrences. Il faut donc dûˋsactiver les interruptions lors des appels. Cela se fait par le choix d'un INTGATE û la place d'un TRAPGATEô :
init_idt_desc(0x08, (u32) _asm_syscalls, INTGATE|0x6000, &kidt[48]); /* appels systeme - int 0x30 */XIV-C. Charger une tûÂche en mûˋmoire▲
Le chargement d'une tûÂche, un peu sur le mûˆme modû´le que dans les chapitres prûˋcûˋdent, se fait grûÂce û la fonction load_task(). Dans l'exemple ci-dessous, le noyau charge la tûÂche task1() û l'adresse physique 0x100000ô :
load_task((u32*) 0x100000, (u32*) &task1, 0x2000);La fonction load_task() est dûˋfinie dans le fichier process.c
#include "lib.h"
#include "mm.h"
#define __PLIST__
#include "process.h"
void load_task(u32 * code_phys_addr, u32 * fn, unsigned int code_size)
{
ô ô ô ô u32 page_base, pages;
ô ô ô ô u32 *pd;
ô ô ô ô int i;
ô ô ô ô /* Copie du code û l'adresse spûˋcifiûˋe */
ô ô ô ô memcpy((char *) code_phys_addr, (char *) fn, code_size);
ô ô ô ô /* Mise a jour du bitmap */
ô ô ô ô page_base = (u32) PAGE(code_phys_addr);
ô ô ô ô if (code_size % PAGESIZE)
ô ô ô ô ô ô ô ô pages = code_size / PAGESIZE + 1;
ô ô ô ô else
ô ô ô ô ô ô ô ô pages = code_size / PAGESIZE;
ô ô ô ô for (i = 0; i < pages; i++)
ô ô ô ô ô ô ô ô set_page_frame_used(page_base + i);
ô ô ô ô /* Crûˋation du rûˋpertoire et des tables de pages */
ô ô ô ô pd = pd_create(code_phys_addr, code_size);
ô ô ô ô /* Initialisation des registres */
ô ô ô ô p_list[n_proc].pid = n_proc;
ô ô ô ô p_list[n_proc].regs.ss = 0x33;
ô ô ô ô p_list[n_proc].regs.esp = 0x40001000;
ô ô ô ô p_list[n_proc].regs.cs = 0x23;
ô ô ô ô p_list[n_proc].regs.eip = 0x40000000;
ô ô ô ô p_list[n_proc].regs.ds = 0x2B;
ô ô ô ô p_list[n_proc].regs.cr3 = (u32) pd;
ô ô ô ô n_proc++;
}- Elle commence par copier la fonction û l'adresse physique voulue et met û jour le bitmap de pagesô ;
- Elle crûˋe le rûˋpertoire et les tables de pages avec la fonction pd_create(). Les pages physiques occupûˋes par le code de la tûÂche sont mappûˋes sur les pages virtuelles en 0x40000000ô ;
- La pile noyau est pour le moment sur la mûˆme page que celle contenant le code et le pointeur de pile est en 0x40000FF0ô ;
- Elle demande une page pour la pile noyau. L'adresse linûˋaire de cette page correspond û son adresse physique (elle se situe dans l'espace d'adressage du noyau)ô ;
- Elle initialise la structure process de cette tûÂche.
Ce code n'est pas trû´s compliquûˋ, car l'objet de ce chapitre est seulement de montrer comment implûˋmenter de faûÏon simple un systû´me multitûÂche. J'ai donc dûˋlibûˋrûˋment supprimûˋ tout ce qui peut ô¨ô alourdirô ô£ le code. Il est cependant nûˋcessaire d'en pointer deux importantes limitationsô :
- le choix de pages libres pour le chargement de la tûÂche n'est pas gûˋrûˋ par l'allocateurô ;
- les pages choisies sont successives (il n'y a donc pas de gestion de la fragmentation).
XIV-D. Le contexte d'une tûÂche▲
Lorsqu'une tûÂche est interrompue pour laisser la main û une autre, son contexte d'exûˋcution doit ûˆtre intûˋgralement conservûˋ afin qu'elle puisse plus tard reprendre lû oû¿ elle avait ûˋtûˋ interrompue. La structure struct process dûˋfinit pour chaque tûÂcheô :
- un identifiant, le pidô ;
- l'ensemble des registres du processeur susceptibles d'ûˆtre utilisûˋs par la tûÂche.
Un tableau de struct process est dûˋfini pour conserver le contexte de toutes nos tûÂches. Le nombre maximum de tûÂches est pour le moment trû´s restreint, juste 32ô :
struct process p_list[32];La variable *current pointe sur la tûÂche en cours d'exûˋcution et n_proc nous renseigne sur le nombre total de tûÂchesô :
struct process *current = 0;
int n_proc = 0;XIV-E. Exûˋcuter plusieurs tûÂches▲
La fonction principale main() du noyau est trû´s simpleô : elle initialise les structures habituelles puis elle charge les tûÂches utilisateur en mûˋmoire et rûˋtablit les interruptions. û chaque tic d'horloge, l'ordonnanceur est activûˋ et donne la main û une nouvelle tûÂche.
|
|
XV. Un noyau multitûÂche avec des appels systû´me prûˋemptibles▲
- Un scheduler qui tient compte du contexte d'exûˋcutionUn scheduler qui tient compte du contexte d'exûˋcution
- Utiliser les TrapGate pour rendre les appels systû´me interruptiblesUtiliser les TrapGate pour rendre les appels systû´me interruptibles
Sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_MultiTask_Preemptible.tgz
XV-A. Un scheduler qui tient compte du contexte d'exûˋcution▲
XV-A-1. Une pile noyau par tûÂcheô : pourquoiô ?▲
Quand une tûÂche fait un appel systû´me, la pile noyau est automatiquement utilisûˋe par le processeur. Les routines de traitement de cet appel utilisent alors cette pile pour stocker des donnûˋes, passer des paramû´tres û des fonctions, etc. Une fois que l'appel systû´me est terminûˋ, les donnûˋes temporaires sont dûˋpilûˋes et la pile noyau retourne û son ûˋtat initial, tel qu'elle ûˋtait avant l'appel.
Si l'on autorise les interruptions et la commutation de tûÂches pendant un appel systû´me, voilû ce qui risque de se passerô :
- Par exemple, la tûÂche A fait un appel systû´me et utilise la pile noyau pour traiter cet appelô ;
- L'ordonnanceur est activûˋ alors que l'appel n'est pas terminûˋ et il donne la main û la tûÂche Bô ;
- La tûÂche B fait elle aussi un appel systû´me, et elle utilise donc elle aussi la pile du noyau qui contenait dûˋjû les donnûˋes en cours pour le traitement de l'appel de la tûÂche A. û ce moment, la pile noyau contient des donnûˋes de A et des donnûˋes de Bô ;
- L'ordonnanceur active de nouveau la tûÂche A et celle-ci reprend sans se douter que la pile a ûˋtûˋ modifiûˋe. Comme elle va utiliser la pile en supposant qu'elle est dans l'ûˋtat oû¿ elle l'avait laissûˋ, elle va corrompre les donnûˋes de la tûÂche Bô ;
- La tûÂche B reprend, mais la pile est corrompueãÎ et c'est le drameô !
Pour ûˋviter ce scûˋnario catastrophe, il existe une solution trû´s simpleô : il suffit que chaque tûÂche ait sa propre pile noyauô !
XV-A-2. Une pile noyau par tûÂcheô : comment▲
La fonction load_task() est modifiûˋe afin d'associer û chaque tûÂche sa propre pile noyauô : process.c.
#include "lib.h"
#include "mm.h"
#define __PLIST__
#include "process.h"
void load_task(u32 * code_phys_addr, u32 * fn, unsigned int code_size)
{
ô ô ô ô u32 page_base, pages, kstack_base;
ô ô ô ô u32 *pd;
ô ô ô ô int i;
ô ô ô ô /* Copie du code a l'adresse spûˋcifiûˋe */
ô ô ô ô memcpy((char *) code_phys_addr, (char *) fn, code_size);
ô ô ô ô /* Mise a jour du bitmap */
ô ô ô ô page_base = (u32) PAGE(code_phys_addr);
ô ô ô ô if (code_size % PAGESIZE)
ô ô ô ô ô ô ô ô pages = code_size / PAGESIZE + 1;
ô ô ô ô else
ô ô ô ô ô ô ô ô pages = code_size / PAGESIZE;
ô ô ô ô for (i = 0; i < pages; i++)
ô ô ô ô ô ô ô ô set_page_frame_used(page_base + i);
ô ô ô ô /* Crûˋation du rûˋpertoire et des tables de pages */
ô ô ô ô pd = pd_create(code_phys_addr, code_size);
ô ô ô ô kstack_base = (u32) get_page_frame();
ô ô ô ô if (kstack_base > 0x400000) {
ô ô ô ô ô ô ô ô printk("not enough memory to create a kernel stack\n");
ô ô ô ô ô ô ô ô return;
ô ô ô ô }
ô ô ô ô /* Initialisation des registres */
ô ô ô ô p_list[n_proc].pid = n_proc;
ô ô ô ô p_list[n_proc].regs.ss = 0x33;
ô ô ô ô p_list[n_proc].regs.esp = 0x40001000;
ô ô ô ô p_list[n_proc].regs.eflags = 0x0;
ô ô ô ô p_list[n_proc].regs.cs = 0x23;
ô ô ô ô p_list[n_proc].regs.eip = 0x40000000;
ô ô ô ô p_list[n_proc].regs.ds = 0x2B;
ô ô ô ô p_list[n_proc].regs.es = 0x2B;
ô ô ô ô p_list[n_proc].regs.fs = 0x2B;
ô ô ô ô p_list[n_proc].regs.gs = 0x2B;
ô ô ô ô p_list[n_proc].regs.cr3 = (u32) pd;
ô ô ô ô p_list[n_proc].kstack.ss0 = 0x18;
ô ô ô ô p_list[n_proc].kstack.esp0 = kstack_base + PAGESIZE;
ô ô ô ô p_list[n_proc].regs.eax = 0;
ô ô ô ô p_list[n_proc].regs.ecx = 0;
ô ô ô ô p_list[n_proc].regs.edx = 0;
ô ô ô ô p_list[n_proc].regs.ebx = 0;
ô ô ô ô p_list[n_proc].regs.ebp = 0;
ô ô ô ô p_list[n_proc].regs.esi = 0;
ô ô ô ô p_list[n_proc].regs.edi = 0;
ô ô ô ô n_proc++;
}Le code ci-dessous alloue û une tûÂche sa propre pile noyau. Par simplicitûˋ, une pile occupe une pageô :
kstack_base = (u32) get_page_frame();
/* ... */
p_list[n_proc].kstack.ss0 = 0x18;
p_list[n_proc].kstack.esp0 = kstack_base + PAGESIZE;Suite û une interruption, le processeur empile automatiquement des donnûˋes sur la pile noyau de la tûÂche interrompue, sans compter celles ajoutûˋes par les diffûˋrentes routines du noyau. Il est crucial qu'û l'issue d'une interruption, la pile noyau utilisûˋe soit remise dans le mûˆme ûˋtat qu'avant l'interruption.
XV-A-3. L'ordonnanceur▲
La complexitûˋ de l'ordonnanceur provient essentiellement des difficultûˋs induites par la gestion des diffûˋrentes piles noyau et utilisateur.
Le code de l'ordonnanceur est rûˋparti dans deux fichiersô :
- schedule.c contient la partie prûˋparatoire au changement de contexte
#include "types.h"
#include "gdt.h"
#include "process.h"
void switch_to_task(int n, int mode)
{
ô ô ô ô u32 kesp, eflags;
ô ô ô ô u16 kss, ss, cs;
ô ô ô ô current = &p_list[n];
ô ô ô ô /* charger tss */
ô ô ô ô default_tss.ss0 = current->kstack.ss0;
ô ô ô ô default_tss.esp0 = current->kstack.esp0;
ô ô ô ô /*
ô ô ô ô ô * Empile les registres ss, esp, eflags, cs et eip nûˋcessaires a la
ô ô ô ô ô * commutation. Ensuite, la fonction do_switch() restaure les
ô ô ô ô ô * registres, la table de pages du nouveau processus courant et commute
ô ô ô ô ô * avec l'instruction iret.
ô ô ô ô ô */
ô ô ô ô ss = current->regs.ss;
ô ô ô ô cs = current->regs.cs;
ô ô ô ô eflags = (current->regs.eflags | 0x200) & 0xFFFFBFFF;
ô ô ô ô if (mode == USERMODE) {
ô ô ô ô ô ô ô ô kss = current->kstack.ss0;
ô ô ô ô ô ô ô ô kesp = current->kstack.esp0;
ô ô ô ô } else {ô ô ô ô ô ô ô ô /*KERNELMODE */
ô ô ô ô ô ô ô ô kss = current->regs.ss;
ô ô ô ô ô ô ô ô kesp = current->regs.esp;
ô ô ô ô }
ô ô ô ô asm("ô ô mov %0, %%ss; \
ô ô ô ô ô ô ô ô mov %1, %%esp; \
ô ô ô ô ô ô ô ô cmp %[KMODE], %[mode]; \
ô ô ô ô ô ô ô ô je next; \
ô ô ô ô ô ô ô ô push %2; \
ô ô ô ô ô ô ô ô push %3; \
ô ô ô ô ô ô ô ô next: \
ô ô ô ô ô ô ô ô push %4; \
ô ô ô ô ô ô ô ô push %5; \
ô ô ô ô ô ô ô ô push %6; \
ô ô ô ô ô ô ô ô push %7; \
ô ô ô ô ô ô ô ô ljmp $0x08, $do_switch"
ô ô ô ô ô ô ô ô :: \
ô ô ô ô ô ô ô ô "m"(kss), \
ô ô ô ô ô ô ô ô "m"(kesp), \
ô ô ô ô ô ô ô ô "m"(ss), \
ô ô ô ô ô ô ô ô "m"(current->regs.esp), \
ô ô ô ô ô ô ô ô "m"(eflags), \
ô ô ô ô ô ô ô ô "m"(cs), \
ô ô ô ô ô ô ô ô "m"(current->regs.eip), \
ô ô ô ô ô ô ô ô "m"(current), \
ô ô ô ô ô ô ô ô [KMODE] "i"(KERNELMODE), \
ô ô ô ô ô ô ô ô [mode] "g"(mode)
ô ô ô ô ô ô );
}
void schedule(void)
{
ô ô ô ô struct process *p;
ô ô ô ô u32 *stack_ptr;
ô ô ô ô /* Stocke dans stack_ptr le pointeur vers les registres sauvegardes */
ô ô ô ô asm("mov (%?p), %?x; mov %?x, %0": "=m"(stack_ptr) : );
ô ô ô ô /* S'il n'y a pas de processus charge et qu'au moins un est prûˆt, on le charge */
ô ô ô ô if (current == 0 && n_proc) {
ô ô ô ô ô ô ô ô switch_to_task(0, USERMODE);
ô ô ô ô }
ô ô ô ô /*
ô ô ô ô ô * S'il y a un seul processus (qu'on laisse tourner) ou aucun
ô ô ô ô ô * processus, on retourne directement.
ô ô ô ô ô */
ô ô ô ô else if (n_proc <= 1) {
ô ô ô ô ô ô ô ô return;
ô ô ô ô }
ô ô ô ô /* S'il y a au moins deux processus, on commute vers le suivant */
ô ô ô ô else if (n_proc > 1) {
ô ô ô ô ô ô ô ô /* Sauver les registres du processus courant */
ô ô ô ô ô ô ô ô current->regs.eflags = stack_ptr[16];
ô ô ô ô ô ô ô ô current->regs.cs = stack_ptr[15];
ô ô ô ô ô ô ô ô current->regs.eip = stack_ptr[14];
ô ô ô ô ô ô ô ô current->regs.eax = stack_ptr[13];
ô ô ô ô ô ô ô ô current->regs.ecx = stack_ptr[12];
ô ô ô ô ô ô ô ô current->regs.edx = stack_ptr[11];
ô ô ô ô ô ô ô ô current->regs.ebx = stack_ptr[10];
ô ô ô ô ô ô ô ô current->regs.ebp = stack_ptr[8];
ô ô ô ô ô ô ô ô current->regs.esi = stack_ptr[7];
ô ô ô ô ô ô ô ô current->regs.edi = stack_ptr[6];
ô ô ô ô ô ô ô ô current->regs.ds = stack_ptr[5];
ô ô ô ô ô ô ô ô current->regs.es = stack_ptr[4];
ô ô ô ô ô ô ô ô current->regs.fs = stack_ptr[3];
ô ô ô ô ô ô ô ô current->regs.gs = stack_ptr[2];
ô ô ô ô ô ô ô ô if (current->regs.cs != 0x08) {
ô ô ô ô ô ô ô ô ô ô ô ô current->regs.esp = stack_ptr[17];
ô ô ô ô ô ô ô ô ô ô ô ô current->regs.ss = stack_ptr[18];
ô ô ô ô ô ô ô ô } else {ô ô ô ô /* Interruption pendant un appel systeme */
ô ô ô ô ô ô ô ô ô ô ô ô current->regs.esp = stack_ptr[9] + 12;
ô ô ô ô ô ô ô ô ô ô ô ô current->regs.ss = default_tss.ss0;
ô ô ô ô ô ô ô ô }
ô ô ô ô ô ô ô ô /* Sauver le tss */
ô ô ô ô ô ô ô ô current->kstack.ss0 = default_tss.ss0;
ô ô ô ô ô ô ô ô current->kstack.esp0 = default_tss.esp0;
ô ô ô ô ô ô ô ô /* Choix du nouveau processus (un simple roundrobin) */
ô ô ô ô ô ô ô ô if (n_proc > current->pid + 1)
ô ô ô ô ô ô ô ô ô ô ô ô p = &p_list[current->pid + 1];
ô ô ô ô ô ô ô ô else
ô ô ô ô ô ô ô ô ô ô ô ô p = &p_list[0];
ô ô ô ô ô ô ô ô /* Commutation */
ô ô ô ô ô ô ô ô if (p->regs.cs != 0x08)
ô ô ô ô ô ô ô ô ô ô ô ô switch_to_task(p->pid, USERMODE);
ô ô ô ô ô ô ô ô else
ô ô ô ô ô ô ô ô ô ô ô ô switch_to_task(p->pid, KERNELMODE);
ô ô ô ô }
}- sched.asm contient le code qui effectue effectivement le changement de contexte
global do_switch
do_switch:
ô ô ô ô ; rûˋcupûˋrer l'adresse de *current
ô ô ô ô mov esi, [esp]
ô ô ô ô pop eaxô ô ô ô ô ô ô ô ô ; depile @current
ô ô ô ô ; prûˋpare les registres
ô ô ô ô push dword [esi+4]ô ô ô ; eax
ô ô ô ô push dword [esi+8]ô ô ô ; ecx
ô ô ô ô push dword [esi+12]ô ô ô ; edx
ô ô ô ô push dword [esi+16]ô ô ô ; ebx
ô ô ô ô push dword [esi+24]ô ô ô ; ebp
ô ô ô ô push dword [esi+28]ô ô ô ; esi
ô ô ô ô push dword [esi+32]ô ô ô ; edi
ô ô ô ô push dword [esi+48]ô ô ô ; ds
ô ô ô ô push dword [esi+50]ô ô ô ; es
ô ô ô ô push dword [esi+52]ô ô ô ; fs
ô ô ô ô push dword [esi+54]ô ô ô ; gs
ô ô ô ô ; enlû´ve le mask du PIC
ô ô ô ô mov al, 0x20
ô ô ô ô out 0x20, al
ô ô ô ô ; charge table des pages
ô ô ô ô mov eax, [esi+56]
ô ô ô ô mov cr3, eax
ô ô ô ô ; charge les registres
ô ô ô ô pop gs
ô ô ô ô pop fs
ô ô ô ô pop es
ô ô ô ô pop ds
ô ô ô ô pop edi
ô ô ô ô pop esi
ô ô ô ô pop ebp
ô ô ô ô pop ebx
ô ô ô ô pop edx
ô ô ô ô pop ecx
ô ô ô ô pop eax
ô ô ô ô ; retourne
ô ô ô ô iretLe design de l'ordonnanceur est plus compliquûˋ, carô :
- il doit prendre en compte le contexte de la tûÂche lors de son interruptionô ;
- chaque tûÂche a sa propre pile noyauô ;
- l'ordonnanceur change de pile noyau pendant la commutationô ;
- la pile noyau ne contient pas le mûˆme nombre de registres empilûˋs selon que la tûÂche interrompue ûˋtait en mode utilisateur ou en mode noyau. L'interruption d'une tûÂche en mode utilisateur provoque automatiquement l'empilement des registres ss, esp, eflags, cs et eip. Quand l'interruption survient alors que la tûÂche est en mode noyau, les seuls registres empilûˋs sontô : eflags, cs et eip.
Schûˋmas de la pile noyau aprû´s l'interruption d'une tûÂche en mode utilisateurô :
|
|
Schûˋmas de la pile noyau aprû´s l'interruption d'une tûÂche en mode noyauô :
|
|
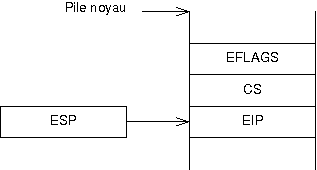
Toutes les contraintes supportûˋes par l'ordonnanceur peuvent se rûˋsumer û ô :
- sauvegarder les registres de la tûÂche interrompueô ;
- remettre la pile noyau dans l'ûˋtat prûˋcûˋdent l'interruption avant de quitter celle-ci.
Le schûˋma suivant reprûˋsente la pile noyau lors de l'appel û la fonction schedule() dans le cas oû¿ le processeur ûˋtait en mode utilisateur lors de l'interruptionô :
|
|
Dans le cas oû¿ le processeur ûˋtait en mode noyau au moment de l'interruption, le schûˋma est trû´s sensiblement diffûˋrent, car les registres ss et esp n'ont pas ûˋtûˋ empilûˋs.
Notre but est de sauvegarder l'ûˋtat de l'ensemble des registres de la tûÂche interrompue, ce qui ne pose aucun problû´me pour l'ensemble d'entre eux (eax, ebx, etc.). La seule difficultûˋ est de retrouver les valeurs de ss et de esp juste avant l'interruption d'horloge, car si l'interruption est survenue pendant un appel systû´me, on ne peut procûˋder de la mûˆme faûÏon pour retrouver ces valeurs, car elles n'ont pas ûˋtûˋ empilûˋesô :
if (current->regs.cs != 0x08) {
ô ô current->regs.esp = stack_ptr[17];
ô ô current->regs.ss = stack_ptr[18];
}
else { /* interruption pendant un appel systeme */
ô ô current->regs.esp = stack_ptr[9] + 12; /* equivalent a : &stack_ptr[17] */
ô ô current->regs.ss = default_tss.ss0;
}- Le premier cas est celui de l'interruption d'une tûÂche en mode utilisateur. L'appel systû´me a sauvegardûˋ tous les registres, dont ss et esp, sur la pile noyau de la tûÂche. C'est un cas assez simple dûˋjû vu au chapitre prûˋcûˋdent.
-
Le deuxiû´me cas concerne l'interruption d'une tûÂche en mode noyau. Le processeur utilisait la mûˆme pile avant l'interruption et esp pointait juste au sommet des registres empilûˋs par l'interruption. Pour retrouver cette valeur, plusieurs calculs sont possiblesô :
- stack_ptr[9] contient la valeur du pointeur de pile juste aprû´s l'interruption (et avant l'appel û push et û pushad). Avant l'interruption, esp pointait sur la mûˆme pile, mais juste avant les trois registres eflags, cs et eip empilûˋs par l'interruption. Nous avons doncô : 3 registres * 4 octets par registre = 12. stack_ptr[9] + 12 pointe donc au sommet de la pile,
- le sommet de la pile est situûˋ 17 registres au-dessus du pointeur stack_ptr, on pourrait donc utiliser l'un des deux calculs suivantsô : stack_ptr + 17 * 4 ou &stack_ptr[17].
Aprû´s avoir sûˋlectionnûˋ une nouvelle tûÂche, pointûˋe par *p, l'ordonnanceur teste si cette nouvelle tûÂche û activer avait ûˋtûˋ interrompue en mode utilisateur ou en mode noyau. La fonction switch_to_task() est appelûˋe avec le pid de la tûÂche û activer et le mode dans lequel il faut l'activerô :
/* commutation */
if (p->regs.cs != 0x08)
ô ô switch_to_task(p->pid, USERMODE);
else
ô ô switch_to_task(p->pid, KERNELMODE);XV-A-3-a. La fonction switch_to_task()▲
La fonction switch_to_task() prûˋpare la commutationô :
- elle change de pile noyau et passe sur la pile de la nouvelle tûÂcheô ;
- elle empile les registres nûˋcessaires û l'instruction iretô ;
- elle passe la main û la fonction do_switch() qui charge les registres et effectue la commutation.
Les variables current->regs.ss, current->regs.cs et current->regs.eflags ne peuvent ûˆtre directement utilisûˋes dans la fonction asm(). Ces trois affectations initialisent des variables qui pourront elles ûˆtre passûˋes en paramû´tre û la fonction assembleurô :
ss = current->regs.ss;
cs = current->regs.cs;
eflags = (current->regs.eflags | 0x200) & 0xFFFFBFFF;Ce code rûˋcupû´re les paramû´tres de la pile noyau pour la nouvelle tûÂche. Si celle-ci est en mode utilisateur, on va utiliser une pile noyau ô¨ô propreô ô£. Si en revanche elle est en mode noyau, il suffit de reprendre les valeurs ss et esp sauvegardûˋes lors du changement de contexteô :
if (mode == USERMODE) {
ô ô kss = current->kstack.ss0;
ô ô kesp = current->kstack.esp0;
}
else { /*KERNELMODE */
ô ô kss = current->regs.ss;
ô ô kesp = current->regs.esp;
}Cette fonction effectue un gros travailô :
- Les deux premiû´res instructions basculent sur la nouvelle pile noyauô ;
- Si la tûÂche est en mode utilisateur, elle empile les valeurs sauvegardûˋes des registres ss et espô ;
- Elle empile les valeurs sauvegardûˋes des registres eflags, cs et eipô ;
- Elle passe la main û la fonction do_switch() qui charge les registres avec les valeurs sauvegardûˋes et effectue la commutation avec iret.
asm(" ô mov %0, %%ss; \
ô ô ô ô mov %1, %%esp; \
ô ô ô ô cmp %[KMODE], %[mode]; \
ô ô ô ô je next; \
ô ô ô ô push %2; \
ô ô ô ô push %3; \
ô ô ô ô next: \
ô ô ô ô push %4; \
ô ô ô ô push %5; \
ô ô ô ô push %6; \
ô ô ô ô push %7; \
ô ô ô ô ljmp $0x08, $do_switch" \
ô ô ô ô :: \
ô ô ô ô "m" (kss), \
ô ô ô ô "m" (kesp), \
ô ô ô ô "m" (ss), \
ô ô ô ô "m" (current->regs.esp), \
ô ô ô ô "m" (eflags), \
ô ô ô ô "m" (cs), \
ô ô ô ô "m" (current->regs.eip), \
ô ô ô ô "m" (current), \
ô ô ô ô [KMODE] "i" (KERNELMODE), \
ô ô ô ô [mode] "g" (mode)
);XV-B. Utiliser les TrapGate pour rendre les appels systû´me interruptibles▲
Les appels systû´me sont rendus interruptiblesô :
init_idt_desc(0x08, (u32) _asm_syscalls, TRAPGATE, &kidt[48]); /* appels systeme - int 0x30 */Pour tester le fait qu'ils sont bien interruptibles, une temporisation est ajoutûˋe pour les rendre plus lentsô : syscalls.c.
#include "types.h"
#include "lib.h"
#include "io.h"
void do_syscalls(int sys_num)
{
ô ô ô ô char *u_str;
ô ô ô ô int i;
ô ô ô ô if (sys_num == 1) {
ô ô ô ô ô ô ô ô asm("mov %?x, %0": "=m"(u_str) :);
ô ô ô ô ô ô ô ô for (i = 0; i < 100000; i++);ô ô /* temporisation */
ô ô ô ô ô ô ô ô cli;
ô ô ô ô ô ô ô ô printk(u_str);
ô ô ô ô ô ô ô ô sti;
ô ô ô ô } else {
ô ô ô ô ô ô ô ô printk("unknown syscall %d\n", sys_num);
ô ô ô ô }
ô ô ô ô return;
}L'utilisation de la fonction cli peut cependant ûˆtre requise, car il n'est pas souhaitable qu'un appel systû´me soit interrompu û certains moments critiques de son exûˋcution. Notamment ici, pour avoir un affichage cohûˋrent, j'ai prûˋfûˋrûˋ dûˋsactiver les interruptions le temps de l'affichage de la chaûÛne.
XVI. Un noyau qui boote avec Grub▲
- Le standard multibootLe standard multiboot
- Un premier noyau minimaliste dûˋmarrûˋ par GrubUn premier noyau minimaliste dûˋmarrûˋ par Grub
- Compiler et linker le noyauCompiler et linker le noyau
- Crûˋer et mettre û jour une image de disquette avec GrubCrûˋer et mettre û jour une image de disquette avec Grub
- Booter Pûˋpin avec GrubBooter Pûˋpin avec Grub
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_GrubEnable.tgz
XVI-A. Le standard multiboot▲
Le document GNU/Multiboot spec. dûˋfinit un standard qui uniformise la sûˋquence de boot des diffûˋrents systû´mes d'exploitation. Grub est un boot loader qui permet de dûˋmarrer un grand nombre de systû´mes diffûˋrents pour peu qu'ils rûˋpondent û ce standard. Pour rûˋpondre û ce standard, un noyau doitô :
- ûˆtre un fichier exûˋcutable 32 bits standardô ;
- l'image du noyau doit inclure un en-tûˆte spûˋcial, le multiboot header, dans ses 8192 premiers octets.
XVI-B. Un premier noyau minimaliste dûˋmarrûˋ par Grub▲
L'utilisation de Grub2 est dûˋtaillûˋe en annexeAnnexe F - Booter avec Grub2
Pour illustrer le boot avec Grub, le package suivant contient un noyau minimaliste rûˋpondant au standard multibootô : kernel_SimpleGrub.tgz
XVI-B-1. L'en-tûˆte▲
global _start, start
extern kmain
ô ô
?fine MULTIBOOT_HEADER_MAGIC ô 0x1BADB002
?fine MULTIBOOT_HEADER_FLAGSô 0x00000003
?fine CHECKSUM -(MULTIBOOT_HEADER_MAGIC + MULTIBOOT_HEADER_FLAGS)
_start:
ô ô ô ô jmp start
; The Multiboot header
align 4
multiboot_header:
dd MULTIBOOT_HEADER_MAGIC
dd MULTIBOOT_HEADER_FLAGS
dd CHECKSUM ô ô
; ----- Multiboot Header Ends Here -----
start:
ô ô ô ô push ebx
ô ô ô ô call kmain
ô ô ô ô cli ; stop interrupts
ô ô ô ô hlt ; halt the CPUXVI-B-1-a. Le programme principal ▲
Grub permet de fournir au noyau plusieurs informations dont la taille de la mûˋmoire physique disponible. Cette information est transmise au noyau via la structure de donnûˋes structô mb_partial_infoô :
void printk(char*, ...);
struct mb_partial_info {
ô ô ô ô unsigned long flags;
ô ô ô ô unsigned long low_mem;
ô ô ô ô unsigned long high_mem;
ô ô ô ô unsigned long boot_device;
ô ô ô ô unsigned long cmdline;
};
ô ô ô ô
void kmain(struct mb_partial_info *mbi)
{
ô ô ô ô printk("Grub example kernel is loaded...\n");
ô ô ô ô printk("RAM detected : %uk (lower), %uk (upper)\n", mbi->low_mem, mbi->high_mem);
ô ô ô ô printk("Done.\n");
}XVI-C. Compiler et linker le noyau▲
La compilation et le linkage pour obtenir le nouveau noyau changent, car il faut que l'en-tûˆte du Multiboot se trouve au dûˋbut de la zone texte. Plusieurs mûˋthodes sont possiblesô :
- Dûˋcrire une section pour l'en-tûˆte et utiliser un script pour le linkage avec ldô ;
- Dûˋcrire une section pour l'en-tûˆte et utiliser ld en ligne de commande avec des paramû´tres approximatifsô ;
- Lors du linkage, mettre le fichier objet boot.o en premier afin qu'il soit relogûˋ au dûˋbut du noyauô :
ld -Ttext=100000 --entry=_start boot.o kernel.o screen.o printk.o -o kernelLa commande shell mbchk permet de vûˋrifier la compatibilitûˋ du noyau gûˋnûˋrûˋ avec le standard Multibootô :
mbchk kernel
kernel: The Multiboot header is found at the offset 4104.
kernel: Page alignment is turned on.
kernel: Memory information is turned on.
kernel: Address fields is turned off.
kernel: All checks passed.On peut aussi vûˋrifier oû¿ sont relogûˋs les diffûˋrents objets avec la commande shell nmô :
nm -n kernel
00100000 T _start
00100008 t multiboot_header
00100014 T start
0010001c T kmain
0010005c T scrollup
001000ec T putcar
00100218 T strlen
00100243 T itoa
00100309 T printk
001016e0 D kY
001016e1 D kattr
001016e4 A __bss_start
001016e4 A _edata
001016e4 B kX
001016e8 A _endXVI-D. Crûˋer et mettre û jour une image de disquette avec Grub▲
La crûˋation d'une telle image nûˋcessite la permission de root.
Le script ci-dessous est potentiellement dangereux et chaque commande exûˋcutûˋe en tant que root sur un systû´me UNIX doit ûˆtre bien comprise. Si une commande du script ci-dessous ne vous semble pas claire, je vous conseille de prendre le temps qu'il faut pour ûˋtudier la documentation accessible via la commande shell man. Mûˆme si cet effort vous semble futile et n'a en apparence pas de rapport avec le dûˋveloppement d'un noyau, je vous garantis que les connaissances acquises vous seront trû´s utiles. Pour ceux qui dûˋbutent en administration systû´me, je recommande l'excellentissime Guide du Rootard.
# crûˋation d'une image vide avec ext2fs
dd if=/dev/zero of=floppyA bs=1024 count=1440
mkfs floppyA
sudo -s
# montage de l'image
mkdir /mnt/loop
mount -o loop -t ext2 floppyA /mnt/loop
# crûˋation de l'arborescence initiale
mkdir /mnt/loop/grub
cp /boot/grub/stage* /mnt/loop/grub
cat > /mnt/loop/grub/menu.lst << EOF
title=Pepin
root (fd0)
kernel /kernel
boot
EOF
cp kern/kernel /mnt/loop
umount /mnt/loop
# installation de grub
grub --device-map=/dev/null << EOF
device (fd0) floppyA
root (fd0)
setup (fd0)
quit
EOFUne fois l'image construite, la mise û jour du noyau est plus simpleô :
mount -o loop -t ext2 floppyA /mnt/loop
cp kern/kernel /mnt/loop
umount /mnt/loopXVI-E. Booter Pûˋpin avec Grub▲
Le noyau est chargûˋ par Grub en 0x100000.
Certaines plages d'adresses sont rûˋservûˋes par le noyau ou pour le hardwareô :
|
0x0 |
0xFFF |
GDT et IDT |
|
0x1000 |
0x9FFFF |
libre |
|
0xA0000 |
0xFFFFF |
rûˋservûˋ pour le hardware |
|
0x100000 |
0x1FFFFF |
rûˋservûˋ pour le noyau |
|
0x200000 |
max |
libre |
|
|
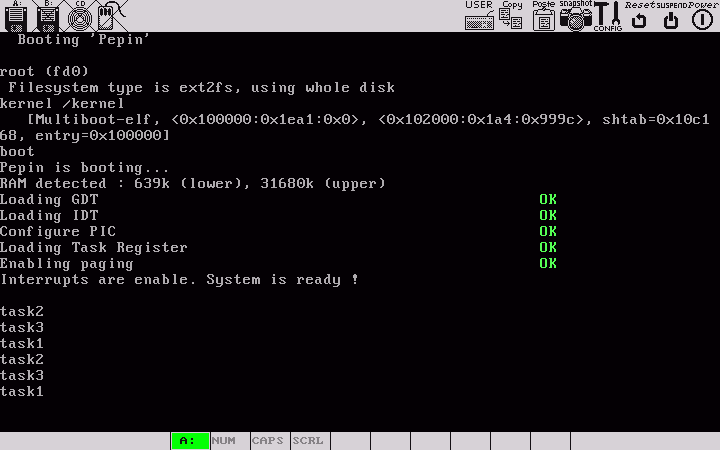
XVII. Gûˋrer la mûˋmoire physique et la mûˋmoire virtuelle▲
- Une nouvelle organisation de la mûˋmoire physique et de la mûˋmoire virtuelleUne nouvelle organisation de la mûˋmoire physique et de la mûˋmoire virtuelle
- Allouer dynamiquement de la mûˋmoire pour le noyauAllouer dynamiquement de la mûˋmoire pour le noyau
- Mettre û jour le rûˋpertoire et les tables de pagesMettre û jour le rûˋpertoire et les tables de pages
- Complûˋments sur les rûˋpertoires de pagesComplûˋments sur les rûˋpertoires de pages
- Complûˋments sur la paginationComplûˋments sur la pagination
- Structure d'une tûÂcheStructure d'une tûÂche
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_AdvMemory.tgz.
XVII-A. Une nouvelle organisation de la mûˋmoire physique et de la mûˋmoire virtuelle▲
XVII-A-1. Comment gûˋrer ô¨ô lesô ô£ mûˋmoires▲
Nous avons vu que le noyau gû´re deux types de mûˋmoireô : la mûˋmoire physique, rûˋellement disponible et utilisable, et la mûˋmoire virtuelle. û tout moment, le noyau a besoin de savoir quels sont les espaces de mûˋmoire physique et virtuelle qui sont utilisûˋs et libres et cela passe par la mise en placeô :
- d'une organisation claire de la mûˋmoire physique et de la mûˋmoire virtuelleô ;
- de deux systû´mes de gestion de la mûˋmoire (un pour chaque type de mûˋmoire) afin de rûˋpondre aux besoins du noyau et des tûÂches utilisateur.
Cette ûˋtape du dûˋveloppement du noyau est assez dûˋlicate en raison des contraintes liûˋes û la pagination. Le but de cette partie est nûˋanmoins de prûˋsenter un systû´me de gestion de la mûˋmoire le plus simple possible. Mais contrairement aux chapitres prûˋcûˋdents, peu de code est prûˋsentûˋ ici. L'accent est avant tout mis sur les enjeux et la logique sous-tendant la mise en place d'une gestion de la mûˋmoire.
XVII-A-2. Utilisation de la mûˋmoire physique▲
Le noyau connaûÛt la taille de la mûˋmoire physique disponible grûÂce û GrubUn noyau qui boote avec Grub.
Dans l'implûˋmentation de Pûˋpin, les 8 premiers mûˋgaoctets de mûˋmoire physique sont rûˋservûˋs û l'usage du noyau et contiennentô :
- le noyauô ;
- les structures ûˋlûˋmentaires (GDT, IDT et TSS)ô ;
- la pile noyauô ;
- une partie rûˋservûˋe au hardwareô ;
- le rûˋpertoire de pages et les tables de pages du noyau.
Le reste de la mûˋmoire physique est librement disponible pour le noyau et les applicationsô :
|
|
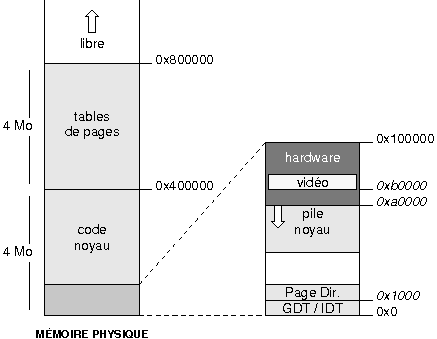
XVII-A-3. Utilisation de la mûˋmoire virtuelle▲
L'espace d'adressage compris entre le dûˋbut de la mûˋmoire et l'adresse 0x40000000 correspond û l'espace du noyau alors que l'espace compris entre l'adresse 0x40000000 et la fin de la mûˋmoire correspond û l'espace utilisateurô :
|
|
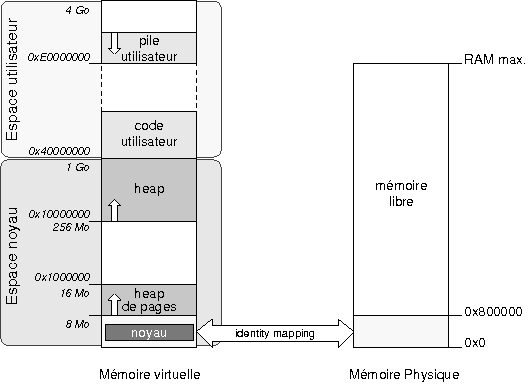
L'espace d'adressage noyau, qui occupe 1 Gigaoctet de mûˋmoire virtuelle, est commun û toutes les tûÂches (cette notion est essentielleô ! Elle est expliquûˋe en dûˋtail dans la partie traitant du dûˋroulement d'une tûÂche dans une espace paginûˋGûˋrer la mûˋmoire - utiliser la pagination pour une tûÂche utilisateur). Ceci est implûˋmentûˋ trû´s simplement en faisant pointer les 256 premiû´res entrûˋes du rûˋpertoire de pages de la tûÂche sur le rûˋpertoire de pages du noyauô :
/*
ô * Espace noyau. Les v_addr < USER_OFFSET sont adressûˋes par la table
ô * de pages du noyau.
ô */
ô for (i=0; i<256; i++)
ô ô ô ô ô pdir[i] = pd0[i];Les 8 premiers mûˋgaoctets de mûˋmoire virtuelle et de mûˋmoire physique sont mappûˋs û l'identique. Les raisons ont dûˋjû ûˋtûˋ expliquûˋes dans les chapitres prûˋcûˋdents.
XVII-B. Allouer dynamiquement de la mûˋmoire pour le noyau▲
XVII-B-1. Gûˋrer la mûˋmoire physique▲
La gestion de la mûˋmoire physique est basûˋe sur l'utilisation d'un bitmap qui contient le statut des diffûˋrentes pages. Les fonctions qui permettent de manipuler ce bitmap sont les suivantesô :
- get_page_frame() renvoie l'adresse d'une page libre et la marque comme utilisûˋe. Cette fonction est utilisûˋe quand le noyau a besoin d'une page physique libreô ;
- release_page_frame() libû´re une page prûˋcûˋdemment utilisûˋeô ;
- set_page_frame_used() marque une page comme ûˋtant utilisûˋe.
XVII-B-2. Gûˋrer la mûˋmoire virtuelle▲
L'utilisation de la pagination nûˋcessite qu'û chaque adresse physique soit associûˋe une adresse virtuelle, puisque c'est celle-ci qui sera directement manipulûˋe par les instructions du processeur. Pour pouvoir faire cette association, il faut gûˋrer les adresses virtuelles. Deux gestionnaires d'adresses virtuelles, rûˋpondant û des besoins diffûˋrents, sont utilisûˋs par Pûˋpin.
XVII-B-2-a. Le heap▲
La premiû´re fonction d'allocation de mûˋmoire pour le noyau s'apparente û la fonction malloc() de la bibliothû´que C standard. Il s'agit de la fonction kmalloc() qui permet d'allouer au noyau un nombre arbitraire d'octets. La fonction kfree() s'apparente û la fonction free() de la bibliothû´que standard et libû´re une zone de mûˋmoire prûˋcûˋdemment allouûˋe par kmalloc().
Le Heap est une zone extensible, segmentûˋe en blocs de donnûˋes, et dans laquelle vient piocher kmalloc(). Le bloc d'octets disponibles pris dans le heap par kmalloc() est organisûˋ tel que dans le schûˋma ci-dessous avec un en-tûˆte et une zone de donnûˋes. L'en-tûˆte occupe 4 octetsô :
- 31 bits sont utilisûˋs pour prûˋciser la taille du blocô ;
- 1 bit est utilisûˋ pour indiquer si le bloc est libre ou non.
|
|
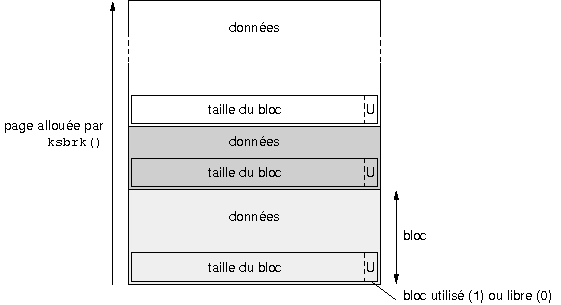
Quand kmalloc() fait une demande de mûˋmoire, le noyau parcourt le heap afin de trouver un bloc libre suffisamment grand. Si un tel bloc existe, la fonction renvoie l'adresse de la zone de donnûˋes de ce bloc. Si le bloc trouvûˋ est trop grand, celui-ci est scindûˋ en deux et un second bloc libre est crûˋûˋ. Si le heap ne contient pas de bloc suffisamment grand, la fonction ksbrk() est appelûˋe par kmalloc() pour ûˋtendre le heap.
û noter qu'au dûˋmarrage, le Heap est initialisûˋ et il comprend un seul ô¨ô blocô ô£.
Dans le dûˋtail, la fonction ksbrk() ûˋtend le heap en ajoutant û son espace d'adressage une page virtuelle. Parallû´lement û ûÏa, la fonction demande une page de mûˋmoire physique avec get_page_frame() puis elle associe la nouvelle adresse virtuelle û cette page en mûˋmoire physique en mettant û jour le rûˋpertoire de pages.
Toutes ces fonctions peuvent ûˆtre testûˋes dans l'espace utilisateur sous Unix avant d'ûˆtre implûˋmentûˋes au niveau du noyau. Cela simplifie grandement le dûˋveloppementô !
XVII-B-2-b. Le heap de pages▲
La fonction kmalloc() rûˋpond û l'essentiel des besoins d'allocation mûˋmoire du noyau. Il y a cependant un cas particulier d'allocation non supportûˋe par cette fonction, c'est quand le noyau a besoin d'une page alignûˋe sur 4096 octets, par exemple pour crûˋer une nouvelle table de pages.
Pour rûˋpondre û ce besoin, le noyau utilise un entrepûÇt de donnûˋes particulierô : le heap de pages. Le Heap de pages est est une zone d'environ 256 Mo au sein de laquelle l'allocation se fait par page (de 4096 octets). L'ensemble des pages disponibles aurait pu ûˆtre implûˋmentûˋ û l'aide d'une liste chaûÛnûˋe, mais j'ai prûˋfûˋrûˋ dûˋfinir une liste des ô¨ô zonesô ô£ libres, une zone reprûˋsentant ici une simple plage mûˋmoireô :
|
|
Les fonctions de manipulation du Heap de pages sontô :
- get_page_from_heap(), qui renvoie une page libreô ;
- release_page_from_heap(), qui libû´re une page utilisûˋe.
XVII-B-2-c. Quand le noyau n'a plus assez de mûˋmoire▲
Nous avons donc vu que le noyau utilise deux fonctions, kmalloc() et get_page_from_heap(), pour avoir de la mûˋmoire. Mais que se passe-t-il quand il n'y a plus assez de mûˋmoire physique ou virtuelleô ? Dans une implûˋmentation propreô :
- ces deux fonctions doivent renvoyer une valeur pour signifier un ûˋchecô ;
- chaque appel de ces deux fonctions doit tester le code de retour pour sortir proprement.
J'ai fait un autre choix pour Pûˋpinô : en cas d'ûˋchec, ces fonctions affichent un message sur la console et stoppent le systû´meô ! C'est assez radical, certes, mais cela permet de conserver au code de Pûˋpin un maximum de simplicitûˋ et de concision. Gardez cependant û l'esprit que cela n'est pas une bonne pratique de la programmationô !
XVII-C. Mettre û jour le rûˋpertoire et les tables de pages▲
Comment modifier une entrûˋe du rûˋpertoire de pages courant ou d'une table de pages de ce dernierô ? Cette question peut sembler assez ûˋtrange, mais elle cache en rûˋalitûˋ un vrai problû´me que je vais essayer d'exposer briû´vement.
Nous savons qu'avec la pagination, toutes les adresses utilisûˋes sont virtuelles. Cela rend difficile la manipulation directe d'une adresse physique. Supposons par exemple que je veuille modifier une donnûˋe situûˋe û l'adresse physique @p. Je ne peux directement utiliser cette adresseô ! Il faut nûˋcessairement que je passe par une adresse virtuelle @v associûˋe û @p grûÂce au rûˋpertoire de pages. On ne peut utiliser directement une adresse physiqueô !
Supposons maintenant que je veuille mettre û jour le rûˋpertoire de pages courant, ce qui est une opûˋration assez frûˋquente du noyau. La mise û jour du rûˋpertoire en tant que tel ne devrait pas poser trop de problû´mes. En revanche, cette mise û jour suppose la plupart du temps celle d'une table de pages. Nous savons que le rûˋpertoire de pages contient les adresses des tables de pages. Jusque lû , tout û l'air trû´s simple, mais il y a en rûˋalitûˋ un ûˋnorme problû´meãÎ le rûˋpertoire contient les adresses physiques des tables de pagesô ! Dans ce cas, comment accûˋder û une table de pages pour la modifierô ?
Plusieurs solutions existent. L'une d'elles est d'associer û chaque rûˋpertoire de pages une structure ou un tableau contenant les adresses virtuelles de ses tables de pages. L'inconvûˋnient de cette solution est qu'elle nûˋcessite la mise û jour d'une structure pour chaque rûˋpertoire de pages. Une autre solution est de rûˋserver la derniû´re entrûˋe du rûˋpertoire de pages en la faisant pointer sur le rûˋpertoire de pages lui-mûˆme. Cela semble û premiû´re vue assez ûˋtrange, mais cette astuce permet en fait de manipuler le rûˋpertoire ou les tables de pages trû´s facilement. C'est cette solution qui est exposûˋe ci-dessous.
XVII-C-1. Rappel sur le mûˋcanisme de pagination▲
Le mûˋcanisme utilisûˋ par la pagination pour traduire une adresse linûˋaire en une adresse physique a dûˋjû ûˋtûˋ vu. Cette adresse se dûˋcompose en trois index (ici x, y et z)ô :
|
|
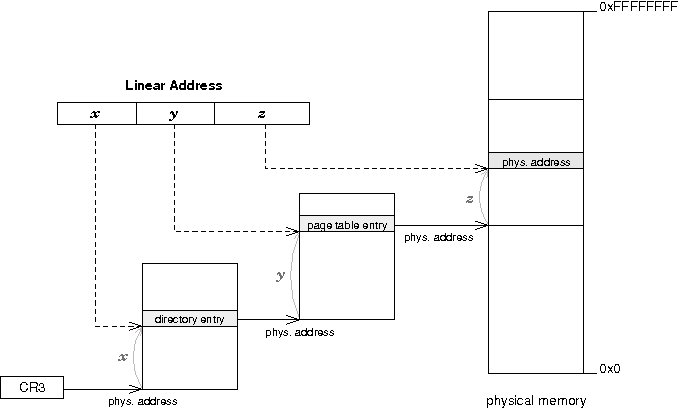
XVII-C-2. Modifier les tables de pages▲
Admettons que nous voulions modifier l'entrûˋe de la table de pages qui sert l'adresse virtuelle x.y.z. GrûÂce û la derniû´re entrûˋe du rûˋpertoire de pages qui est initialisûˋe de faûÏon û pointer sur le rûˋpertoire de pages lui-mûˆme, l'utilisation de l'adresse 0x3FF.x.y permet de modifier l'entrûˋe proprement dite.
L'utilisation de 0x3FF en dûˋbut d'adresse fait que le rûˋpertoire de pages va ûˆtre utilisûˋ comme si c'ûˋtait une table de pages. Ensuite, la xe entrûˋe pointe sur la table de pages et la ye entrûˋe pointe sur l'endroit û modifier proprement ditô :
|
|

Ce schûˋma et cette explication ne sont pas forcement trû´s facile û comprendre en raison de la complexitûˋ mûˆme du systû´me de pagination. Pour que tout devienne plus clair, je vous conseille de faire mentalement plusieurs fois le cheminement conduisant û la traduction d'adresse en regardant bien les schûˋmas prûˋcûˋdents.
XVII-C-3. Modifier le rûˋpertoire▲
Pour modifier l'entrûˋe du rûˋpertoire de pages correspondant û l'adresse virtuelle x.y.z, il faut utiliser l'adresse 0x3FF.0x3FF.x. La logique est la mûˆme que prûˋcûˋdemment avec juste un niveau supplûˋmentaire de rûˋcursionô :
|
|
XVII-D. Complûˋments sur les rûˋpertoires de pages▲
Lors de la crûˋation d'une tûÂche utilisateur, un rûˋpertoire de pages dûˋdiûˋ est crûˋûˋ. Nous avons vu qu'un rûˋpertoire peut ûˆtre accompagnûˋ de 1024 tables de pages de 4 Mo chacune. Afin d'optimiser l'espace utilisûˋ en mûˋmoire, les tables sont seulement crûˋûˋes en cas de besoin, lors de la mise û jour d'une entrûˋe du rûˋpertoire. La structure struct page_directory conserve la trace de ces allocations afin de pouvoir tout supprimer proprement quand une tûÂche se termineô :
|
|
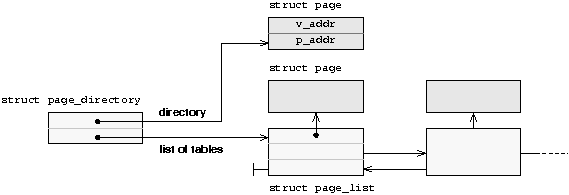
XVII-E. Complûˋments sur la pagination▲
XVII-E-1. Utiliser des pages de 4 Mo▲
La pagination permet de gûˋrer des pages de 4 Mo. Dans ce cas, l'entrûˋe du rûˋpertoire de pages pointe directement sur la page allouûˋe (sans passer par une table de pages). Ce mode d'adressage nûˋcessiteô :
- l'activation du bit 4 du registre CR4 (Page Size Extenstion)ô ;
- le flag PS de l'entrûˋe dans le rûˋpertoire de pages û 1.
|
|
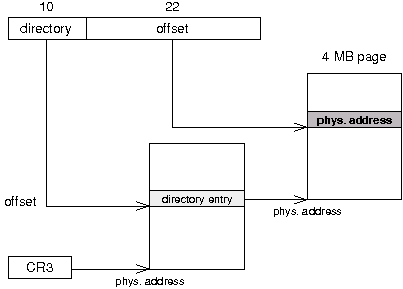
Les entrûˋes du rûˋpertoire de pages sont au format suivantô :
|
|

- le bit P indique si la page ou la table pointûˋe est en mûˋmoire physique
- le bit R/W indique si la page ou la table est accessible en ûˋcriture (bit û 1)
- le bit U/S est û 1 pour permettre l'accû´s aux tûÂches non privilûˋgiûˋes
- le bit PWT et le bit PCD sont liûˋs û la gestion du cache des pages, que nous ne verrons pas pour le moment
- le bit A indique si la page ou la table a ûˋtûˋ accûˋdûˋe
- le bit D (table de pages seulement) indique si la page a ûˋtûˋ ûˋcrite
- le bit PS est û 1 pour spûˋcifier une taille de pages de 4ô Mo
- le bit G est liûˋ û la gestion du cache des pages
- le champ Avail. est librement utilisable
XVII-E-2. Mettre û jour le TLB▲
Quand la pagination est activûˋe, la MMU se base sur le rûˋpertoire et les tables de pages pour traduire les adresses virtuelles en adresses physiques. Un cache, le Translation lookaside buffer (TLB) est utilisûˋ pour augmenter la vitesse de traduction des adresses. Mais quand une entrûˋe de rûˋpertoire ou d'une table de pages est modifiûˋe, le cache n'est pas automatiquement mis û jour. Par consûˋquent, si la MMU continue d'utiliser le cache pour l'entrûˋe en question, le rûˋsultat de la traduction d'adresses sera erronûˋ. La mise û jour du cache doit donc ûˆtre forcûˋe par l'utilisateur et nous disposons pour cela de plusieurs moyensô :
- recharger le registre CR3 rûˋinitialise le cacheô ;
- l'instruction assembleur invlpg avec en paramû´tre une adresse virtuelle rûˋinitialise l'entrûˋe associûˋe du TLB.
asm("invlpg %0"::"m"(v_addr));XVII-F. Structure d'une tûÂche▲
La structure struct process contient toutes les informations associûˋes û une tûÂche. Outre les registres du processeur et le pid, cette structure permet de garder une trace des pages allouûˋes pour cette tûÂcheô :
|
|
XVIII. Lire et ûˋcrire sur un disque IDE▲
- ûcrire et lire sur un disque IDE avec les PIOLire et ûˋcrire sur un disque IDE
- Crûˋer et utiliser une image d'un disque dur sous UnixCrûˋer et utiliser une image d'un disque dur sous Unix
- TesterTester
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_Disk.tgz
XVIII-A. ûcrire et lire sur un disque IDE avec les PIO▲
Il existe deux mûˋthodes possibles pour ûˋcrire et lire sur une unitûˋ de disque IDEô : l'utilisation des ports du processeur (PIO) et l'utilisation du DMA. L'implûˋmentation dûˋcrite ici utilise les ports du processeur. Les accû´s disque sont assez lents avec cette mûˋthode, mais avec l'avantage d'une implûˋmentation trû´s simpleô :
#include "types.h"
#include "io.h"
int bl_common(int drive, int numblock, int count)
{
ô ô ô ô outb(0x1F1, 0x00);ô ô ô /* NULL byte to port 0x1F1 */
ô ô ô ô outb(0x1F2, count);ô ô ô /* Sector count */
ô ô ô ô outb(0x1F3, (unsigned char) numblock);ô /* Low 8 bits of the block address */
ô ô ô ô outb(0x1F4, (unsigned char) (numblock >> 8));ô ô /* Next 8 bits of the block address */
ô ô ô ô outb(0x1F5, (unsigned char) (numblock >> 16));ô /* Next 8 bits of the block address */
ô ô ô ô /* Drive indicator, magic bits, and highest 4 bits of the block address */
ô ô ô ô outb(0x1F6, 0xE0 | (drive << 4) | ((numblock >> 24) & 0x0F));
ô ô ô ô return 0;
}
int bl_read(int drive, int numblock, int count, char *buf)
{
ô ô ô ô u16 tmpword;
ô ô ô ô int idx;
ô ô ô ô bl_common(drive, numblock, count);
ô ô ô ô outb(0x1F7, 0x20);
ô ô ô ô /* Wait for the drive to signal that it's ready: */
ô ô ô ô while (!(inb(0x1F7) & 0x08));
ô ô ô ô for (idx = 0; idx < 256 * count; idx++) {
ô ô ô ô ô ô ô ô tmpword = inw(0x1F0);
ô ô ô ô ô ô ô ô buf[idx * 2] = (unsigned char) tmpword;
ô ô ô ô ô ô ô ô buf[idx * 2 + 1] = (unsigned char) (tmpword >> 8);
ô ô ô ô }
ô ô ô ô return count;
}
int bl_write(int drive, int numblock, int count, char *buf)
{
ô ô ô ô u16 tmpword;
ô ô ô ô int idx;
ô ô ô ô bl_common(drive, numblock, count);
ô ô ô ô outb(0x1F7, 0x30);
ô ô ô ô /* Wait for the drive to signal that it's ready: */
ô ô ô ô while (!(inb(0x1F7) & 0x08));
ô ô ô ô for (idx = 0; idx < 256 * count; idx++) {
ô ô ô ô ô ô ô ô tmpword = (buf[idx * 2 + 1] << 8) | buf[idx * 2];
ô ô ô ô ô ô ô ô outw(0x1F0, tmpword);
ô ô ô ô }
ô ô ô ô return count;
}XVIII-B. Crûˋer et utiliser une image d'un disque dur sous Unix▲
Il faut crûˋer une image d'un disque dur, par exemple en utilisant la commande bximageô :
bximage
> hd
> flat
> 2
> c.imgEnsuite, il faut ajouter dans le fichier de configuration de Bochs une entrûˋe sur ce modû´leô :
ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14
ata0-master: type=disk, path="c.img", mode=flat, cylinders=4, heads=16, spt=63XVIII-C. Tester ▲
Le code ci-dessous inscrit une chaûÛne de caractû´res sur l'image de disque û l'offset 1024 (bloc numûˋro 2) avec la fonction bl_write()ô :
char *buf, *msg = "Hello world\n";
buf = (char *) kmalloc(512);
memcpy((char *) buf, (char *) msg, strlen(msg) + 1);
bl_write(0, 2, 1, buf);Pour vûˋrifier que l'ûˋcriture a bien eu lieuô :
od -A d -c c.img
0000000 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
*
0001024 H e l l o w o r l d \n \0 \0 \0 \0
0001040 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
*
2064384Pour lire cette inscription, on procû´de de faûÏon similaire avec la fonction bl_read()ô :
bl_read(0, 2, 1, buf);
printk("buf: %s\n", buf);XIX. Utiliser un systû´me de fichiers Ext2FS▲
- Description d'un systû´me de fichiers Ext2FSDescription d'un systû´me de fichiers Ext2FS
- Lecture dans un systû´me de fichiers Ext2FSLecture dans un systû´me de fichiers Ext2FS
- Crûˋer et utiliser une image d'un disque dur sous Unix avec un systû´me de fichiers Ext2FSCrûˋer et utiliser une image d'un disque dur sous Unix avec un systû´me de fichier Ext2FS
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_Ext2Read.tgz
XIX-A. Description d'un systû´me de fichiers Ext2FS▲
XIX-A-1. Un disque subdivisûˋ en groupes▲
Quand on dûˋpose sur un disque un systû´me de fichiers de type Ext2, on inscrit sur celui-ci une structure particuliû´re afin de stocker et d'organiser des donnûˋes. La premiû´re partie du disque, de 1024 octets, est rûˋservûˋe au secteur de boot. Le reste du disque est divisûˋ en groupes. Chaque groupe contient un en-tûˆte et une zone pour les donnûˋesô :
|
|
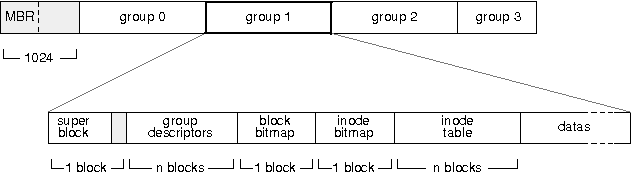
L'en-tûˆte de chaque groupe contient notamment les informations fondamentales dûˋcrivant la structure globale du systû´me de fichiers. Chaque groupe possû´de une copie de ces informationsô :
- le superbloc contient les informations gûˋnûˋrales dûˋcrivant l'organisation logique du disqueô ;
- l'espace group descriptors est un tableau contenant l'ensemble des descripteurs de groupes. Pour chaque groupe, un descripteur contient les informations dûˋcrivant l'organisation spûˋcifique des donnûˋes en son sein.
Le reste de l'en-tûˆte contient les structures dûˋcrivant l'organisation des donnûˋes spûˋcifiques û ce groupeô :
- le bloc bitmap indique pour chaque bloc de ce groupe s'il est libre ou utilisûˋô ;
- le bloc inode bitmap indique pour chaque inode de ce groupe si elle est libre ou utilisûˋeô ;
- l'espace inode table contient la liste des inodes de ce groupe.
XIX-B. Lecture dans un systû´me de fichiers Ext2FS▲
Au prûˋalable, le noyau doit rûˋcupûˋrer les informations dûˋcrivant l'organisation globale des donnûˋes sur le disque. Ces donnûˋes sont consignûˋes dans le superbloc et dans le tableau de descripteurs de groupes. Ensuite, en se servant de son numûˋro d'inode, il n'est pas si difficile que ûÏa de retrouver les informations relatives û un fichier et d'en lire le contenu.
Les fonctions de manipulation du systû´me de fichiers peuvent ûˆtre testûˋes dans l'espace utilisateur sous Unix avant d'ûˆtre implûˋmentûˋes au niveau du noyau. Pour ne pas risquer de corrompre un disque logique utilisûˋ par le systû´me, il est plus prudent de crûˋer un disque virtuel dans un fichier qui servira pour l'occasion.
XIX-B-1. Le superbloc▲
Le superbloc contient les informations relatives û l'organisation globale du systû´me de fichiers, sa structure est dûˋtaillûˋe dans le fichier ext2.h. Le superbloc fait une taille de 1024 octets. Si la taille des blocs est supûˋrieure û 1024 ko, du padding est ajoutûˋ afin que l'espace group descriptors soit alignûˋ sur cette taille de bloc. L'offset de la zone group descriptor dûˋpend de la taille des blocsô :
|
|
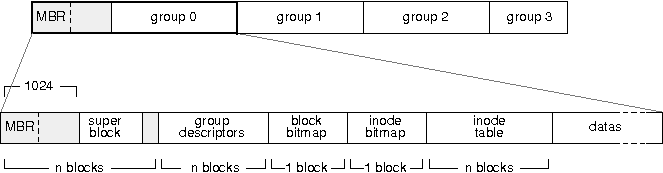
#include "types.h"
struct ext2_super_block {
ô ô ô ô u32 s_inodes_count;ô ô ô /* Total number of inodes */
ô ô ô ô u32 s_blocks_count;ô ô ô /* Total number of blocks */
ô ô ô ô u32 s_r_blocks_count;ô ô /* Total number of blocks reserved for the super user */
ô ô ô ô u32 s_free_blocks_count;ô ô ô ô /* Total number of free blocks */
ô ô ô ô u32 s_free_inodes_count;ô ô ô ô /* Total number of free inodes */
ô ô ô ô u32 s_first_data_block;ô /* Id of the block containing the superblock structure */
ô ô ô ô u32 s_log_block_size;ô ô /* Used to compute block size = 1024 << s_log_block_size */
ô ô ô ô u32 s_log_frag_size;ô ô /* Used to compute fragment size */
ô ô ô ô u32 s_blocks_per_group;ô /* Total number of blocks per group */
ô ô ô ô u32 s_frags_per_group;ô /* Total number of fragments per group */
ô ô ô ô u32 s_inodes_per_group;ô /* Total number of inodes per group */
ô ô ô ô u32 s_mtime;ô ô ô ô ô ô /* Last time the file system was mounted */
ô ô ô ô u32 s_wtime;ô ô ô ô ô ô /* Last write access to the file system */
ô ô ô ô u16 s_mnt_count;ô ô ô ô /* How many `mount' since the last was full verification */
ô ô ô ô u16 s_max_mnt_count;ô ô /* Max count between mount */
ô ô ô ô u16 s_magic;ô ô ô ô ô ô /* = 0xEF53 */
ô ô ô ô u16 s_state;ô ô ô ô ô ô /* File system state */
ô ô ô ô u16 s_errors;ô ô ô ô ô ô /* Behaviour when detecting errors */
ô ô ô ô u16 s_minor_rev_level;ô /* Minor revision level */
ô ô ô ô u32 s_lastcheck;ô ô ô ô /* Last check */
ô ô ô ô u32 s_checkinterval;ô ô /* Max. time between checks */
ô ô ô ô u32 s_creator_os;ô ô ô ô /* = 5 */
ô ô ô ô u32 s_rev_level;ô ô ô ô /* = 1, Revision level */
ô ô ô ô u16 s_def_resuid;ô ô ô ô /* Default uid for reserved blocks */
ô ô ô ô u16 s_def_resgid;ô ô ô ô /* Default gid for reserved blocks */
ô ô ô ô u32 s_first_ino;ô ô ô ô /* First inode useable for standard files */
ô ô ô ô u16 s_inode_size;ô ô ô ô /* Inode size */
ô ô ô ô u16 s_block_group_nr;ô ô /* Block group hosting this superblock structure */
ô ô ô ô u32 s_feature_compat;
ô ô ô ô u32 s_feature_incompat;
ô ô ô ô u32 s_feature_ro_compat;
ô ô ô ô u8 s_uuid[16];ô ô ô ô ô /* Volume id */
ô ô ô ô char s_volume_name[16];ô /* Volume name */
ô ô ô ô char s_last_mounted[64];ô ô ô ô /* Path where the file system was last mounted */
ô ô ô ô u32 s_algo_bitmap;ô ô ô /* For compression */
ô ô ô ô u8 s_padding[820];
} __attribute__ ((packed));
struct disk {
ô ô ô ô int device;
ô ô ô ô struct ext2_super_block *sb;
ô ô ô ô u32 blocksize;
ô ô ô ô u16 groups;ô ô ô ô ô ô ô /* Total number of groups */
ô ô ô ô struct ext2_group_desc *gd;
};
struct ext2_group_desc {
ô ô ô ô u32 bg_block_bitmap;ô ô /* Id of the first block of the "block bitmap" */
ô ô ô ô u32 bg_inode_bitmap;ô ô /* Id of the first block of the "inode bitmap" */
ô ô ô ô u32 bg_inode_table;ô ô ô /* Id of the first block of the "inode table" */
ô ô ô ô u16 bg_free_blocks_count;ô ô ô ô /* Total number of free blocks */
ô ô ô ô u16 bg_free_inodes_count;ô ô ô ô /* Total number of free inodes */
ô ô ô ô u16 bg_used_dirs_count;ô /* Number of inodes allocated to directories */
ô ô ô ô u16 bg_pad;ô ô ô ô ô ô ô /* Padding the structure on a 32bit boundary */
ô ô ô ô u32 bg_reserved[3];ô ô ô /* Future implementation */
} __attribute__ ((packed));
struct ext2_inode {
ô ô ô ô u16 i_mode;ô ô ô ô ô ô ô /* File type + access rights */
ô ô ô ô u16 i_uid;
ô ô ô ô u32 i_size;
ô ô ô ô u32 i_atime;
ô ô ô ô u32 i_ctime;
ô ô ô ô u32 i_mtime;
ô ô ô ô u32 i_dtime;
ô ô ô ô u16 i_gid;
ô ô ô ô u16 i_links_count;
ô ô ô ô u32 i_blocks;ô ô ô ô ô ô /* 512 bytes blocks ! */
ô ô ô ô u32 i_flags;
ô ô ô ô u32 i_osd1;
ô ô ô ô /*
ô ô ô ô ô * [0] -> [11] : block number (32 bits per block)
ô ô ô ô ô * [12] ô ô ô ô : indirect block number
ô ô ô ô ô * [13] ô ô ô ô : bi-indirect block number
ô ô ô ô ô * [14] ô ô ô ô : tri-indirect block number
ô ô ô ô ô */
ô ô ô ô u32 i_block[15];
ô ô ô ô u32 i_generation;
ô ô ô ô u32 i_file_acl;
ô ô ô ô u32 i_dir_acl;
ô ô ô ô u32 i_faddr;
ô ô ô ô u8 i_osd2[12];
} __attribute__ ((packed));
struct directory_entry {
ô ô ô ô u32 inode;ô ô ô ô ô ô ô /* inode number or 0 (unused) */
ô ô ô ô u16 rec_len;ô ô ô ô ô ô /* offset to the next dir. entry */
ô ô ô ô u8 name_len;ô ô ô ô ô ô /* name length */
ô ô ô ô u8 file_type;
ô ô ô ô char name;
} __attribute__ ((packed));
/* super_block: s_errors */
#defineô EXT2_ERRORS_CONTINUEô ô 1
#defineô EXT2_ERRORS_ROô ô ô ô ô 2
#defineô EXT2_ERRORS_PANICô ô ô ô 3
#defineô EXT2_ERRORS_DEFAULTô ô ô 1
/* inode: i_mode */
#defineô EXT2_S_IFMTô ô ô 0xF000ô /* format mask ô */
#defineô EXT2_S_IFSOCKô ô 0xC000ô /* socket */
#defineô EXT2_S_IFLNKô ô 0xA000ô /* symbolic link */
#defineô EXT2_S_IFREGô ô 0x8000ô /* regular file */
#defineô EXT2_S_IFBLKô ô 0x6000ô /* block device */
#defineô EXT2_S_IFDIRô ô 0x4000ô /* directory */
#defineô EXT2_S_IFCHRô ô 0x2000ô /* character device */
#defineô EXT2_S_IFIFOô ô 0x1000ô /* fifo */
#defineô EXT2_S_ISUIDô ô 0x0800ô /* SUID */
#defineô EXT2_S_ISGIDô ô 0x0400ô /* SGID */
#defineô EXT2_S_ISVTXô ô 0x0200ô /* sticky bit */
#defineô EXT2_S_IRWXUô ô 0x01C0ô /* user access rights mask */
#defineô EXT2_S_IRUSRô ô 0x0100ô /* read */
#defineô EXT2_S_IWUSRô ô 0x0080ô /* write */
#defineô EXT2_S_IXUSRô ô 0x0040ô /* execute */
#defineô EXT2_S_IRWXGô ô 0x0038ô /* group access rights mask */
#defineô EXT2_S_IRGRPô ô 0x0020ô /* read */
#defineô EXT2_S_IWGRPô ô 0x0010ô /* write */
#defineô EXT2_S_IXGRPô ô 0x0008ô /* execute */
#defineô EXT2_S_IRWXOô ô 0x0007ô /* others access rights mask */
#defineô EXT2_S_IROTHô ô 0x0004ô /* read */
#defineô EXT2_S_IWOTHô ô 0x0002ô /* write */
#defineô EXT2_S_IXOTHô ô 0x0001ô /* execute */
struct disk *ext2_get_disk_info(int);
struct ext2_super_block *ext2_read_sb(int);
struct ext2_group_desc *ext2_read_gd(struct disk *);
struct ext2_inode *ext2_read_inode(struct disk *, int);
char *ext2_read_file(struct disk *, struct ext2_inode *);û partir des informations contenues dans le superbloc, on obtient des informations qui sont primordiales pour comprendre l'organisation globale du systû´me de fichiersô :
- la taille des blocsô : 1024 << s_log_block_sizeô ;
- la taille des inodesô : s_inode_sizeô ;
-
le nombre de groupes, il faut prendre le maximum deô :
- s_blocks_count / s_blocks_per_group + ((s_blocks_count % s_blocks_per_group)ô ? 1ô : 0),
- s_inodes_count / s_inodes_per_group + ((s_inodes_count % s_inodes_per_group)ô ? 1ô : 0).
La fonction ext2_read_sb() du fichier ext2.c lit le superbloc et calcule û partir de ces informations la taille des blocs et le nombre de groupes.
#include "ext2.h"
#include "disk.h"
#include "kmalloc.h"
#include "lib.h"
/*
ô * Initialise la structure dûˋcrivant le disque logique.
ô * Offset correspond au dûˋbut de la partition.
ô */
struct disk *ext2_get_disk_info(int device)
{
ô ô ô ô int i, j;
ô ô ô ô struct disk *hd;
ô ô ô ô hd = (struct disk *) kmalloc(sizeof(struct disk));
ô ô ô ô hd->device = device;
ô ô ô ô hd->sb = ext2_read_sb(device);
ô ô ô ô hd->blocksize = 1024 << hd->sb->s_log_block_size;
ô ô ô ô i = (hd->sb->s_blocks_count / hd->sb->s_blocks_per_group) +
ô ô ô ô ô ô ((hd->sb->s_blocks_count % hd->sb->s_blocks_per_group) ? 1 : 0);
ô ô ô ô j = (hd->sb->s_inodes_count / hd->sb->s_inodes_per_group) +
ô ô ô ô ô ô ((hd->sb->s_inodes_count % hd->sb->s_inodes_per_group) ? 1 : 0);
ô ô ô ô hd->groups = (i > j) ? i : j;
ô ô ô ô hd->gd = ext2_read_gd(hd);
ô ô ô ô return hd;
}
struct ext2_super_block *ext2_read_sb(int device)
{
ô ô ô ô struct ext2_super_block *sb;
ô ô ô ô sb = (struct ext2_super_block *) kmalloc(sizeof(struct ext2_super_block));
ô ô ô ô disk_read(device, 1024, (char *) sb, sizeof(struct ext2_super_block));
ô ô ô ô return sb;
}
struct ext2_group_desc *ext2_read_gd(struct disk *hd)
{
ô ô ô ô struct ext2_group_desc *gd;
ô ô ô ô int offset, gd_size;
ô ô ô ô /* localisation du bloc */
ô ô ô ô offset = (hd->blocksize == 1024) ? 2048 : hd->blocksize;
ô ô ô ô /* taille occupee par les descripteurs */
ô ô ô ô gd_size = hd->groups * sizeof(struct ext2_group_desc);
ô ô ô ô /* creation du tableau de descripteurs */
ô ô ô ô gd = (struct ext2_group_desc *) kmalloc(gd_size);
ô ô ô ô disk_read(hd->device, offset, (char *) gd, gd_size);
ô ô ô ô return gd;
}
/* Retourne la structure d'inode û partir de son numûˋro */
struct ext2_inode *ext2_read_inode(struct disk *hd, int i_num)
{
ô ô ô ô int gr_num, index, offset;
ô ô ô ô struct ext2_inode *inode;
ô ô ô ô inode = (struct ext2_inode *) kmalloc(sizeof(struct ext2_inode));
ô ô ô ô /* groupe qui contient l'inode */
ô ô ô ô gr_num = (i_num - 1) / hd->sb->s_inodes_per_group;
ô ô ô ô /* index de l'inode dans le groupe */
ô ô ô ô index = (i_num - 1) % hd->sb->s_inodes_per_group;
ô ô ô ô /* offset de l'inode sur le disk */
ô ô ô ô offset =
ô ô ô ô ô ô hd->gd[gr_num].bg_inode_table * hd->blocksize + index * hd->sb->s_inode_size;
ô ô ô ô /* lecture */
ô ô ô ô disk_read(hd->device, offset, (char *) inode, hd->sb->s_inode_size);
ô ô ô ô return inode;
}
char *ext2_read_file(struct disk *hd, struct ext2_inode *inode)
{
ô ô ô ô char *mmap_base, *mmap_head, *buf;
ô ô ô ô int *p, *pp, *ppp;
ô ô ô ô int i, j, k;
ô ô ô ô int n, size;
ô ô ô ô buf = (char *) kmalloc(hd->blocksize);
ô ô ô ô p = (int *) kmalloc(hd->blocksize);
ô ô ô ô pp = (int *) kmalloc(hd->blocksize);
ô ô ô ô ppp = (int *) kmalloc(hd->blocksize);
ô ô ô ô /* taille totale du fichier */
ô ô ô ô size = inode->i_size;
ô ô ô ô mmap_head = mmap_base = kmalloc(size);
ô ô ô ô /* direct block number */
ô ô ô ô for (i = 0; i < 12 && inode->i_block[i]; i++) {
ô ô ô ô ô ô ô ô disk_read(hd->device, inode->i_block[i] * hd->blocksize, buf, hd->blocksize);
ô ô ô ô ô ô ô ô n = ((size > hd->blocksize) ? hd->blocksize : size);
ô ô ô ô ô ô ô ô memcpy(mmap_head, buf, n);
ô ô ô ô ô ô ô ô mmap_head += n;
ô ô ô ô ô ô ô ô size -= n;
ô ô ô ô }
ô ô ô ô /* indirect block number */
ô ô ô ô if (inode->i_block[12]) {
ô ô ô ô ô ô ô ô disk_read(hd->device, inode->i_block[12] * hd->blocksize, (char *) p, hd->blocksize);
ô ô ô ô ô ô ô ô for (i = 0; i < hd->blocksize / 4 && p[i]; i++) {
ô ô ô ô ô ô ô ô ô ô ô ô disk_read(hd->device, p[i] * hd->blocksize, buf, hd->blocksize);
ô ô ô ô ô ô ô ô ô ô ô ô n = ((size > hd->blocksize) ? hd->blocksize : size);
ô ô ô ô ô ô ô ô ô ô ô ô memcpy(mmap_head, buf, n);
ô ô ô ô ô ô ô ô ô ô ô ô mmap_head += n;
ô ô ô ô ô ô ô ô ô ô ô ô size -= n;
ô ô ô ô ô ô ô ô }
ô ô ô ô }
ô ô ô ô /* bi-indirect block number */
ô ô ô ô if (inode->i_block[13]) {
ô ô ô ô ô ô ô ô disk_read(hd->device, inode->i_block[13] * hd->blocksize, (char *) p, hd->blocksize);
ô ô ô ô ô ô ô ô for (i = 0; i < hd->blocksize / 4 && p[i]; i++) {
ô ô ô ô ô ô ô ô ô ô ô ô disk_read(hd->device, p[i] * hd->blocksize, (char *) pp, hd->blocksize);
ô ô ô ô ô ô ô ô ô ô ô ô for (j = 0; j < hd->blocksize / 4 && pp[j]; j++) {
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô disk_read(hd->device, pp[j] * hd->blocksize, buf, hd->blocksize);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô n = ((size > hd->blocksize) ? hd-> blocksize : size);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô memcpy(mmap_head, buf, n);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô mmap_head += n;
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô size -= n;
ô ô ô ô ô ô ô ô ô ô ô ô }
ô ô ô ô ô ô ô ô }
ô ô ô ô }
ô ô ô ô /* tri-indirect block number */
ô ô ô ô if (inode->i_block[14]) {
ô ô ô ô ô ô ô ô disk_read(hd->device, inode->i_block[14] * hd->blocksize, (char *) p, hd->blocksize);
ô ô ô ô ô ô ô ô for (i = 0; i < hd->blocksize / 4 && p[i]; i++) {
ô ô ô ô ô ô ô ô ô ô ô ô disk_read(hd->device, p[i] * hd->blocksize, (char *) pp, hd->blocksize);
ô ô ô ô ô ô ô ô ô ô ô ô for (j = 0; j < hd->blocksize / 4 && pp[j]; j++) {
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô disk_read(hd->device, pp[j] * hd->blocksize, (char *) ppp, hd->blocksize);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô for (k = 0; k < hd->blocksize / 4 && ppp[k]; k++) {
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô disk_read(hd->device, ppp[k] * hd->blocksize, buf, hd->blocksize);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô n = ((size > hd->blocksize) ? hd->blocksize : size);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô memcpy(mmap_head, buf, n);
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô mmap_head += n;
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô size -= n;
ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô }
ô ô ô ô ô ô ô ô ô ô ô ô }
ô ô ô ô ô ô ô ô }
ô ô ô ô }
ô ô ô ô kfree(buf);
ô ô ô ô kfree(p);
ô ô ô ô kfree(pp);
ô ô ô ô kfree(ppp);
ô ô ô ô return mmap_base;
}XIX-B-2. Le bloc de descripteurs de groupes▲
Le disque est subdivisûˋ en groupes. L'organisation de chaque groupe est dûˋcrite par un descripteur qui fournit les informations suivantesô :
- le numûˋro de bloc oû¿ se situe le block bitmapô : bg_block_bitmapô ;
- le numûˋro de bloc oû¿ se situe le inode bitmapô : bg_inode_bitmapô ;
- le numûˋro de bloc oû¿ se situe la table d'inodesô : bg_inode_table.
Notez que les offsets ci-dessus sont exprimûˋs en numûˋro de bloc û partir du dûˋbut du disque. L'offset en octet se calcule en multipliant ce numûˋro de bloc par la taille de bloc.
La fonction ext2_read_gd() crûˋe un tableau contenant l'ensemble des descripteurs de groupes.
XIX-B-3. Localiser sur le disque une inode▲
Une inode contient les informations de base d'un fichier. Une inode est localisable sur le disque û partir des calculs suivantsô :
- localiser le groupe oû¿ se trouve l'inodeô : (i_num - 1) / s_inodes_per_groupô ;
- retrouver l'inode dans le groupe en calculant son index dans la table d'inodesô : (i_num - 1) % s_inodes_per_group.
La fonction ext2_read_inode() retrouve et renvoie une structure d'inode û partir de son numûˋro passûˋ en argument.
XIX-B-4. Lire un fichier▲
La fonction ext2_read_file() renvoie un buffer avec le contenu du fichier correspondant û l'inode passûˋe en argument.
XIX-C. Crûˋer et utiliser une image d'un disque dur sous Unix avec un systû´me de fichier Ext2FS▲
Les commandes shell dûˋcrites ci-dessous doivent ûˆtre parfaitement comprises avant d'ûˆtre exûˋcutûˋes sur un systû´me UNIXô ! Si une commande ou un concept ne vous semble pas clair, je vous conseille de lire la documentation accessible sur l'excellent Guide du Rootard. Mûˆme si cet effort vous semble futile et n'a en apparence pas de rapport avec le dûˋveloppement d'un noyau, je vous garantis que les connaissances acquises vous seront trû´s utilesô !
Il faut d'abord crûˋer une image d'un disque dur avec la commande bximageô :
bximage
> hd
> flat
> 2
> c.imgPour crûˋer un systû´me de fichiersô :
mke2fs c.imgPour voir les caractûˋristiques du systû´meô :
dumpe2fs c.imgPour monter le systû´me de fichiersô :
mount -o loop -t ext2 c.img /mnt/loopActuellement les systû´mes Ext3, et Ext4 sont plutûÇt utilisûˋs. Ext3 est complû´tement rûˋtrocompatible avec Ext2, il y ajoute la journalisation. Une partition ext3 peut ûˆtre montûˋe en Ext3. Une partition Ext4 peut ûˆtre montûˋe en Ext3 si l'allocation par Extent n'a jamais ûˋtûˋ utilisûˋe.
XX. Crûˋer et lancer une application au format ELF û partir du systû´me de fichiers▲
- RemarquesRemarques
- Anatomie d'un fichier ELFAnatomie d'un fichier ELF
- Charger un exûˋcutableCharger un exûˋcutable
- Un nouvel appel systû´meô : exit()Un nouvel appel systû´meô : exit()
- Crûˋer et lancer une application au format ELF û partir du systû´me de fichiersCrûˋer et lancer une application au format ELF û partir du systû´me de fichiers
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_ELF.tgz
XX-A. Remarques▲
Dans ce chapitre, nous allons voir comment crûˋer et charger un fichier exûˋcutable au format ELF pour Pûˋpin. Notez que pour le momentô :
- les fichiers seront chargûˋs û partir de leur numûˋro d'inodeô ;
- seuls les fichiers compilûˋs en statique seront supportûˋsô ;
- il y a une disquette avec le noyau d'une part et un disque avec des fichiers d'autre part. Patienceô ! Nous verrons au chapitre suivant comment booter un noyau avec Grub directement depuis un disque IDE.
XX-B. Anatomie d'un fichier ELF▲
Un fichier au format ELF est formûˋ notamment parô :
- un premier en-tûˆte qui dûˋcrit le type de fichier dont il est question et qui dûˋfinit l'organisation globale au sein de ce fichierô ;
- une table spûˋciale, la Program Header Table, qui dûˋcrit et localise les diffûˋrents segments de code û charger par le noyau.
Le schûˋma ci-dessous est une illustration d'un fichier ELF comportant deux segments de codeô :
|
|
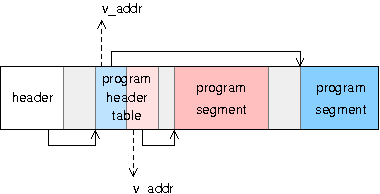
L'en-tûˆte d'un fichier ELF est dûˋfini dans le fichier elf.h par la structure Elf32_Ehdr.
typedef struct {
ô ô ô ô unsigned char e_ident[16]; ô ô ô /* ELF identification */
ô ô ô ô u16 e_type; ô ô ô ô ô ô /* 2 (exec file) */
ô ô ô ô u16 e_machine; ô ô ô ô ô /* 3 (intel architecture) */
ô ô ô ô u32 e_version; ô ô ô ô ô /* 1 */
ô ô ô ô u32 e_entry; ô ô ô ô ô ô /* starting point */
ô ô ô ô u32 e_phoff; ô ô ô ô ô ô /* program header table offset */
ô ô ô ô u32 e_shoff; ô ô ô ô ô ô /* section header table offset */
ô ô ô ô u32 e_flags; ô ô ô ô ô ô /* various flags */
ô ô ô ô u16 e_ehsize; ô ô ô ô ô /* ELF header (this) size */
ô ô ô ô u16 e_phentsize; ô ô ô ô /* program header table entry size */
ô ô ô ô u16 e_phnum; ô ô ô ô ô ô /* number of entries */
ô ô ô ô u16 e_shentsize; ô ô ô ô /* section header table entry size */
ô ô ô ô u16 e_shnum; ô ô ô ô ô ô /* number of entries */
ô ô ô ô u16 e_shstrndx; ô ô ô ô /* index of the section name string table */
} Elf32_Ehdr;- La variable e_ident[] sert û identifier le type de fichier et doit commencer par les caractû´resô : 0x7f, 'E', 'L', 'F'.
- La variable e_entry dûˋfinit le point d'entrûˋe du programme et dans notre cas correspond û l'adresse virtuelle 0x40000000 (USER_OFFSET).
- La variable e_phoff indique oû¿ se situe la Program Header Table dûˋcrivant les segments de code.
- La variable e_phnum indique le nombre d'entrûˋes dans cette table.
Les autres variables ne sont pas importantes pour le moment.
Chaque entrûˋe de la Program Header Table est une structure qui donne les caractûˋristiques d'un segment dans le fichier et oû¿ le charger en mûˋmoire. La structure correspondant û chacune de ces entrûˋes est la suivanteô : Elf32_Phdr.
ypedef struct {
ô ô ô ô u32 p_type; ô ô ô ô ô ô /* type of segment */
ô ô ô ô u32 p_offset;
ô ô ô ô u32 p_vaddr;
ô ô ô ô u32 p_paddr;
ô ô ô ô u32 p_filesz;
ô ô ô ô u32 p_memsz;
ô ô ô ô u32 p_flags;
ô ô ô ô u32 p_align;
} Elf32_Phdr;- p_offset est l'offset oû¿ se situe le segment par rapport au dûˋbut du fichier.
- p_filesz correspond û sa taille.
- p_vaddr est l'adresse virtuelle oû¿ il doit ûˆtre chargûˋ par le noyau.
- p_memsz correspond û sa taille en mûˋmoire. Notez qu'il est tout û fait possible que la valeur de p_memsz soit supûˋrieure û celle de p_filesz. Dans ce cas, le noyau doit simplement rûˋserver l'espace suffisant et l'initialiser û 0.
Cette description d'un fichier ELF est trû´s sommaire, car ce format est complexe et je n'ai voulu indiquer que ce qui est indispensable pour notre noyau. Pour en savoir plus, je vous conseille de parcourir la documentation.
XX-C. Charger un exûˋcutable▲
L'algorithme utilisûˋ par la fonction load_elf() pour charger un exûˋcutable au format ELF est trû´s simpleô :
Algorithme : load_elf
Paramû´tres : buffer contenant le fichier, adresse du rûˋpertoire de pages
Dûˋbut
Pour chaque entrûˋe dans la table des segments
Si le segment est de type PT_LOAD alors
On charge le segment :
/* p_vaddr et p_memsz permettent de savoir oû¿ le segment sera logûˋ en mûˋmoire */
On contrûÇle que p_vaddr et p_vaddr + p_memsz sont valides
Les pages nûˋcessaires sont rûˋservûˋes en mûˋmoire physique
Le rûˋpertoire de pages du processus courant est mis û jour
Le segment est recopiûˋ û l'endroit dûˋfini par p_vaddr
Si p_memsz > p_filesz alors
Les octets en plus sont mis û 0
FinEn pratique, le fichier kernel.c contient le code permettant de charger un fichier exûˋcutable. Pour le moment, on ne peut charger un exûˋcutable que par son numûˋro d'inode. Celle-ci est chargûˋe via la fonction ext2_read_inode(). Ensuite, la fonction load_task() charge l'exûˋcutableô :
inode = ext2_read_inode(hd, gd, 14);
load_task(hd, inode);Ensuite, la fonction load_task() fait appel û la fonction load_elf()ô :
file = ext2_read_file(hd, inode);
load_elf(file, pd, mmap);XX-D. Un nouvel appel systû´meô : exit()▲
Jusqu'û prûˋsent, notre noyau disposait d'un appel systû´me permettant û une application d'afficher un message sur la console. Cette partie prûˋsente un nouvel appel systû´me permettant û une tûÂche utilisateur de se terminer proprement. Cet appel est implûˋmentûˋ dans le fichier syscalls.c . L'algorithme est trû´s simpleô :
Algorithme : sys_exit()
Synopsis : termine le processus courant
Dûˋbut
Dûˋsactive les interruptions
Dûˋcrûˋmente le nombre de processus
Libû´re l'entrûˋe dans la table des processus : current->state = 0
Libû´re les pages mûˋmoires occupûˋes par le code (current->mmap)
Libû´re la pile utilisateur (get_p_addr((char *) USER_STACK))
Libû´re la pile noyau (current->kstack)
Libû´re le rûˋpertoire et les tables de pages (current->pd)
Choix d'une nouvelle tûÂche (ici la "tûÂche" noyau)
Bascule sur la nouvelle tûÂche : switch_to_task()
FinPour utiliser ce nouvel appel systû´me, l'application devra simplement insûˋrer l'instruction suivanteô :
asm("mov $0x02, ?x; int $0x30");XX-E. Crûˋer et lancer une application au format ELF û partir du systû´me de fichiers▲
Pour compiler une application au format ELF fonctionnant sous Pûˋpinô :
gcc -c task1.c
ld -Ttext=40000000 --entry=main task1.o|
|
XXI. Booter avec Grub sur un disque IDE▲
- Crûˋer une image d'un disque IDE partitionnûˋCrûˋer une image d'un disque IDE partitionnûˋ
- Utiliser un disque logiqueUtiliser un disque logique
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_Grub2.tgz
XXI-A. Crûˋer une image d'un disque IDE partitionnûˋ▲
Le fait de booter sur un disque IDE apporte un changement fondamental par rapport au boot sur une disquetteô : il faut partitionner le disque. Cela apporte une petite complexitûˋ supplûˋmentaire dont le contournement est expliquûˋ ci-dessousãÎ
On commence par crûˋer une image avec bximageô :
bximage
> hd
> flat
> 2
> c.imgCela a pour effet de crûˋer un fichier nommûˋ ici c.img et affiche le message suivant û l'ûˋcranô :
The following line should appear in your bochsrc:
ata0-master: type=disk, path="c.img", mode=flat, cylinders=4, heads=16, spt=63Cette ligne est û reporter dans le fichier .bochsrc. N'oubliez pas aussi de prûˋciser le pûˋriphûˋrique de bootô :
boot: diskIl faut ensuite partitionner l'image du disque. Les commandes c, h et s indiquent quelle est la gûˋomûˋtrie du disqueô :
fdisk c.img
> x
> c 4
> h 16
> s 63
> r
> n, p, 1
> a 1
> wAprû´s ûÏa, il faut obtenir le numûˋro de secteur de la partition crûˋûˋeô :
fdisk -l -u c.img
Disk c.img: 0 MB, 0 bytes
16 heads, 63 sectors/track, 0 cylinders, total 0 sectors
Units = sectors of 1 * 512 = 512 bytes
Disk identifier: 0x7337b4ff
Device Boot Start End Blocks Id System
c.img1 * 63 4031 1984+ 83 LinuxNous allons maintenant associer la partition crûˋûˋe û un loop device, qui est un pseudo pûˋriphûˋrique qui permet û un fichier d'ûˆtre accûˋdûˋ comme s'il s'agissait d'un pûˋriphûˋrique de type bloc. On utilise pour cela la commande losetup avec comme argument l'offset, en octet, oû¿ se trouve le dûˋbut de la partition (c'est la raison de la commande prûˋcûˋdente). L'offset calculûˋ est de 63 * 512 = 32356ô :
losetup -o 32256 /dev/loop0 c.imgPour dûˋtacher le loop device de l'imageô :
losetup -d /dev/loop0û partir de maintenant, la partition de l'image disque est vue comme un vrai pûˋriphûˋrique de type bloc. On peut donc dûˋposer un systû´me de fichiers dessusô :
mke2fs /dev/loop0Ensuite, pour monter la partitionô :
mount -t ext2 /dev/loop0 /mnt/loopXXI-A-1. Installer grub sur une image bootable▲
On ajoute quelques fichiers sur la partition montûˋeô :
mkdir /mnt/loop/grub
cp /boot/grub/stage* /mnt/loop/grub
cat > /mnt/loop/grub/menu.lst << EOF
title=Pepin
root (hd0,0)
kernel /kernel
boot
EOFEnsuite, il faut dûˋmonter la partition pour installer grub dessusô :
umount /mnt/loop
grub --device-map=/dev/null << EOF
device (hd0) c.img
root (hd0,0)
setup (hd0)
quit
EOFOufô ! C'est fait, maintenant, on peut remonter la partition quelque part pour copier le noyau dessus.
XXI-B. Utiliser un disque logique▲
La table des partitions primaires du MBR permet de gûˋrer jusqu'û 4 partitions. Les informations sur ces partitions sont situûˋes û des offsets prûˋdûˋfinis par rapport au dûˋbut du disqueô :
|
Partition |
Offset |
|---|---|
|
Partition 1 |
0x01BE |
|
Partition 2 |
0x01CE |
|
Partition 3 |
0x01DE |
|
Partition 4 |
0x01EE |
Chaque entrûˋe de la table fait 16 octets et obûˋit au format suivantô :
struct partition {
ô ô ô ô u8 ô ô ô bootable; ô ô ô /* 0 = no, 0x80 = bootable */
ô ô ô ô u8 ô ô ô s_head; ô ô ô ô /* Starting head */
ô ô ô ô u16 ô ô s_sector : 6; ô /* Starting sector */
ô ô ô ô u16 ô ô s_cyl ô ô : 10; ô /* Starting cylinder */
ô ô ô ô u8 ô ô ô id; ô ô ô ô ô ô /* System ID */
ô ô ô ô u8 ô ô ô e_head; ô ô ô ô /* Ending head */
ô ô ô ô u16 ô ô e_sector : 6; ô /* Ending sector */
ô ô ô ô u16 ô ô e_cyl ô ô : 10; ô /* Ending cylinder */
ô ô ô ô u32 ô ô s_lba; ô ô ô ô ô /* Starting sector (LBA value) */
ô ô ô ô u32 ô ô size; ô ô ô ô ô /* Total sector number */
} __attribute__ ((packed));Sur les systû´mes rûˋcents, utilisant UEFI, la table de partition MBR est remplacûˋe par la table GPT. Il y a une forme de rûˋtrocompatibilitûˋ, une table GPT contenant une ô¨ô Protective MBRô ô£
La valeur s_lba permet de connaûÛtre l'offset oû¿ commence une partition par rapport au dûˋbut du disque. En l'occurrence, les donnûˋes dûˋbuteront û partir de l'offset s_lba*512 (en octets).
Nous avons vu au chapitre sur l'utilisation d'un systû´me de fichiers Ext2Utiliser un systû´me de fichiers Ext2FS comment lire des donnûˋes telles que le superbloc, une inode, etc. Quelques changements sont û apporter pour que ces fonctions continuent de fonctionner, car les lectures ne se font plus û partir du dûˋbut du disque, mais û partir du dûˋbut de la partition. Chaque donnûˋe subit donc un dûˋcalage de s_lba*512 octetsô :
struct partition *p1;
struct ext2_super_block *sb;
p1 = (struct partition*) kmalloc(sizeof(struct partition));
disk_read(0, 0x01BE, (char*) p1, 16);
printk("partition 1\n ô start: %d, size: %d\n", p1->s_lba, p1->size);
sb = (struct ext2_super_block*) kmalloc(sizeof(struct ext2_super_block));
disk_read(0, (p1.s_lba * 512) + 1024, (char*) sb, sizeof(struct ext2_super_block));
printk("volume name: %s, block size: %d\n", sb->s_volume_name, (1024 << sb->s_log_block_size));XXII. Quelques structures ûˋlûˋmentaires pour gûˋrer les fichiers ▲
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_File.tgz
XXII-A. Organiser les fichiers▲
Jusqu'û prûˋsent, nous avons vu comment implûˋmenter au sein d'un noyau les fonctionnalitûˋs permettant de lire un fichier dans un systû´me de fichiers de type Ext2FS û partir de son numûˋro d'inode. Cette partie prûˋsente les structures et les fonctions implûˋmentûˋes dans le noyau Pûˋpin afin de pouvoir accûˋder aux fichiers directement par leur nom.
XXII-A-1. Le disque logique▲
Les donnûˋes gûˋnûˋrales relatives û la structure du disque logique et du systû´me de fichiers sont collectûˋes dans la structure struct diskô :
|
|
XXII-A-2. Structure d'un fichier et arborescence▲
Les fichiers sont organisûˋs sous forme d'arborescence. C'est une donnûˋe trû´s gûˋnûˋrale que je ne dûˋtaillerai pas ici. Afin d'ûˋconomiser les accû´s disques, le noyau cache en mûˋmoire une partie de cette arborescence. Chaque néud de cette arborescence est dûˋcrit par la structure struct fileô :
|
|
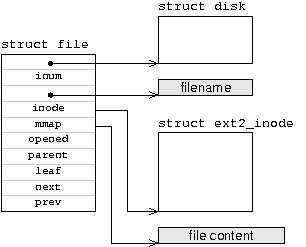
Les champs leaf, parent, next et prev permettent de lier les structures de fichiers entre elles afin de reproduire dans le cache cette arborescenceô :
|
|
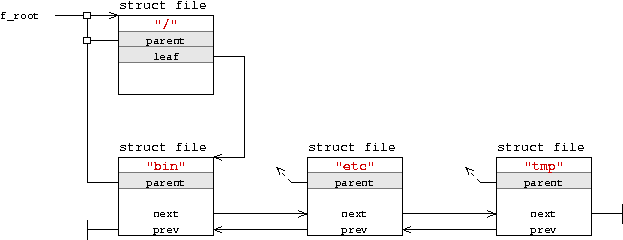
La fonction get_dir_entries() recherche pour un rûˋpertoire donnûˋ l'ensemble de ses entrûˋes (fichiers et sous-rûˋpertoires) et met û jour le cache de l'arborescence en consûˋquence.
La fonction is_cached_leaf() regarde dans le cache et indique si un fichier est une ô¨ô feuilleô ô£ d'un rûˋpertoire. Cette fonction se base uniquement sur le cache. Pour savoir si un fichier est bien une entrûˋe d'un rûˋpertoire, il faut donc au prûˋalable avoir mis û jour le cacheô :
get_dir_entries(dir);
if (!is_cached_leaf(dir, filename))
ô ô return (struct file *) 0;La fonction path_to_file() renvoie la structure de fichier associûˋe û un chemin.
XXII-B. De nouveaux appels systû´me▲
XXII-B-1. Structure d'un processusô : gûˋrer les fichiers▲
Un processus peut ûˆtre amenûˋ û ouvrir des fichiers, comme c'est par exemple le cas de la commande cat sous Unix.
La structure struct process, qui dûˋcrit le contexte d'exûˋcution d'un processus, est modifiûˋe de faûÏon û pouvoir indiquerô :
- le rûˋpertoire courant, par le biais du champ pwdô ;
- la liste des fichiers ouverts, par le biais d'une liste chaûÛnûˋe de descripteurs de fichiers
|
|
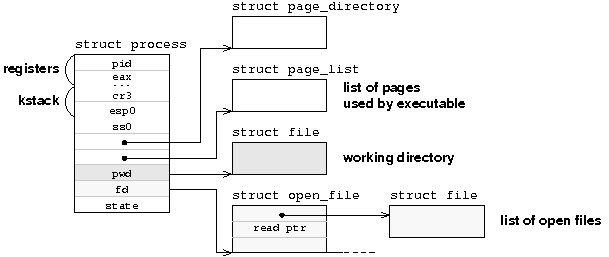
Le schûˋma ci-dessous dûˋtaille la structure struct open_fileô :
- le champ file pointe sur le fichier ouvertô ;
- le champ ptr pointe sur la position courante dans le fichier. C'est un indicateur qui permet de savoir oû¿ en est la lecture de ce fichier par le processusô ;
- le champ next permet de chaûÛner les structures dans le cas oû¿ plusieurs fichiers sont ouverts.
|
|

L'ouverture, la lecture et la fermeture de fichiers sont rûˋalisûˋes par trois nouveaux appels systû´meô : sys_open(), sys_read() et sys_close(). Attention, contrairement û un systû´me Unix oû¿ tout est fichier, l'ouverture de flux d'entrûˋe, sortie, etc. n'est pas encore possible avec Pûˋpin. Les appels systû´me prûˋsentûˋs ici ne concernent donc que de vûˋritables fichiers.
XXIII. Une mûˋthode gûˋnûˋrique pour gûˋrer les listes chaûÛnûˋes▲
- Des listes de donnûˋesDes listes de donnûˋes
- Les listes chaûÛnûˋes sous FreeBSDLes listes chaûÛnûˋes sous FreeBSD
- Les listes chaûÛnûˋes sous LinuxLes listes chaûÛnûˋes sous Linux
- Les listes chaûÛnûˋes sous PûˋpinLes listes chaûÛnûˋes sous Pûˋpin
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_LinkedList.tgz
XXIII-A. Des listes de donnûˋes▲
En langage C, l'organisation de donnûˋes sous forme de liste peut ûˆtre implûˋmentûˋe en utilisant un tableau ou une liste chaûÛnûˋe. L'utilisation de listes chaûÛnûˋes est trû´s pratique, car contrairement aux tableaux, les listes chaûÛnûˋes sont facilement extensibles et le retrait d'ûˋlûˋments se fait sans perte de mûˋmoire. Les listes chaûÛnûˋes sont donc trû´s utilisûˋes par les noyaux et c'est aussi le cas de Pûˋpin. Par exemple, nous avons dûˋfini dans le fichier mm.h une structure de donnûˋes pour dûˋcrire une page mûˋmoire. Cette structure contient deux attributs. Le champ v_addr correspond û l'adresse en mûˋmoire virtuelle et le champ p_addr correspond û l'adresse en mûˋmoire physiqueô :
struct page {
ô ô ô ô char *v_addr;
ô ô ô ô char *p_addr;
};Pour avoir une liste de pages, nous utilisons la structure struct page_list ci-dessousô :
struct page_list {
ô ô ô ô struct page *page;
ô ô ô ô struct page_list *next;
ô ô ô ô struct page_list *prev;
};Ce type de liste est utilisûˋ notamment par la struct page_directory, qui dûˋcrit un rûˋpertoire de pages et indique oû¿ sont les diffûˋrentes tables de pagesô :
|
|
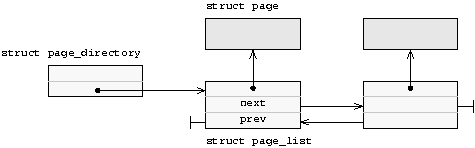
Cette mûˋthode pour implûˋmenter des listes chaûÛnûˋes prûˋsente deux inconvûˋnientsô :
- le premier est que pour chaque type de donnûˋes û chaûÛner, il faut crûˋer un type particulier pour organiser la liste. Par exemple, pour faire une liste de processus, il faut crûˋer un nouveau type struct process_list. Si nous voulons ensuite faire des listes de fichiers, alors il faut aussi un nouveau type et il en sera ainsi pour chaque type d'objet susceptible d'ûˆtre organisûˋ par listeô ;
- pour ajouter, insûˋrer, enlever, dûˋplacer ou rechercher un ûˋlûˋment dans une liste, il est pratique de disposer de fonctions gûˋnûˋriques pour ne pas avoir û rûˋûˋcrire û chaque fois les mûˆmes portions de code. Or, si nous utilisons û chaque fois des types particuliers pour effectuer le chaûÛnage, nous sommes obligûˋs d'utiliser û chaque fois des fonctions particuliû´res.
Heureusement, les noyaux Linux et FreeBSD proposent chacun une mûˋthode pour implûˋmenter de faûÏon gûˋnûˋrique les listes chaûÛnûˋes. C'est ce que je vais essayer de prûˋsenter ci-dessous.
XXIII-B. Les listes chaûÛnûˋes sous FreeBSD▲
Les systû´mes d'exploitation de la famille BSD utilisent une implûˋmentation gûˋnûˋrique des listes chaûÛnûˋes situûˋe dans le fichier sys/queue.h. Cette implûˋmentation, qui propose quatre types de listes, est dûˋcrite de faûÏon dûˋtaillûˋe sur https://www.freebsd.org/cgi/man.cgi?query=queue&sektion=3. Bien que la famille *BSD propose quatre types diffûˋrents de listes, celles-ci partagent des caractûˋristiques communesô :
- la structure permettant le chaûÛnage est intûˋgrûˋe û la structure des objets û chaûÛnerô ;
- le programmeur dûˋcide du nom et du type de la structure permettant le chaûÛnageô ;
- chaque liste est pointûˋe par une ô¨ô tûˆte de listeô ô£ô ;
- la dûˋfinition et la manipulation des listes reposent uniquement sur un jeu de macro (cf. #define).
XXIII-B-1. Le type SLIST▲
Le premier type de liste, le type SLIST, est une interface permettant de crûˋer des listes simplement chaûÛnûˋes. Supposons que l'on veuille avoir une liste de struct somethingô :
- une structure anonyme permettant le chaûÛnage est intûˋgrûˋe au sein de la structureô ;
- une tûˆte de liste de type struct name pointe sur le premier ûˋlûˋment.
|
|
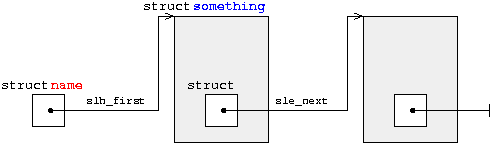
L'utilisation des macros pour gûˋrer la liste est assez intuitive. Par exempleô :
#include <stdio.h>
#include <stdlib.h>
#include "queue.h"
struct page {
ô ô char *v_addr;
ô ô char *p_addr;
ô ô SLIST_ENTRY(page) plist;
};
void main(void)
{
ô ô ô struct page *p1, *p2, *pp;
ô ô ô SLIST_HEAD(my_pglist, page) pglist; ô ô ô ô ô ô /* Declare the list. */
ô ô ô SLIST_INIT(&pglist); ô ô ô ô ô ô ô ô ô ô ô ô ô /* Initialize the list. */
ô ô ô p1 = malloc(sizeof(struct page));
ô ô ô p1->v_addr = (char*) 0x1234;
ô ô ô p1->p_addr = (char*) 0xffff1234;
ô ô ô SLIST_INSERT_HEAD(&pglist, p1, plist); ô ô ô ô /* Insert at the head. */
ô ô ô p2 = malloc(sizeof(struct page)); ô
ô ô ô p2->v_addr = (char*) 0x5678;
ô ô ô p2->p_addr = (char*) 0xffff5678;
ô ô ô SLIST_INSERT_AFTER(p1, p2, plist); ô ô ô ô ô ô /* Insert after. */
ô ô ô pp = SLIST_FIRST(&pglist); ô ô ô ô ô ô ô ô ô ô /* Get the first item */
ô ô ô SLIST_FOREACH(pp, &pglist, plist) ô ô ô ô ô ô ô /* Forward traversal. */
ô ô ô ô ô ô ô printf("%p -> %p\n", pp->v_addr, pp->p_addr);
ô ô ô SLIST_REMOVE(&pglist, p2, page, plist); /* Deletion. */
ô ô ô free(p2);
}XXIII-B-2. Le type STAILQ▲
Le type STAILQ, est similaire au type prûˋcûˋdent avec en plus un pointeur vers la fin de la liste, ce qui permet d'y ajouter un ûˋlûˋment sans avoir û traverser toute la listeô :
|
|
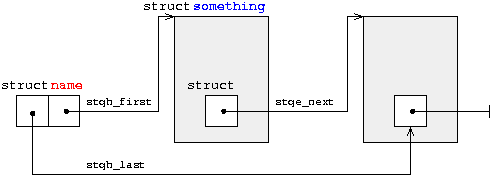
XXIII-B-3. Le type LIST▲
Le type LIST est doublement chaûÛnûˋ de faûÏon û ce queô :
- un ûˋlûˋment puisse ûˆtre enlevûˋ sans avoir û traverser toute la listeô ;
- un ûˋlûˋment puisse ûˆtre insûˋrûˋ avant ou aprû´s n'importe quel autre ûˋlûˋment sans avoir û traverser toute la listeô ;
- la liste puisse ûˆtre parcourue dans les deux sens.
|
|
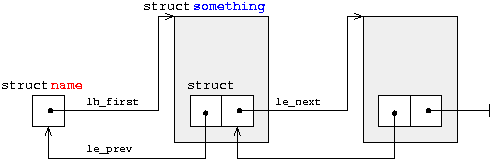
XXIII-B-4. Le type TAILQ▲
Le type TAILQ est similaire au type prûˋcûˋdent avec en plus un pointeur vers la fin de la liste, ce qui permet d'y ajouter un ûˋlûˋment sans avoir û traverser toute la listeô :
|
|
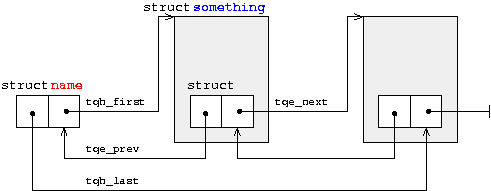
XXIII-C. Les listes chaûÛnûˋes sous Linux▲
Linux propose une implûˋmentation trû´s originale de liste circulaire doublement chaûÛnûˋe et dont les sources sont dans le fichier include/linux/list.h. Cette implûˋmentation a certaines caractûˋristiquesô :
- la structure permettant le chaûÛnage est intûˋgrûˋe û la structure des objets û chaûÛner (c'est d'ailleurs le seul point commun avec les listes de type *BSD)ô ;
- la tûˆte de liste fait partie intûˋgrante de la listeô !
- la structure permettant le chaûÛnage est du type dûˋfini struct list_headô ;
- la dûˋfinition et la manipulation des listes reposent essentiellement sur un jeu de fonctions inline
|
|
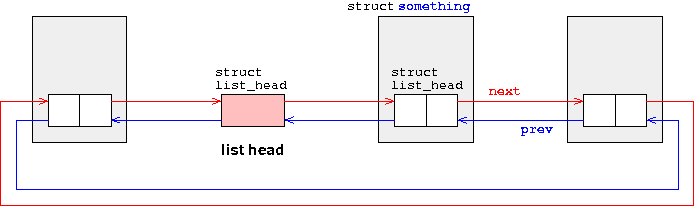
Ce schûˋma fait apparaûÛtre une autre diffûˋrence fondamentale entre l'implûˋmentation de type *BSD et l'implûˋmentation Linux. Dans l'implûˋmentation *BSD, chaque structure de liste pointe sur l'objet suivant. Alors que dans l'implûˋmentation Linux, chaque structure de liste pointe sur la structure de liste suivante. Dans l'implûˋmentation Linux, nous avons donc une liste chaûÛnûˋe de structures de type list_head. Mais ce que nous voulons manipuler finalement, ce sont bien les objets eux-mûˆmesô : comment retrouver l'adresse d'un objet û partir du pointeur vers sa structure de listeô ?
La fonction list_entry() fait ce travailô :
#define list_entry(ptr, type, member) \
ô ô ô ô (type*) ((char*) ptr - (char*) &((type*)0)->member)Son implûˋmentation repose sur une astuce expliquûˋe dans les FAQ du langage C (question 2.14). Le schûˋma ci-dessous met en ûˋvidence la formule permettant de calculer l'offset entre l'adresse du dûˋbut de la structure et l'adresse d'un membre en son seinô :
|
|
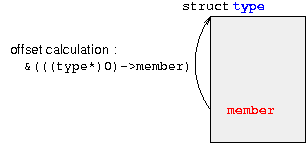
L'utilisation des fonctions pour gûˋrer ce type de liste est ensuite assez intuitive. Par exempleô :
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
struct page {
ô ô char *v_addr;
ô ô char *p_addr;
ô ô struct list_head plist;
};
void main(void)
{
ô ô ô struct page *p1, *p2, *pp;
ô ô ô struct list_head pglist, *l;
ô ô ô INIT_LIST_HEAD(&pglist); ô ô ô ô ô ô ô ô ô ô ô /* Initialize the list. */
ô ô ô p1 = malloc(sizeof(struct page));
ô ô ô p1->v_addr = (char*) 0x1234;
ô ô ô p1->p_addr = (char*) 0xffff1234;
ô ô ô list_add(&p1->plist, &pglist); ô ô ô ô ô ô ô ô /* Insert after the head. */
ô ô ô p2 = malloc(sizeof(struct page)); ô
ô ô ô p2->v_addr = (char*) 0x5678;
ô ô ô p2->p_addr = (char*) 0xffff5678;
ô ô ô list_add(&p2->plist, &p1->plist); ô ô ô ô ô ô ô /* Insert after */
ô ô ô pp = list_first_entry(&pglist, struct page, plist); /* Get the first item */
ô ô ô list_for_each(l, &pglist) { ô ô ô ô ô ô ô ô ô ô /* Forward traversal. */
ô ô ô ô ô pp = list_entry(l, struct page, plist);
ô ô ô ô ô printf("%p -> %p\n", pp->v_addr, pp->p_addr);
ô ô ô }
ô ô ô list_for_each_entry(pp, &pglist, plist) ô ô ô ô /* Forward traversal again ! */
ô ô ô ô ô printf("%p -> %p\n", pp->v_addr, pp->p_addr);
}XXIII-D. Les listes chaûÛnûˋes sous Pûˋpin▲
Le noyau Pûˋpin utilise la mûˆme implûˋmentation de listes que pour le noyau Linux. Le code a ûˋtûˋ lûˋgû´rement simplifiûˋ pour ûˆtre rendu plus accessible et le nombre de fonctions de manipulation de listes est moindre, mais fonctionnellement, les deux implûˋmentations sont identiquesô : list.h
#ifndef __LIST__
#define __LIST__
struct list_head {
ô ô ô ô struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
ô ô ô ô struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
ô ô ô ô list->next = list;
ô ô ô ô list->prev = list;
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
ô ô ô ô new->next = head->next;
ô ô ô ô new->prev = head;
ô ô ô ô head->next->prev = new;
ô ô ô ô head->next = new;
}
static inline void list_del(struct list_head *p)
{
ô ô ô ô p->next->prev = p->prev;
ô ô ô ô p->prev->next = p->next;
ô ô ô ô p->next = 0;
ô ô ô ô p->prev = 0;
}
static inline int list_empty(const struct list_head *head)
{
ô ô ô ô return head->next == head;
}
#define list_entry(ptr, type, member) \
ô ô ô ô (type*) ((char*) ptr - (char*) &((type*)0)->member)
#define list_first_entry(head, type, member) \
ô ô ô ô list_entry((head)->next, type, member)
#define list_for_each(p, head) \
ô ô ô ô for (p = (head)->next; p != (head); p = p->next)
#define list_for_each_safe(p, n, head) \
ô ô ô ô for (p = (head)->next, n = p->next; p != (head); p = n, n = n->next)
#define list_for_each_entry(p, head, member)ô ô ô ô ô ô ô ô ô ô ô ô ô ô \
ô ô ô ô for (p = list_entry((head)->next, typeof(*p), member);ô ô ô ô ô \
ô ô ô ô ô ô ô &p->member != (head);ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô ô \
ô ô ô ô ô ô ô p = list_entry(p->member.next, typeof(*p), member))ô ô ô ô \
#endifô /* __LIST__ */Le code du noyau a ûˋtûˋ entiû´rement rûˋûˋcrit en prenant en considûˋration cette nouvelle implûˋmentation. Mûˆme si cela a demandûˋ un certain travail, de grandes portions de code ont pu ûˆtre simplifiûˋes. Par exemple, dans la fonction load_elf(), le code suivantô :
if (get_p_addr((char *) v_addr) == 0) {
ô ô ô ô if (pglist->page) {
ô ô ô ô ô ô ô ô pglist->next = (struct page_list *) kmalloc(sizeof (struct page_list));
ô ô ô ô ô ô ô ô pglist->next->next = 0;
ô ô ô ô ô ô ô ô pglist->next->prev = pglist;
ô ô ô ô ô ô ô ô pglist = pglist->next;
ô ô ô ô }
ô ô ô ô pglist->page = (struct page *) kmalloc(sizeof(struct page));
ô ô ô ô pglist->page->p_addr = get_page_frame();
ô ô ô ô pglist->page->v_addr = (char *) (v_addr & 0xFFFFF000);
ô ô ô ô pd_add_page(pglist->page->v_addr, pglist->page->p_addr, PG_USER, pd);
}a ûˋtûˋ remplacûˋ par le code ci-dessous, plus court et donc un peu plus lisibleô :
if (get_p_addr((char *) v_addr) == 0) {
ô ô ô ô pg = (struct page *) kmalloc(sizeof(struct page));
ô ô ô ô pg->p_addr = get_page_frame();
ô ô ô ô pg->v_addr = (char *) (v_addr & 0xFFFFF000);
ô ô ô ô list_add(&pg->list, pglist);
ô ô ô ô pd_add_page(pg->v_addr, pg->p_addr, PG_USER, pd);
}XXIV. Un premier shell▲
- Un processus qui utilise la consoleUn processus qui utilise la console
- Crûˋer un nouveau processusCrûˋer un nouveau processus
- Allouer dynamiquement de la mûˋmoire û un processus avec malloc()Allouer dynamiquement de la mûˋmoire û un processus avec malloc()
- Le noyau et un premier shellLe noyau et un premier shell
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_Shell.tgz
XXIV-A. Un processus qui utilise la console▲
Nous avons vu dans un chapitre prûˋcûˋdent comment gûˋrer les interruptions du clavier pour saisir des caractû´res et afficher un message directement sur la console. La rûˋalisation d'un shell demande d'aller un peu plus loin dans le traitement de ces interruptions pour que les caractû´res saisis soient effectivement ô¨ô lusô ô£ par le shell. Cette partie montre une implûˋmentation simple permettant û de multiples processus d'utiliser une console pour saisir et afficher des caractû´res.
XXIV-A-1. Attacher une console û un processus pour gûˋrer les entrûˋes/sorties d'un terminal▲
Au dûˋmarrage, le noyau initialise une console par dûˋfaut grûÂce û la structure struct terminal. Cette structure contient deux champs, pread et pwrite, qui pointent vers les processus qui utilisent la console en lecture ou en ûˋcriture. Dans cette architecture, un seul processus peut donc lire ou ûˋcrire û la fois.
Le pointeur current_term indique quel est le terminal actuellement en cours d'utilisation. L'implûˋmentation actuelle n'utilise qu'un seul terminal, mais ce pointeur devient indispensable dans l'hypothû´se oû¿ plusieurs terminaux existent.
û sa crûˋation, un processus est rattachûˋ û la console en cours par le biais du champ termô :
|
|
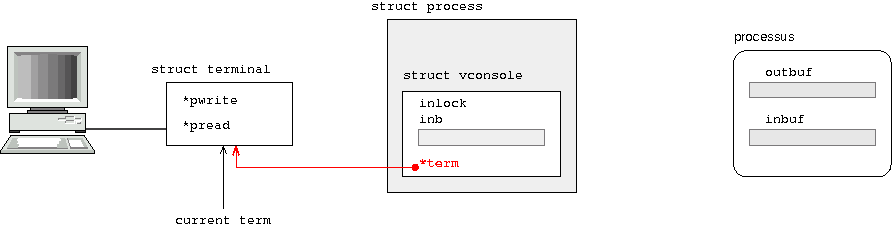
XXIV-A-2. Utiliser l'appel systû´me sys_console_read() pour entrer des donnûˋes au clavier▲
Quand un processus souhaite lire des donnûˋes entrûˋes au clavier, il invoque l'appel systû´me sys_console_read() en passant en paramû´tre l'adresse d'un buffer d'entrûˋe (inbuf dans le schûˋma ci-dessous). Si un autre processus utilise dûˋjû la console en lecture, le processus se met en attente jusqu'û ce qu'elle se libû´re. Ensuite, l'appel systû´me sys_console_read() fait pointer le champ pread de la structure du terminal sur le processus en attente de caractû´res û lireô :
/* Bloque si la console est dûˋjû utilisûˋe */
while (current_term->pread);
current->console->term->pread = current;
current->console->inlock = 1;
/* Bloque jusqu'û ce que le buffer utilisateur soit rempli */
while (current->console->inlock == 1);|
|
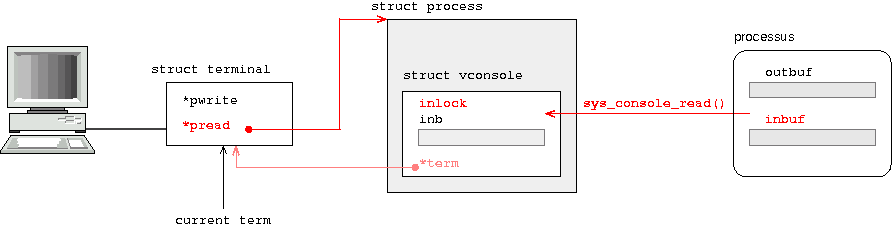
Quand une touche est pressûˋe, une IRQ est levûˋe et la fonction isr_kbd_int() est activûˋe. Cette fonction lit le code ûˋmis par le clavier. Si le code correspond û la saisie d'un caractû´re, la fonction putc_console() est appelûˋe.
En mode buffer (le mode le plus gûˋnûˋral), putc_console() affiche le caractû´re û l'ûˋcran et l'ajoute dans le buffer de la console, console->inb, du processus en lectureô :
|
|
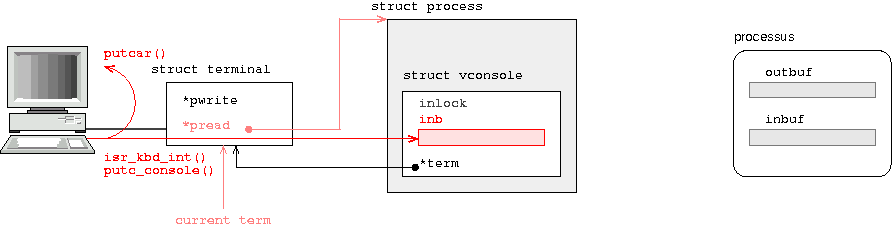
Une fois que le caractû´re \n est saisi, le processus est dûˋtachûˋ de la console et pread prend la valeur NULL. C'est seulement dans un deuxiû´me temps que le contenu du buffer inb est copiûˋ dans le buffer d'entrûˋe de l'espace utilisateur du processusô :
/* Bloque jusqu'û ce que le buffer utilisateur soit rempli */
while (current->console->inlock == 1);
strcpy(u_buf, current->console->inb);
return strlen(u_buf);Pourquoi ne copions-nous pas directement le caractû´re dans le buffer inbuf du processus en attente de lectureô ? Quand un caractû´re est saisi, une interruption est levûˋe et interrompt le processus en cours qui n'est pas forcûˋment le processus en lecture. Pour copier le caractû´re dans le tampon inbuf du processus en lecture, il faudrait alors changer d'espace d'adressage, copier le caractû´re, puis revenir dans l'espace d'adressage du processus courant. J'ai prûˋfûˋrûˋ l'autre solution qui est de copier le caractû´re dans un buffer intermûˋdiaire situûˋ directement dans la structure struct console, donc dans l'espace du noyauô :
|
|
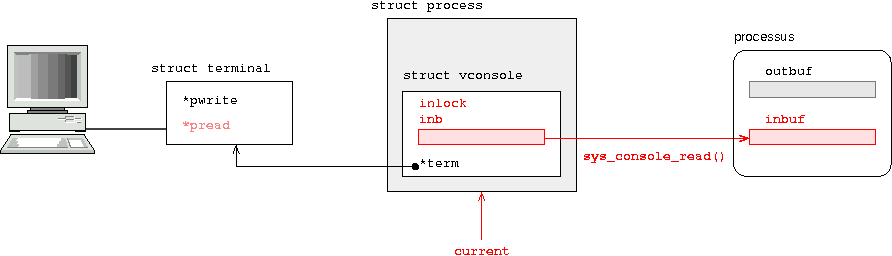
Le code de l'appel systû´me sys_console_read()ô : syscalls/sys_console_read.c
Le code de la fonction putc_console()ô : console.c
XXIV-B. Crûˋer un nouveau processus▲
L'appel systû´me sys_exec() (syscalls/sys_exec.c) permet de crûˋer et d'exûˋcuter un nouveau processus. C'est un appel systû´me trû´s simple quiô :
- Vûˋrifie que le nom du fichier exûˋcutable passûˋ en argument correspond bien û un fichierô ;
- Appelle la fonction load_task()
XXIV-B-1. Passer des arguments û un programme▲
La fonction load_task() a ûˋtûˋ modifiûˋe pour permettre le passage d'arguments du processus parent au processus enfant. La fonction principale main() prend ses arguments sur la pile (comme d'ailleurs toute fonction). Y placer ces arguments pour les rendre disponibles au nouveau processus ne pose pas de difficultûˋ particuliû´re. Mais oû¿ copier les chaûÛnes de caractû´res û passer en paramû´treô ? Une solution est de les copier û un extrûˆme de l'espace d'adressage afin de ne pas gûˆner le dûˋveloppement de la pile ou du heap. Deux emplacements semblent alors possiblesô : soit avant le heap utilisateur, soit au sommet de la pile. Cette derniû´re solution, standard sous Unix, est celle que nous avons implûˋmentûˋeô :
|
|
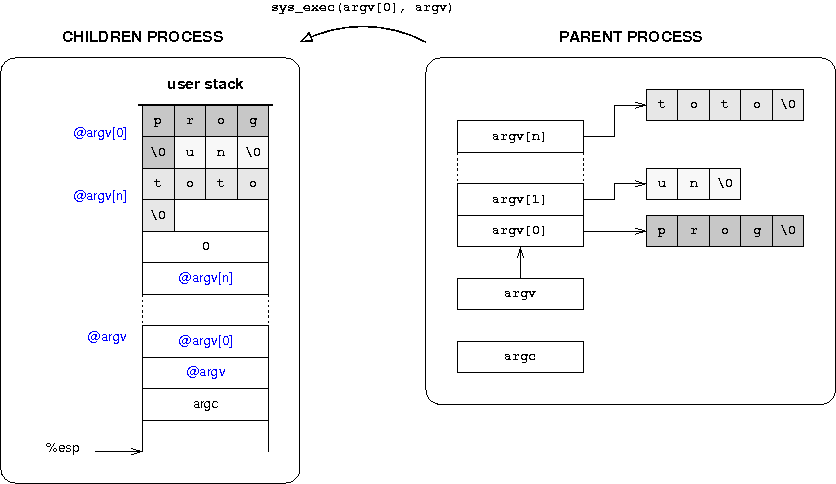
Le code qui copie les donnûˋes d'espace utilisateur û espace utilisateur (ici du processus parent au processus enfant) comporte une subtilitûˋô ! û un moment donnûˋ, on ne peut accûˋder qu'û un seul espace. Il faut donc faire transiter ces donnûˋes par l'espace du noyau, qui est commun. La copie se fait donc en deux temps. La crûˋation du nouveau processus se fait ensuite comme û l'accoutumûˋe.
XXIV-C. Allouer dynamiquement de la mûˋmoire û un processus avec malloc()▲
L'implûˋmentation de malloc() repose sur l'appel systû´me sys_sbrk()ô : syscalls/sys_sbrk.c
Cet appel systû´me trû´s simple ne fait que mettre û jour le pointeur qui pointe sur le sommet du heap. Mais oû¿ commence le heapô ? La fonction load_elf(), qui charge l'exûˋcutable, a ûˋtûˋ modifiûˋe pour mettre û jour les pointeurs sur le dûˋbut et la fin des zones de code et de donnûˋes. û partir de ces valeurs, la fonction load_task() peut ûˋvaluer la base du heap. L'utilisation de la mûˋmoire virtuelle par le processus correspond alors au schûˋma suivantô :
|
|
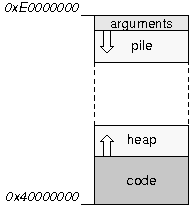
L'implûˋmentation des fonctions malloc() et free() repose sur les mûˆmes principes que pour les fonctions kmalloc() et kfree() du noyau. Attention au fait qu'il s'agit lû d'une implûˋmentation trû´s simple pour gûˋrer des blocs de mûˋmoire au niveau de l'espace utilisateurô !
XXIV-D. Le noyau et un premier shell▲
Les sources du shell sont dans Shell/userland. Le rûˋpertoire contient ûˋgalement les sources d'une minibibliothû´que de fonctions et les sources de la commande cat qui permet d'afficher le contenu d'un fichier.
|
|
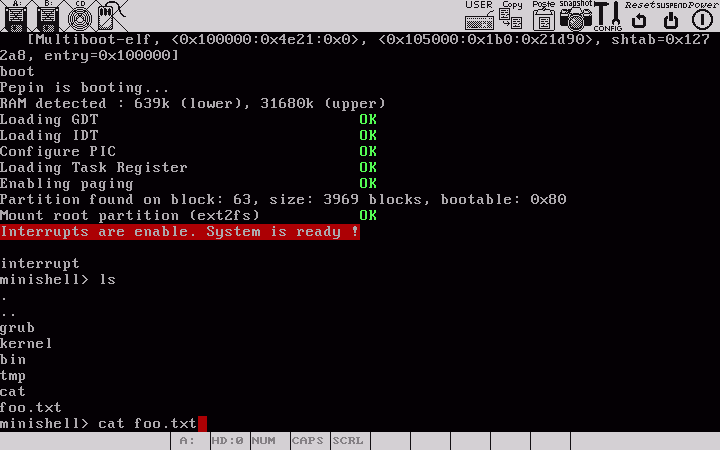
XXV. Implûˋmenter les signaux▲
- Un simple problû´me d'affichage, consûˋquences en termes d'architectureUn simple problû´me d'affichage, consûˋquences en termes d'architecture
- Implûˋmenter la filiation entre processusImplûˋmenter la filiation entre processus
- Attendre la fin d'un processus avec l'appel systû´me sys_wait()Attendre la fin d'un processus avec l'appel systû´me sys_wait()
- Implûˋmenter les signauxImplûˋmenter les signaux
Les sourcesô
Le package contenant les sources est tûˋlûˋchargeable iciô : kernel_Signals.tgz
XXV-A. Un simple problû´me d'affichage, consûˋquences en termes d'architecture▲
Un simple problû´me d'affichage
Au chapitre prûˋcûˋdent, nous avons implûˋmentûˋ un minishell et une commande cat. Bien que l'ensemble fonctionne convenablement, il y a un problû´me d'affichage, car le shell affiche directement l'invite de saisie sans attendre la fin de la commande catô :
|
|

Attendre la fin d'un processusô : l'appel sys_wait()
Nous voudrions ici que le shell attende la fin de la commande cat avant de continuer. Plusieurs solutions sont envisageables. L'appel systû´me sys_exec() pourrait par exemple bloquer en attendant la fin de la commande exûˋcutûˋe. Mais cela poserait un nouveau problû´me, car le shell bloquerait alors pour toutes les commandes lancûˋes et ûÏa n'est pas nûˋcessairement ce que nous voulons. En fait, nous voudrions que le shell bloque pour certaines commandes, comme la commande cat, mais pas pour d'autres, par exemple dans le cas du lancement d'un serveur http ou ftp. Une solution est d'implûˋmenter un nouvel appel qui permette d'attendre explicitement la fin d'un processusô : l'appel systû´me sys_wait().
Processus parent et enfant, une question de vocabulaireô ?
Un processus peut en crûˋer un nouveau grûÂce û l'appel sys_exec() puis attendre ûˋventuellement sa terminaison avec sys_wait(). Pour distinguer les deux processus, on parle communûˋment de processus parent et de processus enfant. Le processus parent qui invoque l'appel sys_wait() bloque jusqu'û la terminaison du processus fils.
Informer le processus pû´re du bon dûˋroulement grûÂce û un code de retour
La terminaison d'un processus peut ûˆtre normale ou bien consûˋcutive û une erreur. Il est souvent important pour un processus pû´re d'ûˆtre tenu informûˋ des raisons ayant conduit û la terminaison de son processus fils. Une solution est que le fils transmette un code de retour au pû´re au moment oû¿ il se termine. Mais commentô ? Nous avons dûˋjû vu que l'appel sys_exit() sert û clore proprement un processus. Cet appel va en plus positionner la valeur de retour dans un nouveau champ de la struct process, le champ status. Ensuite, et nous verrons comment, le processus pû´re va rûˋcupûˋrer cette valeur grûÂce û l'appel sys_wait(). Notez que par convention, dans le monde Unix, une valeur de retour de 0 indique un dûˋroulement normal du processus tandis que toute autre valeur signifie une erreur.
Un processus pû´re qui a plusieurs processus enfants
Jusque lû , nous avons ûˋvoquûˋ le cas d'un processus pû´re qui attend la fin de son fils. Mais pourquoi se limiter û un seul processus filsô ? Un processus devrait pouvoir lancer en parallû´le plusieurs fils. Mais cette fonctionnalitûˋ a pour consûˋquence que l'appel sys_wait() soit gûˋnûˋrique, au sens oû¿ le pû´re ne va pas attendre la terminaison d'un processus fils en particulier, mais celle de n'importe lequel de ses fils. Le processus pû´re doit donc disposer d'une liste de ses fils. La notion de filiation n'est donc plus une simple question de vocabulaireô ! Quant û l'appel sys_wait(), en plus du code de retour, il doit remonter le pid du processus fils qui s'est terminûˋô :
pid = wait(&status); /* wait remonte le pid et le code de retour */Terminaison d'un processus et ûˋtat zombie
Sous Unix, pour dire qu'un processus s'est terminûˋ, on dit qu'il est mort. Processus ô¨ô parentô ô£, processus ô¨ô enfantô ô£, ô¨ô mortô ô£ d'un processusãÎ le vocabulaire issu du systû´me Unix est trû´s imagûˋ, mais vous verrez que cela ne s'arrûˆte pas lû ô !
Un processus pû´re qui utilise sys_wait() pour attendre la fin de l'un de ses fils doit pouvoirô :
- savoir lequel de ses fils s'est terminûˋô ;
- rûˋcupûˋrer le code de retour de ce fils mort.
Le moyen qui permet cela est assez logique et simple û implûˋmenter, mais je vais avoir besoin d'un tout petit rappelô !
Jusqu'û prûˋsent, la struct process d'un processus contient un champ state qui indique son ûˋtat. La valeur 0 signifie que l'entrûˋe est libre, et il n'y a en rûˋalitûˋ plus de processus associûˋ û la structure, alors que la valeur 1 signifie que le processus est en cours d'exûˋcution ou prûˆt û ûˆtre exûˋcutûˋ. Quelle valeur associer û un processus qui vient de se terminerô ?
Quand un fils est mort, il n'est plus exûˋcutable, donc les ressources qu'il utilisait peuvent ûˆtre rendues au systû´me, û une exception prû´s. La struct process, qui contient notamment le champ status, ne peut ûˆtre libûˋrûˋe tant que le pû´re n'a pas pris connaissance de l'ûˋtat de son fils. Le fils est donc dans un ûˋtat intermûˋdiaire. Bien que mort, l'entrûˋe qu'il utilise dans la table des processus n'est pas libûˋrûˋe. On dit qu'il est û l'ûˋtat de ô¨ô zombieô ô£ô !
Pour indiquer cet ûˋtat de zombie, le champ state est mis û -1. C'est une valeur pratique dans le sens oû¿ les processus exûˋcutables ont leur champ state avec une valeur supûˋrieure û 0 et les processus non exûˋcutables une valeur infûˋrieure ou ûˋgale.
Avertir un processus d'un ûˋvûˋnement û l'aide d'un signal
Un processus pû´re possû´de la liste de ses fils et il peut donc savoir lesquels sont û l'ûˋtat de zombie grûÂce au champ state de leur struct process. Il ne serait cependant pas efficient pour le pû´re de scruter continuellement l'ûˋtat de ses fils pour savoir lesquels sont morts. Nous avons donc besoin d'un systû´me de signalisation. Dans Pûˋpin, le champ signal de la struct process est utilisûˋ pour signaler un ûˋvûˋnement au processus en question. Ce champ est vûˋrifiûˋ par l'ordonnanceur au moment oû¿ le processus est prûˋemptûˋ. Au cas oû¿ un signal a ûˋtûˋ envoyûˋ, le comportement du processus est adaptûˋ en consûˋquence. Notez que l'utilisation de signaux pour avertir un processus de la mort de l'un de ses fils n'est pas la seule utilisation possible d'un systû´me de signalisationô ! Dans Pûˋpin, le champ signal contient plusieurs bits et û chaque bit correspond un signal particulier liûˋ û un ûˋvûˋnement particulier.
Cycle de vie et mort d'un processus
Le scûˋnario de vie d'un processus est donc le suivantô :
- Un processus pû´re, û l'aide de l'appel systû´me sys_exec(), crûˋe un processus filsô ;
- Le fils s'exûˋcuteô ;
- Quand le fils se termine, il appelle sys_exit() grûÂce auquel il rend ses ressources au systû´me, dûˋpose un code de retour dans le champ status de son entrûˋe de la table des processus, et devient un zombieô ;
- Un signal est envoyûˋ au processus pû´re pour le prûˋvenir que l'un de ses enfants est mortô ;
- Le pû´re scrute la liste de ses enfants, repû´re le zombie, recueille son code de retour, le libû´re en mettant son champ state û 0 puis il l'enlû´ve de sa liste de processus enfantsô ;
- Aprû´s que le pû´re a rûˋcupûˋrûˋ le pid et le code de retour, l'appel sys_wait() retourne.
Une routine personnalisûˋe pour rûˋagir û un signalô : l'appel sys_sigaction()
Le problû´me de cette architecture est que si le pû´re n'attend pas son fils via l'appel sys_wait(), le fils restera indûˋfiniment un zombie. Cela pose un problû´me, car les zombies utilisent des entrûˋes dans la table des processus au risque de provoquer une pûˋnurie. Il faut donc que le pû´re utilise l'appel sys_wait(). Mais le pû´re peut avoir autre chose û faire que d'attendre la terminaison de son fils. Comment rûˋsoudre ce problû´meô ?
Nous avons ûˋvoquûˋ le fait qu'un signal puisse ûˆtre envoyûˋ û un processus pour le prûˋvenir d'un ûˋvûˋnement particulier, par exemple la mort d'un enfant. û ce moment, nous aimerions bien que le pû´re invoque d'une faûÏon ou d'une autre l'appel sys_wait() afin de libûˋrer son fils de son ûˋtat de zombie. Il suffit pour le pû´re, û la rûˋception du signal indiquant la mort de l'un de ses enfants, d'exûˋcuter une routine personnalisûˋe contenant l'appel û sys_wait(). Cette solution, standard dans le monde Unix, est implûˋmentûˋe au moyen d'un nouvel appel systû´meô : sys_sigaction().
Mort d'un processus pû´re
Deux problû´mes se posent quand un processus pû´re meurtô :
- le premier est de savoir qui dûˋsormais va s'occuper de ses enfantsô !
- le second concerne le premier processus, qui par dûˋfinition n'a pas de parents et donc aucun processus pour le libûˋrer.
La solution imaginûˋe pour Pûˋpin est de crûˋer un premier processus permanent, qui ne meurt jamais et qui adopte les processus orphelins.
XXV-B. Implûˋmenter la filiation entre processus▲
XXV-B-1. De nouveaux champs dans la struct process▲
Les champs suivants sont ajoutûˋs û la struct processô :
- le champ parent pointe sur le processus parentô ;
- le champ child pointe sur la liste chaûÛnûˋe des processus enfantsô ;
- le champ sibling pointe sur les processus frû´res.
struct process *parent; ô ô ô ô /* Processus parent */
struct list_head child; ô ô ô ô /* Processus enfants */
struct list_head sibling; ô ô ô /* Processus conjoints */XXV-B-2. û la crûˋation du processus▲
Ces nouveaux champs sont initialisûˋs lors de la crûˋation du processus par la fonction load_task(). Dans tous les extraits suivants, la variable previous pointe sur le processus parent. Le code suivant attribue un parent au nouveau processusô :
/* Pointe sur le processus parent (ou le pid 0 si le parent est mort) */
if (previous->state != 0)
ô ô ô ô p_list[pid].parent = previous;
else
ô ô ô ô p_list[pid].parent = &p_list[0];
Initialisation de la liste des enfants. Au dûˋpart, cette liste est vide :
/* Initialise la liste des enfants du nouveau processus */
INIT_LIST_HEAD(&p_list[pid].child);
Mise û jour de la liste des enfants du parent :
/* Ajoute le nouveau processus dans la liste des enfants du parent */
if (previous->state != 0)
ô ô ô ô list_add(&p_list[pid].sibling, &previous->child);
else
ô ô ô ô list_add(&p_list[pid].sibling, &p_list[0].child);XXV-B-3. û la mort du processus▲
Quand le processus se termine, l'appel systû´me sys_exit() reporte l'information auprû´s du pû´re et des enfants. En ce qui concerne le pû´re, la mise û jour se fait indirectement (nous verrons plus loin comment), par l'envoi d'un signal de terminaisonô :
/* Met û jour la liste des processus du pû´re */
if (current->parent->state > 0)
ô ô ô ô set_signal(¤t->parent->signal, SIGCHLD);
else
ô ô ô ô printk("WARNING: sys_exit(): process %d without valid parent\n", current->pid);
Les enfants du processus qui se termine se voient attribuer un nouveau pû´re :
/* Donne un nouveau pû´re aux enfants */
list_for_each_safe(p, n, ¤t->child) {
ô ô ô ô proc = list_entry(p, struct process, sibling);
ô ô ô ô proc->parent = &p_list[0];
ô ô ô ô list_del(p);
ô ô ô ô list_add(p, &p_list[0].child);
}XXV-C. Attendre la fin d'un processus avec l'appel systû´me sys_wait()▲
Il s'agit d'un appel trû´s simple qui bloque le processus jusqu'û ce que l'un de ses enfants soit mortô :
Algorithme : sys_wait
Paramû´tre : code de retour &status
Retour : pid
Dûˋbut
Tant qu'aucun signal SIGCHILD n'est reûÏu alors
le processus ne fait rien
Pour chaque processus enfant
Si l'enfant est û l'ûˋtat zombie alors
Le pid est rûˋcupûˋrûˋ
Le code de retour est rûˋcupûˋrûˋ
Le fils est libûˋrûˋ
Le fils est enlevûˋ de la liste des processus fils
Le signal SIGCHILD est supprimûˋ
La fonction retourne
FinXXV-D. Implûˋmenter les signaux▲
û la base de l'implûˋmentation des signaux, deux champs ont ûˋtûˋ ajoutûˋs dans la struct process. Le champ signal, sur 32 bits, est destinûˋ û recevoir les signaux. Un signal est reûÏu quand un bit est mis û 1. Le tableau sigfn pointe sur les routines de service û activer lors de la rûˋception d'un signalô :
u32 signal;
void* sigfn[32];Le fichier signal.h dûˋfinit les signaux ainsi que les routines de service par dûˋfaut.
#define SIGHUPô ô ô ô ô ô 1
#define SIGINTô ô ô ô ô ô 2
#define SIGQUITô ô ô ô ô ô 3
#define SIGBUSô ô ô ô ô ô 7
#define SIGKILLô ô ô ô ô ô 9
#define SIGUSR1ô ô ô ô ô 10
#define SIGSEGVô ô ô ô ô 11
#define SIGUSR2ô ô ô ô ô 12
#define SIGPIPEô ô ô ô ô 13
#define SIGALRMô ô ô ô ô 14
#define SIGTERMô ô ô ô ô 15
#define SIGCHLDô ô ô ô ô 17
#define SIGCONTô ô ô ô ô 18
#define SIGSTOPô ô ô ô ô 19
#define SIG_DFLô ô ô ô ô 0ô ô ô ô /* default signal handling */
#define SIG_IGNô ô ô ô ô 1ô ô ô ô /* ignore signal */
#define set_signal(mask, sig)ô ô *(mask) |= ((u32) 1 << (sig - 1))
#define clear_signal(mask, sig)ô *(mask) &= ~((u32) 1 << (sig - 1))
#define is_signal(mask, sig)ô ô (mask & ((u32) 1 << (sig - 1)))
int dequeue_signal(int);
int handle_signal(int);XXV-D-1. Traiter les signaux▲
Au moment oû¿ un processus est prûˋemptûˋ pour ûˆtre exûˋcutûˋ, l'ordonnanceur vûˋrifie si celui-ci a reûÏu un signal pour le traiterô :
/* Traite les signaux */
if ((sig = dequeue_signal(current->signal)))
ô ô ô ô handle_signal(sig);La fonction dequeue_signal() indique quel est le plus bas signal reûÏu (en partant de 0 jusqu'û 31). Si un signal est reûÏu, la fonction handle_signal() le traite. Ces deux fonctions sont dûˋfinies dans le fichier signal.c.
XXV-D-1-a. Modifier l'algorithme de l'ordonnanceur▲
La fonction handle_signal(), bien que possûˋdant un algorithme simple, est l'une des plus complexes du noyau en raison des difficultûˋs d'implûˋmentation de la gestion des routines personnalisûˋesô :
Algorithme : handle_signal
Paramû´tre : signal
Dûˋbut
Si la routine de service associûˋe au signal est de type ignorer (SIG_IGN) alors
le signal est effacûˋ
Sinon si la routine de service associûˋe au signal est de type default (SIG_DFL) alors
Si le signal est SIGHUP, SIGINT ou SIGQUIT alors
le processus se termine avec l'appel û sys_exit()
Sinon si le signal est SIGCHLD (mort d'un enfant) alors
on ne fait rien (l'appel û sys_wait() par le pû´re se chargera du travail !)
Sinon le signal est effacûˋ
Sinon on exûˋcute la fonction associûˋe au signal et dûˋterminûˋe par l'utilisateur
FinXXV-D-2. Utiliser une fonction de traitement de signal personnalisûˋe ▲
XXV-D-2-a. Associer une fonction personnalisûˋe avec l'appel sys_sigaction()▲
L'appel systû´me sys_sigaction() permet d'associer û un signal l'adresse d'une fonction utilisateurô :
asm(" mov %?x, %0 ô \n \
ô ô ô mov %?x, %1"
ô ô ô : "=m"(sig), "=m"(fn) :);
current->sigfn[sig] = fn;XXV-D-2-b. Exûˋcuter une fonction personnalisûˋe - le problû´me posûˋ▲
û la rûˋception d'un signal, la mûˋthode pour exûˋcuter une fonction personnalisûˋe est simpleô : il suffit de modifier le pointeur d'instruction %eip en le faisant pointer sur la fonction. Mais cela pose un premier problû´me, car û l'issue de l'exûˋcution de la fonction, le processus doit reprendre lû oû¿ il en ûˋtait et il faut donc sauvegarder quelque part la valeur originelle de %eip stockûˋe dans current->regs->eip. Le second problû´me provient du fait que quand le processus est interrompu par l'ordonnanceur alors qu'il exûˋcute cette fonction, les registres de la struct process sont ûˋcrasûˋs. ûa n'est donc pas uniquement la valeur de %eip qu'il faut sauvegarder, mais bien l'ensemble des registres.
XXV-D-2-c. Sauvegarder le contexte sur la pile utilisateur▲
Une fois la fonction de traitement du signal terminûˋe, le processus doit reprendre son fonctionnement normal. Malheureusement, la sauvegarde des registres dans la struct process a ûˋtûˋ ûˋcrasûˋe lors de l'exûˋcution de la fonction de traitement du signal. Avant d'exûˋcuter cette fonction, il faut donc sauvegarder les registres quelque part. Une solution standard est de sauvegarder les registres de la struct process sur la pile utilisateur. Une fois la fonction de traitement du signal terminûˋe, les registres de la struct process seront restaurûˋs grûÂce û l'appel systû´me sys_sigreturn().
Cette solution rûˋsout-elle tous les problû´mesô ? Non, car pour rester standard, l'appel û sys_sigreturn() ne doit pas ûˆtre rûˋalisûˋ explicitement dans la fonction utilisateur, mais automatiquement par le noyau.
XXV-D-2-d. Revenir d'une routine avec la technique du stack-smashing▲
Quand une fonction personnalisûˋe se termine, elle fait comme n'importe quelle fonctionô : elle rûˋcupû´re sur la pile l'adresse eip qui indique oû¿ reprendre l'exûˋcution. On peut donc penser qu'il suffit de mettre û cet endroit de la pile l'adresse de sys_sigreturn() pour exûˋcuter automatiquement cette fonction. C'est correctô ? Eh bien nonô ! N'oubliez pas que la fonction personnalisûˋe de traitement du signal s'exûˋcute en mode utilisateur alors que la fonction sys_sigreturn() est dans l'espace d'adressage du noyau, il faut donc passer par un appel systû´me.
L'appel permettant d'appeler la fonction sys_sigreturn() est le suivantô :
mov eax, 14
int 0x30Au retour de la routine de service, il faudrait que %eip pointe sur ce code et qu'en plus, celui-ci soit dans l'espace utilisateur. Une mûˋthode est de copier directement le code assembleur de cet appel sur la pile utilisateurô :
esp[19] = 0x0030CD00;
esp[18] = 0x00000EB8;La valeur de %eip est alors dûˋfinie sur la pile parô :
esp[0] = (u32) &esp[18];Ainsi, par cette implûˋmentation, au retour de la fonction de traitement personnalisûˋe, le registre %eip pointe sur l'adresse &esp[18] oû¿ est le code assembleur exûˋcutant l'appel systû´me pour sys_sigreturn().
XXV-D-2-e. Revenir avec sys_sigreturn()▲
La fonction sys_sigreturn(), qui est dûˋfinie dans le fichier syscalls/sys_sigreturn.c, ne fait que rûˋtablir les registres dans la struct process û partir de la sauvegarde effectuûˋe sur la pile.
XXVI. Annexe Aô :ô Compilation sûˋparûˋe en assembleur sous Unix▲
XXVI-A. Le programme principal▲
Le fichier suivant contient le code principal. Il incrûˋmente la variable mavar avec la fonction incr dûˋfinie dans un autre fichier. Cette fonction externe doit ûˆtre dûˋclarûˋe au dûˋbut du fichier avec la directive extern.
Le linker a besoin qu'un point d'entrûˋe soit dûˋfini pour dûˋterminer oû¿ dûˋbute le programme. Par dûˋfaut, ce point d'entrûˋe correspond au label _start et il doit ûˆtre dûˋclarûˋ de faûÏon globale (sans quoi il ne serait pas vu par le linker)ô :
extern incr
global _start
_start:
ô ô push dword mavar
ô ô call incr
mavar: dw 0x01XXVI-B. La fonction▲
La fonction incr incrûˋmente un entier sur 4 octets passûˋs en argument (passage par pointeur). Pour que cette fonction soit visible au linkage, on la dûˋclare au dûˋbut du fichier grûÂce û la directive globalô :
global incr
incr:
ô ô push eax ô ; sauvegarde du registre
ô ô push ebx ô ; sauvegarde du registre
ô ô push ebp
ô ô mov ebp, esp
ô ô mov ebx, [ebp+16] ; copie de l'adresse de la variable
ô ô mov eax, [ebx] ô ô ; copie de la valeur
ô ô add eax, 1 ô ô ô ô ; incrûˋmentation la valeur
ô ô mov [ebx], eax ô ô ; modification de la variable pointûˋe
ô ô mov esp, ebp
ô ô pop ebp
ô ô pop ebx
ô ô pop eax
ô ô retXXVI-B-1. Compilation et ûˋdition de liens▲
On produit û partir de chaque fichier source un fichier objet au format ELF grûÂce û la commande suivanteô :
nasm -f elf incr.asm -o incr.o
nasm -f elf main.asm -o main.oL'ûˋdition de liens est faite avec la commande ld. L'argument --oformat binary permet d'obtenir un binaire purô :
ld --oformat binary -Ttext 0 main.o incr.oEn dûˋsassemblant le binaire a.out obtenu, on voit trû´s clairement l'assemblage des deux fichiers objets en un seulô :
ndisasm -u a.out
00000000 680A000000 push dword 0xa
00000005 E806000000 call dword 0x10
0000000A 0100 add [eax],eax
0000000C 90 nop
0000000D 90 nop
0000000E 90 nop
0000000F 90 nop
00000010 50 push eax
00000011 53 push ebx
00000012 55 push ebp
00000013 89E5 mov ebp,esp
00000015 8B5D08 mov ebx,[ebp+0x8]
00000018 8B03 mov eax,[ebx]
0000001A 0501000000 add eax,0x1
0000001F 8903 mov [ebx],eax
00000021 89EC mov esp,ebp
00000023 5D pop ebp
00000024 5B pop ebx
00000025 58 pop eax
00000026 C3 retXXVI-C. Crûˋation d'exûˋcutables sous Unix▲
XXVI-C-1. Un programme principal en assembleur▲
extern ô printf
global ô main
main:
ô ô push eax
ô ô push dword msg
ô ô call printf
ô ô pop eax
ô ô pop eax
ô ô ret
msg db "Hello world", 13, 10, 0Ce programme est l'ûˋquivalent deô :
#include <stdio.h>
void main()
{
ô ô printf("Hello world\n");
}On le compile de la faûÏon suivanteô :
nasm -f elf main.asm -o main.o
gcc main.oXXVI-C-2. Un programme principal en C et une fonction en assembleur▲
XXVI-C-2-a. Le programme principal▲
#include <stdio.h>
extern void incr(int*);
void main()
{
ô ô int a = 1;
ô ô incr(&a);
ô ô printf("%d\n", a);
ô ô return;
}XXVI-C-2-b. Compilation et linkage▲
Pour compiler le fichier principal et le lier au fichier objetô :
gcc main.c incr.oXXVII. Annexe B - arithmûˋtique en base 16▲
XXVII-A. Conversion entre bases▲
|
Hexa |
Dûˋcimal |
Puissance de 2 |
Commentaire |
|
0xA |
10 |
||
|
0xB |
11 |
||
|
0xC |
12 |
||
|
0xD |
13 |
||
|
0xE |
14 |
||
|
0xF |
15 |
||
|
0x10 |
16 |
24 |
|
|
0xFF |
255 |
||
|
0x100 |
256 |
28 |
|
|
0x400 |
1024 |
210 |
1k |
|
0x800 |
2048 |
211 |
2k |
|
0x1000 |
4096 |
212 |
4k |
|
0x10.000 |
65.536 |
216 |
64k |
|
0x100.000 |
1.048.576 |
220 |
1Mo |
|
0x1000.000 |
16.777.216 |
224 |
16 Mo |
|
0x40.000.000 |
1.073.741.824 |
230 |
1G |
|
0x80.000.000 |
2.147.483.648 |
231 |
2G |
|
0xC0.000.000 |
3.221.225.472 |
3G |
|
|
0x100.000.000 |
4.294.967.296 |
232 |
4G |
û retenirô :
- 0x8 est la moitiûˋ de 0x10
- 0xn * 0x10 = 0xn0 (par exemple 0xEF * 0x10 = 0xEF0)
XXVIII. Annexe C - Bochs en mode debug▲
Sous Linux, Bochs doit avoir ûˋtûˋ compilûˋ avec l'option --enable-debugger pour ûˆtre utilisûˋ en mode debug.
XXVIII-A. Commandes utiles▲
- h - show list of debugger commands
XXVIII-A-1. Gûˋnûˋral▲
- n - execute instruction stepping over subroutines
- s [count] - execute #count instructions (default is one instruction)
- b <addr> - set a physical address instruction breakpoint
- c - continue executing
- r - list of CPU registers and their contents
- info sregs - show segment registers
- info eflags - show decoded EFLAGS register
- xp xp /nuf <addr> - examine memory at physical address
- print-stack [num_words] - print the num_words top 16 bit words on the stack
XXVIII-A-1-a. Segments, interruptions, gestion de tûÂches▲
- info gdt - show global descriptor table
- info idt - show interrupt descriptor table
- info tss - show current task state segment
XXVIII-A-1-b. Pagination▲
- info tab - show page tables
- page <addr> - calc physical address
- info creg - show CR0-CR4 registers
- lb <addr> - set a linear address instruction breakpoint
- x /nuf <addr> - examine memory at linear address
- info dirty - show physical pages dirtied (written to) since last display
XXIX. Annexe D - Gûˋrer les arguments sur la pile avec les Stack Frame▲
Avant que la pile soit utilisûˋe, le pointeur de pile pointe sur la case mûˋmoire juste avant le dûˋbut de la pileô :
|
|
Pour passer des paramû´tres û une fonction, plusieurs mûˋthodes sont possiblesô :
- utiliser les registres, mais cela limite le nombre de paramû´tres qu'on peut passerô ;
- empiler les paramû´tres sur la pile avec l'instruction push.
L'instruction call permet ensuite d'appeler une fonction. Le processeur empile automatiquement le registre eip et ûˋventuellement le registre cs afin de pouvoir poursuivre l'exûˋcution du code principal une fois la fonction terminûˋeô :
|
|
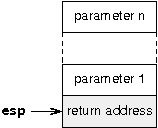
Une fois dans la fonction, pour accûˋder aux paramû´tres passûˋs en argument, il est possible de se baser sur la valeur du pointeur de pile esp. Mais cela pose un problû´me, car la fonction peut ûˆtre amenûˋe û empiler des donnûˋes, et la valeur de esp. Une solution simple est d'utiliser un registre dûˋdiûˋô : le registre ebp.
La premiû´re instruction de la fonction va donc ûˆtre de sauvegarder le registre ebp en l'empilant puis de placer dans ebp la valeur courante du pointeur de pileô :
pushl ?p
movl %esp, ?p|
|
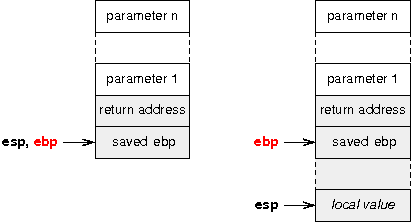
Si une autre fonction est appelûˋe, toutes les informations sont conservûˋes sur la pileô :
|
|
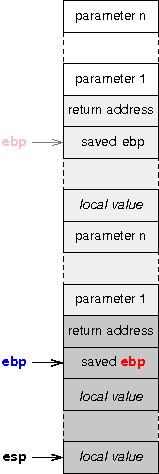
XXX. Annexe E - Dûˋboguer le noyau avec gdb▲
Un noyau lancûˋ avec Bochs ou qemu peut ûˆtre dûˋboguûˋ trû´s simplement avec gdb, et ce, sans manipulation trû´s difficile. Cette annexe ne dûˋtaille pas les commandes de gdb, mais rûˋsume seulement la manipulation permettant son utilisation.
XXX-A. Compiler avec l'option -g▲
Au prûˋalable, comme pour tout binaire gûˋnûˋrûˋ par gcc destinûˋ û ûˆtre dûˋboguûˋ par gdb, le noyau doit avoir ûˋtûˋ compilûˋ avec l'option -g.
XXX-B. Lancer l'ûˋmulateur▲
Il est possible d'utiliser Bochs, mais il devra au prûˋalable avoir ûˋtûˋ compilûˋ avec l'option --enable-gdb-stub. û noter que cette option n'est pas compatible avec l'option --enable-debugger qui permet le mode debug. Cela nûˋcessite donc d'avoir deux binaires Bochs (avec par exemple un suffixe diffûˋrent)ô : un pour le mode debug, un pour le mode gdb-stub.
Sinon, il est possible d'utiliser qemu. La commande suivante lance l'ûˋmulateur en lui prûˋcisant d'attendre une connexion avec gdb pour dûˋmarrer le CPUô :
qemu -hda c.img -s -S &XXX-C. utiliser gdb▲
Le dûˋbogueur a besoin des sources pour ûˆtre vraiment effectif. Une mûˋthode simple est de le lancer directement û partir du rûˋpertoire contenant les sourcesô :
cd kern/
gdbEnsuite, il faut indiquer le port rûˋseau fournissant les donnûˋes û gdb. Par dûˋfaut, Qemu utilise le port 1234ô :
> target remote localhost:1234Il faut fournir en entrûˋe un fichier contenant la table des symboles. Le noyau compilûˋ avec l'option -g fait l'affaireô :
> symbol-file kernelVoilû ô ! Il est maintenant possible de dûˋboguer le noyau avec gdb comme s'il s'agissait d'un simple exûˋcutable. On peut par exemple positionner un breakpoint (point d'arrûˆt) au dûˋbut de la fonction principale et continuer l'exûˋcution de l'ûˋmulateurô :
> b kmain
> cXXX-D. Annexe F - Booter avec Grub2▲
Contrairement û Grub, Grub2 nûˋcessite une partition (on ne peut utiliser le volume disque ô¨ô brutô ô£).
Pour crûˋer une image de disque avec bximageô :
bximage
> hd
> flat
> 10
> c.imgPour spûˋcifier les caractûˋristiques physiques du disque (C/H/S) et crûˋer une partitionô :
fdisk c.img
> x
> c 20
> h 16
> s 63
> r
> n, p, 1
> a 1
> wIl faut ensuite associer le disque et la partition avec les loopback afin de pouvoir les manipuler. L'offset (paramû´tre -o) en octets est obtenu en multipliant le numûˋro du secteur oû¿ dûˋbute la partition par 512. L'exemple ci-dessous illustre le cas oû¿ il y a 2 partitions avec une premiû´re, de 5 Mo, qui dûˋbute au secteur 63ô :
losetup /dev/loop0 c.img
losetup -o 32256 --sizelimit 5644800 /dev/loop1 c.img
losetup -o 5677056 /dev/loop2 c.imgOn crûˋe un systû´me de fichiers ext2 sur la premiû´re partition puis on la monteô :
mke2fs -O ^resize_inode /dev/loop1
mount -t ext2 /dev/loop1 /mnt/virtualL'option -O ^resize_inode permet de simplifier la structure du systû´me de fichiers en refusant certaines ûˋvolutions.
Ensuite, on installe Grub2. Il faut commencer par dûˋcrire les volumes disquesô :
mkdir -p /mnt/virtual/boot/grub
cat > /mnt/virtual/boot/grub/device.map << EOF
(hd0) /dev/loop0
(hd0,1) /dev/loop1
(hd0,2) /dev/loop2
EOFLe fichier suivant dûˋcrit comment charger le noyau. Il est possible d'utiliser le standard multiboot ou le nouveau standard multiboot2ô :
cat > /mnt/virtual/boot/grub/grub.cfg << EOF
set default=0
set timeout=5
set root=(hd0,1)
menuentry "AdaKernel" {
multiboot /boot/kernel
boot
}
EOF
cp kern/kernel /mnt/virtual/boot
sudo grub-install --no-floppy --root-directory=/mnt/virtual \
--modules="part_msdos ext2 biosdisk configfile normal multiboot multiboot2" \
/dev/loop0Et voilû ô ô ! Grub2 est installûˋ. Suite aux mises û jour du noyau, n'oubliez pas d'utiliser la commande sync.
XXXI. GNU Free Documentation License▲
GNU Free Documentation License
Version 1.2, November 2002
Copyright (C) 2000,2001,2002 Free Software Foundation, Inc.
51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
0. PREAMBLE
The purpose of this License is to make a manual, textbook, or other functional and useful document ô¨ô freeô ô£ in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of ô¨ô copyleftô ô£, which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for freesoftware, because free software needs free documentation: a freeprogram should come with manuals providing the same freedoms that thesoftware does. But this License is not limited to software manuals;it can be used for any textual work, regardless of subject matter orwhether it is published as a printed book. We recommend this Licenseprincipally for works whose purpose is instruction or reference.
1. APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The ô¨ô Documentô ô£, below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as ô¨ô youô ô£. You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A ô¨ô Modified Versionô ô£ of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A ô¨ô Secondary Sectionô ô£ is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document's overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The ô¨ô Invariant Sectionsô ô£ are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The ô¨ô Cover Textsô ô£ are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A ô¨ô Transparentô ô£ copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not ô¨ô Transparentô ô£ is called ô¨ô Opaqueô ô£.
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The ô¨ô Title Pageô ô£ means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, ô¨ô Title Pageô ô£ means the text near the most prominent appearance of the work's title, preceding the beginning of the body of the text.
A section ô¨ô Entitled XYZô ô£ means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as ô¨ô Acknowledgementsô ô£, ô¨ô Dedicationsô ô£, ô¨ô Endorsementsô ô£, or ô¨ô Historyô ô£.) To ô¨ô Preserve the Titleô ô£ of such a section when you modify the Document means that it remains a section ô¨ô Entitled XYZô ô£ according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
2. VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
3. COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document's license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
4. MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
- Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
- List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
- State on the Title page the name of the publisher of the Modified Version, as the publisher.
- Preserve all the copyright notices of the Document.
- Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
- Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
- Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document's license notice.
- Include an unaltered copy of this License.
- Preserve the section Entitled ô¨ô Historyô ô£, Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled ô¨ô Historyô ô£ in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
- Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the ô¨ô Historyô ô£ section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
- For any section Entitled ô¨ô Acknowledgementsô ô£ or ô¨ô Dedicationsô ô£, Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
- Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
- Delete any section Entitled ô¨ô Endorsementsô ô£. Such a section may not be included in the Modified Version.
- Do not retitle any existing section to be Entitled ô¨ô Endorsementsô ô£ or to conflict in title with any Invariant Section.
- Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version's license notice. These titles must be distinct from any other section titles.
You may add a section Entitled ô¨ô Endorsementsô ô£, provided it contains nothing but endorsements of your Modified Version by various parties--for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
5. COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled ô¨ô Historyô ô£ in the various original documents, forming one section Entitled ô¨ô Historyô ô£; likewise combine any sections Entitled ô¨ô Acknowledgementsô ô£, and any sections Entitled ô¨ô Dedicationsô ô£. You must delete all sections Entitled ô¨ô Endorsementsô ô£.
6. COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
7. AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an ô¨ô aggregateô ô£ if the copyright resulting from the compilation is not used to limit the legal rights of the compilation's users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document's Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
8. TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled ô¨ô Acknowledgementsô ô£, ô¨ô Dedicationsô ô£, or ô¨ô Historyô ô£, the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
9. TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided for under this License. Any other attempt to copy, modify, sublicense or distribute the Document is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
10. FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License ô¨ô or any later versionô ô£ applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation.
ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (c) YEAR YOUR NAME.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License".
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the ãÎô¨ô withãÎTexts.ô ô£ line with this:
with the Invariant Sections being LIST THEIR TITLES, with the Front-Cover Texts being LIST, and with the Back-Cover Texts being LIST.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
XXXII. FAQô : questions souvent posûˋes▲
- Le code ne compile pasLe code ne compile pas
- Le noyau ne fonctionne pas avec mon ûˋmulateurLe noyau ne fonctionne pas avec mon ûˋmulateur
- La compilation produit l'erreur undefined reference to __stack_chk_failLa compilation produit l'erreur undefined reference to __stack_chk_fail
- Pour compiler le noyau sur une plateforme 64 bitsPour compiler le noyau sur une plateforme 64 bits
XXXII-A. Rûˋponses▲
XXXII-A-1. Le code ne compile pas▲
Tous les codes en exemple et disponibles ont ûˋtûˋ compilûˋs et testûˋs sous Linux. Si malgrûˋ tous vos efforts vous ne parvenez pas û compiler le code, vous pouvez me contacter en prûˋcisantô :
- la commande utilisûˋe pour compiler/linker avec les argumentsô ;
- le message d'erreur.
XXXII-A-2. Le noyau ne fonctionne pas avec mon ûˋmulateur▲
Tous les noyaux ont ûˋtûˋ testûˋs avec Bochs et qemu. Quel que soit votre ûˋmulateur, pensez û ô :
- regarder dans le log gûˋnûˋrûˋô ;
- vûˋrifier que le fichier de configuration de l'ûˋmulateur est correct .
Si votre problû´me est insoluble, vous pouvez me contacter en prûˋcisantô :
- la commande utilisûˋe pour compiler/linker avec les argumentsô ;
- l'ûˋmulateur utilisûˋô ;
- le contenu du fichier de logs.
XXXII-A-3. La compilation produit l'erreur undefined reference to __stack_chk_fail▲
C'est une erreur causûˋe par gcc qui, pour certaines versions, ajoute par dûˋfaut un ô¨ô canariô ô£ dans la pile utilisateur lors de chaque appel de fonction (http://en.wikipedia.org/wiki/Canary_value#Canaries). Pour dûˋsactiver ce comportement, il suffit de lui ajouter l'option -fno-stack-protector.
XXXII-A-4. Pour compiler le noyau sur une plateforme 64 bits▲
Par dûˋfaut, sur une distribution Linux 64 bits, les binaires et fichiers objets gûˋnûˋrûˋs vont ûˆtre au format 64 bits. Pour gûˋnûˋrer Pûˋpin, qui est en 32 bits, il faut rajouter certaines options û la compilation et au linkageô :
- û la compilation, il faut ajouter l'option -m32ô ;
- au linkage, il faut utiliser l'option -m elf_i386.
XXXIII. Conclusion▲
Document sourceô : Programmer son propre noyauô : une introduction avec Pûˋpin
Copyright (C) 2008, Arnauld Michelizza
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled ô¨ô GNU Free Documentation Licenseô ô£.
Cette version comme la version d'origine est sous licence GFDL
XXXIV. Note de la rûˋdaction de dûˋveloppez.com▲
Quelques ajouts ont ûˋtûˋ effectuûˋs notamment par rapport aux processeurs 64 bits.
La version originale de l'article est disponible ici.
Nous tenons û remercier Christophe pour la mise au gabarit et Claude Leloup pour la relecture orthographique.